This is the multi-page printable view of this section. Click here to print.
Incidents
Security incident: Redis cache exposed to public internet
Background
Between July 9 and July 16, 2023, one of Hachyderm’s Redis cache servers was exposed to the public internet. On July 16, 2023, the Hachyderm Infrastructure team identified a misconfiguration of our firewall on the cache server which allowed access to the redis interface from the public Internet. After a routine system update, the nftables firewall service was not brought up automatically after a restart, which exposed the Redis cache to the internet for a period of seven days.
During the exposure, an unknown third party attempted to reconfigure our Redis server to act as a replica for a Redis server they controlled. Due to this change, a read-only mode was enabled on Hachyderm Redis and no further data was written.
Normally, Hachyderm servers run nftables to block all except necessary traffic from the Internet. We leverage Tailscale for server-to-server communication and only expose ports to the Internet as needed to run Mastodon and administer the systems.
As of July 16, 2023 11:17 UTC, the Hachyderm team has corrected the configuration on our systems and blocked external actors from accessing this Redis instance. While we do not have any direct evidence the information in the cache was deliberately exfiltrated, because this was exposed to the public internet, we assume the data was compromised.
Impact
Highly sensitive information like passwords, private keys, and private posts were NOT exposed as part of this incident. No action is required from the user.
The affected Redis cache stored the following types of information with a 10 minute time-to-live before getting deleted:
- Logins using
/auth/sign_inwill cache inputted email addresses and used IP addresses for login throttling. Note that if you had a cached session during this period, no IPs or email-addresses would have been included. - Rails-generated HTML content.
- Some UI-related settings for individual users (examples being toggles for reducing motion, auto play gifs, and the selected UI font).
- Public posts rendered by Mastodon in the affected period.
- Other non-critical information like emojis, blocked IPs, status counts, and other normally public information of the instance.
We do not have sufficient monitoring to confirm precisely when the compromise occurred. We also have no confirmation if any of the above data was actually sent to a third party, but since the information was available to them, we assume the data was compromised. But since the adversary turned on read-replica mode disabling writes, and Mastodon’s cache having a time to live of 10 minutes, it would have severely limited the amount of information leaked in this period.
Timeline
| Date/Time (UTC) | Event | Phase |
|---|---|---|
| 2023-07-09 19:16 | Fritz was updated, and part of the upgrade process required a restart of the system. Nftables, our system firewall, was not reenabled across reboots on this server. Fritz acted normally throughout our monitoring period. | Before |
| Between 2023-07-10 to 2023-07-16 | The adversary adds a non-Hachyderm host as the fritz Redis write primary, causing Fritz to go into read-only mode. Sometime thereafter, Fritz’s Redis encounters a synchronization error, causing it to not synchronize further with the non-Hachyderm host. | Before |
| 2023-07-16 10:45 | Hachyderm Infra Engineer (HIE1) identifies that, when attempting to run a standard administrative task sees Mastodon logs are alerting that RedisCacheStore: write_entry failed, returned false: Redis::CommandError: READONLY You can’t write against a read only replica. | Identify |
| 2023-07-16 10:56 | After reviewing the system configuration further, HIE1 identifies that the Redis cache on fritz is targeting an unknown host IP as a write primary; overall Redis is in a degraded state. | Identify |
| 2023-07-16 11:10 | HIE1 confirms the unknown host IP is not a Hachyderm host and that nftables on fritz is not enabled as expected. | Identify |
| 2023-07-16 11:17 | HIE1 stops Redis and re-enables nftables on fritz, closing unbounded communication from the Internet. | Remediate |
| 2023-07-16 13:02 | HIE1 confirms the type of information stored in the cache, including e-mail + IP address for logins. | Investigate |
Analysis
What went well & where did we get lucky
- We got lucky that it was the caching redis server, which primarily holds Rails generated HTML content, UI related settings per user, and rack based login throttling.
- No user data outside of a subset of IP addresses and Emails from people using the login form in the compromised period were possibly shared.
- Redis had a TTL of ten (10) minutes on any data in this cache.
- Redis was put into a READONLY mode when the compromise occurred, so it is likely no data was pushed to the adversary after the timestamp of the compromise. This, coupled with the ten minute cache, caused the cache itself to empty fairly quickly.
What didn’t go well
- Process: While we have a standard process for updating Mastodon, and while our servers are version-controlled into git, they are individually unique creations, which makes it challenging to understand if a server is configured correctly because each server can be just a little different.
- System: We don’t leverage authentication or restrictive IP block binds on our Redis server, so once the firewall was down, Redis would become available on the Internet and trivial to connect to and see what data it contained.
- It took us a long time to identify the issue:
- Observability: We don’t currently have detective control to alert us if a critical configuration on a server is set correctly or not.
- Observability: Furthermore, we didn’t have any outlier detection or redis alerts set up to notify us that Redis had gone into read only mode.
- Observability: Due to how journalctl had been set up to rotate logs by size, and the explosive amount of RedisCacheStore: write_entry failed entries generated per successful page load, we quickly lost the ability to look back on our log history to see the exact date the access happened.
Corrective Actions
The Hachyderm infrastructure team is taking/will take the following actions to mitigate the impact of this incident:
| Action | Expected Date | Status |
|---|---|---|
| Enable nftables on fritz and ensure it will re-enable upon system or service restart on all systems | Jul 16, 2023 | Done |
| Perform system audit to identify potential additional compromise beyond Redis | Jul 16, 2023 | Done |
| Update system update runbooks to include validating that nftables is running as expected after restarts | Jul 17, 2023 | To Do |
| Bind Redis only to expected IP blocks for Hachyderm’s servers | Jul 17, 2023 | To Do |
| Publish full causal analysis graph and update corrective actions based on findings | Jul 21, 2023 | To Do |
| Identify tooling to keep logs for a defined time period that would not be affected by large log files. | Jul 28, 2023 | To Do |
| Identify plan to require authentication on Redis instances | Jul 28, 2023 | To Do |
| Identity mechanism for detective controls to alert if critical services are not running on servers & create plan to implement | Jul 28, 2023 | To Do |
| Explore possibility of using cloud-based firewall rules as an extra layer of protection & plan to implement | Jul 28, 2023 | To Do |
Moderation Postmortem
Hello Hachydermians! There has been a lot of confusion this week, so we’re writing up this blog post to be both a postmortem of sorts and a single source of truth. This is partly to combat some of the problems generated by hearsay: hearsay generates more Things To Respond To than Things That Actually Happened. As a result, this post is a little longer than our norm.
Moderation Incident
(A note to the broader, non-tech industry, members of our community: “Incident” here carries similar context and meaning to an “IT Incident” as we are a tech-oriented instance. Postmortems for traditional IT incidents are also in this section.)
A Short, Confusing Timeline
On 24 April 2023 the Hachyderm Moderation team received a request to review our Fundraising Policy via a GitHub Issue. The reason for the request was to ensure there was a well understood distinction between Mutual Aid and Fundraising. Although our Head Moderator responded to the thread with the constraints we use when developing new rules, some of the hearsay we started to see in the thread the user linked raised some flags that something else was happening.
In order to determine what happened, we needed to dive into various commentary before arriving at a potential root cause (and we eventually determined this was indeed the correct root cause). While a few of our moderators working on this, our founder and now-former admin Kris Nóva was requested, either directly or indirectly, to make statements on transgender genocide (she is herself openly transgender) and classism.
These issues are important, we want to be unequivocally clear. Kris Nóva is transgender and has been open about her experiences with homelessness and receiving mutual aid. The Hachyderm teams are also populated, intentionally, with a variety of marginalized individuals that bring their own lived experiences to our ability to manage Hachyderm’s moderation and infrastructure teams. That said: it was not immediately apparent that these requests were initially connected to the originating problem. In fact, it caused additional resources to be used trying to determine if there was a secondary problem to address. This resulted in a delay in actual remediation.
The Error Itself
On 27 Mar 2023 the Hachyderm Moderation Team received a report that indicated that an account may have been spamming the platform. When the posts were reviewed at the time of the report, it did trigger our spam policy. When we receive reports of accounts seeking funds, we try to validate the posts to check for common issues like phishing and so forth, as well as checking post volume and pattern to determine if the account is posting in a bot-like way, and so forth. At the time the report was moderated, the result was that the posting type and/or pattern was incorrectly flagged as spam and we requested the account stop posting that type of post. Once we became aware of the situation, the Hachyderm Moderation team followed up with our Hachydermian to ensure that they knew that they could post their requests for Mutual Aid, apologized for the error, and did our best to let them know we were here if there was anything else we could do to help them feel warm and welcome on our instance.
Lack of public statement
There have been some questions around the lack of public statement regarding the above. There are two reasons for this. First and foremost, this is because situations involving moderation are between the moderation team and the impacted person. Secondly, we must always take active steps to protect against negative consequences that can come with all the benefits of being a larger instance.
How Errors in Moderation are Handled at Hachyderm
Depending on the error, one or both of the following occurs:
- Follow up with the user to rectify the situation
- Review policy to ensure it doesn’t happen again
This is because of two enforced opinions of the Hachyderm Moderation team:
- Moderation reports filed by users are reports of harm done.
- To put it another way: if a user needs to file a report of hateful content, then they have already seen that content to report it.
- All moderation mistakes are also harm done.
For the latter, we only follow up with the user if 1) they request and/or 2) we have reason to believe it would not increase the harm done. All Hachyderm Moderator and Hachydermian interactions are centered on harm mitigation. Rectifying mistakes in moderation are about the impacted person and not ego on the part of the specific moderator who made the mistake.
To put it another way, the Hachyderm Moderation team exists to serve the Hachyderm Community. This means that we will apologize to the user as part of harm mitigation. We will not as part of “needing to have our apology accepted” or to “be seen as apologizing”. These latter two go against the ethos of Hachyderm Moderation Strategy.
Inter-instance Communication and Hachyderm
Back when we took on the Twitter Migration in Nov 2022, we started to overcommunciate with Hachydermians that we were going to start using email and GitHub Issues (in addition to moderation reports) to accommodate our team scaling. As part of the changes we made, we also started making changes to reflect this in the documentation, as well as including how other instances can reach out to us if needed. It was our own pattern that if we needed to reach out to another instance, we used the email address they listed on their instance page. This is because we didn’t want to assume “the name on the instance” was “the” person to talk to. There are likely other instances like ours that have multiple people involved. This is reinforced by the fact that the “name” is actually populated by default by the person who originally installed the software on the server(s).
That said, we recently made a connection with someone who has grown their instance in the Fediverse for quite some time and has been helping to make us aware of the pre-existing cultural and communication norms in this space. In the same way it was natural for us to check for the existence of instance documentation to find their preferred way to communicate, it was unnatural for some of the existing instances to do so. Instead, it seems there are pre-existing cultural norms in the space we weren’t aware of, the impact of this is that some instances knew how to reach us and others did not.
We have been taking feedback from the person we connected with so that we can balance the needs of the existing communication patterns and norms of the Fediverse, while not accidentally creating a situation where a communication method ends up either too silo’ed or not appropriately visible due to our team structures.
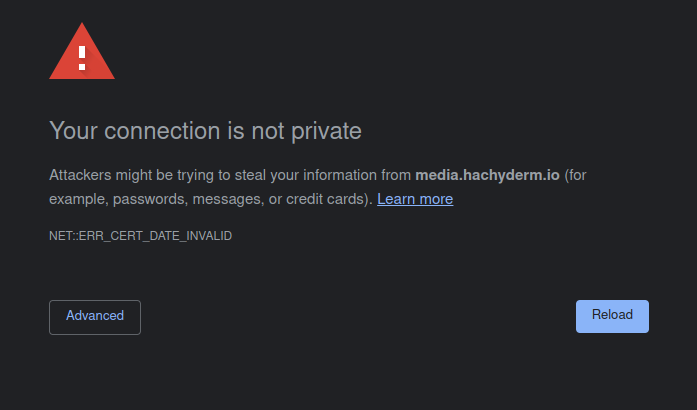
TLS Expires: media.hachyderm.io
On February 28th, 2023 at approximately 01:55 UTC Hachyderm experienced a service degradation in which images failed to load in production.
We were able to quickly identify the root cause as expired TLS certificates in production for media.hachyderm.io
Context
Hachyderm TLS certificates are still managed manually, and are very clearly out of sprawling out of control due to our rapid growth. There are many certificates on various servers that have had config copied from one server to another as we grew into our current architecture.
The alert notification was missed, and the media.hachyderm.io TLS privkey.pem and fullchain.pem material expired causing the service degradation.
Timeline
- Feb 28th 01:52
@quintessenceFirst report of media outages - Feb 28th 01:54
@novaConfirms media is broken from remote proxy in EU - Feb 28th 01:56
@novaAppoints@quintessenceas incident commander - Feb 28th 01:57
@novaConfirms TLS expired onmedia.hachyderm.io - Feb 28th 02:30
@novaLive streaming fixing TLS
Shortly after starting the stream we discovered that the Acme challenge was not working because the media.hachyderm.io DNS record was pointed to CNAME hachyderm.io and the proxy was not configured to manage the request. In the past we have worked around this by editing the CDN on the East coast which is where the Acme challenge will resolve.
In this case we changed the media.hachyderm.io DNS record to point to A <ip-of-fritz> which is where the core web server was running.
We re-ran the renew process and it worked!
sudo -E certbot renew
We then re-pointed media.hachyderm.io back to CNAME hachyderm.io.
Next came the scp command to move the new cert material out to the various CDN nodes and restart nginx.
# Copy TLS from fritz -> CDN host
scp /etc/letsencrypt/archive/media.hachyderm.io/* root@<host>:/etc/letsencrypt/archive/media.hachyderm.io/
# Access root on the CDN host
ssh root@<host>
# Private key (on CDN host)
rm -f /etc/letsencrypt/live/media.hachyderm.io/privkey.pem
ln -s /etc/letsencrypt/archive/media.hachyderm.io/privkey3.pem /etc/letsencrypt/live/media.hachyderm.io/privkey.pem
# Fullchain (on CDN host)
rm -f /etc/letsencrypt/live/media.hachyderm.io/fullchain.pem
ln -s /etc/letsencrypt/archive/media.hachyderm.io/fullchain3.pem /etc/letsencrypt/live/media.hachyderm.io/fullchain.pem
The full list of CDN hosts:
- cdn-frankfurt-1
- cdn-fremont-1
- sally
- esme
Restarting nginx on each of the CDN hosts was able to fix the problem.
# On a CDN host
nginx -t # Test the config
systemctl reload nginx # Reload the service
# On your local machine
emacs /etc/hosts # Point "hachyderm.io" and "media.hachyderm.io" to IP of CDN host
# Check your browser for working images
Impact
- Full image outage across the site in all regions.
- A stressful situation interrupting dinner and impacting the family.
- Even more chaos and confusion with certificate material.
Lessons Learned
- We still have outstanding legacy certificate management problems.
Things that went well
- We had a quick report, and the mean time to resolution was <60 mins.
Things that went poorly
- The certs are in an even more chaotic state.
- There was no alerting that the images broke.
- There was a high stress situation that impacting our personal lives.
Where we got lucky
- I still had access to the servers, and was able to remedy the situation from existing knowledge.
Action items
- We need to destroy the vast majority of nginx configurations and domains in production
- We need to destroy all TLS certs and re-create them with a cohesive strategy
- We need a better way to perform the Acme challenge that doesn’t involve changing DNS around the globe
- Nóva to send list of domains to discord to destroy
Fritz Timeouts
On January 7th, 2023 at approximately 22:26 UTC Hachyderm experienced a spike in HTTP response times as well as a spike in 504 Timeouts across the CDN.
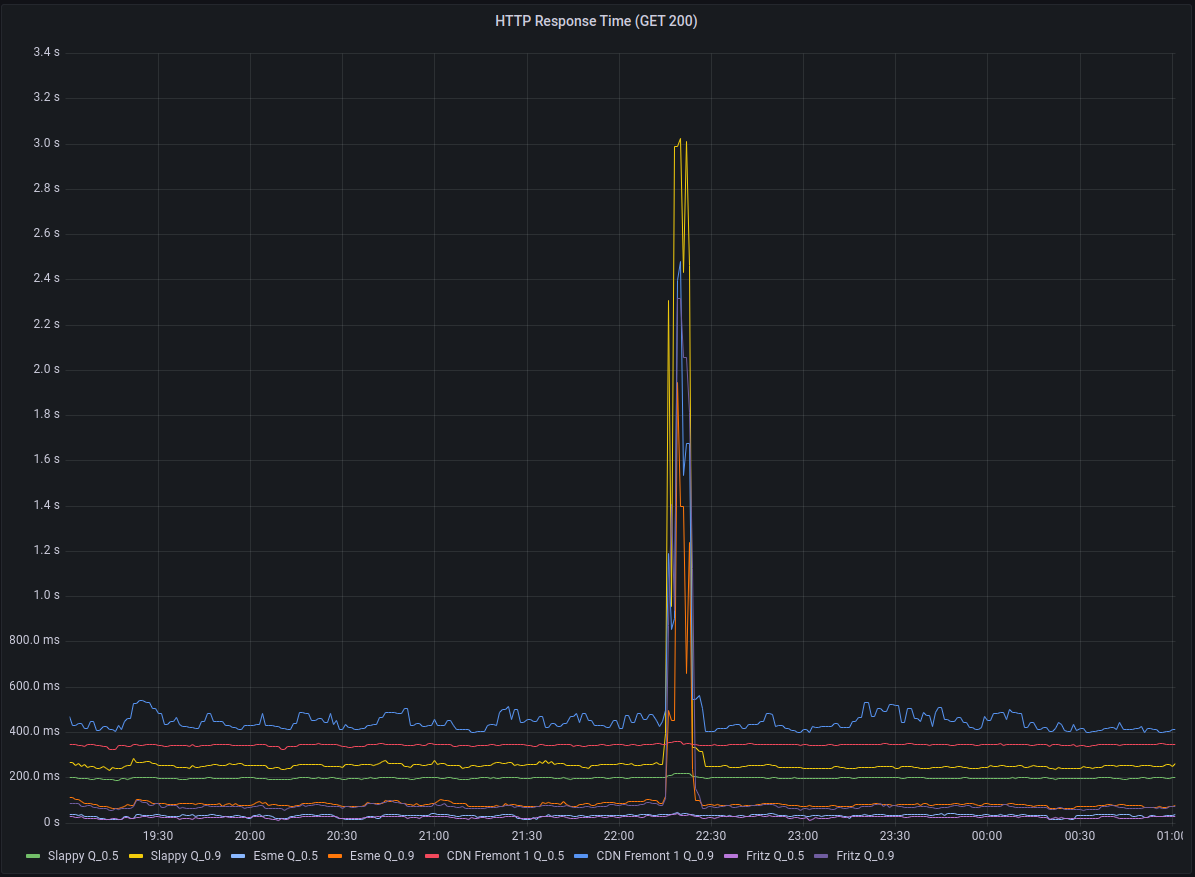
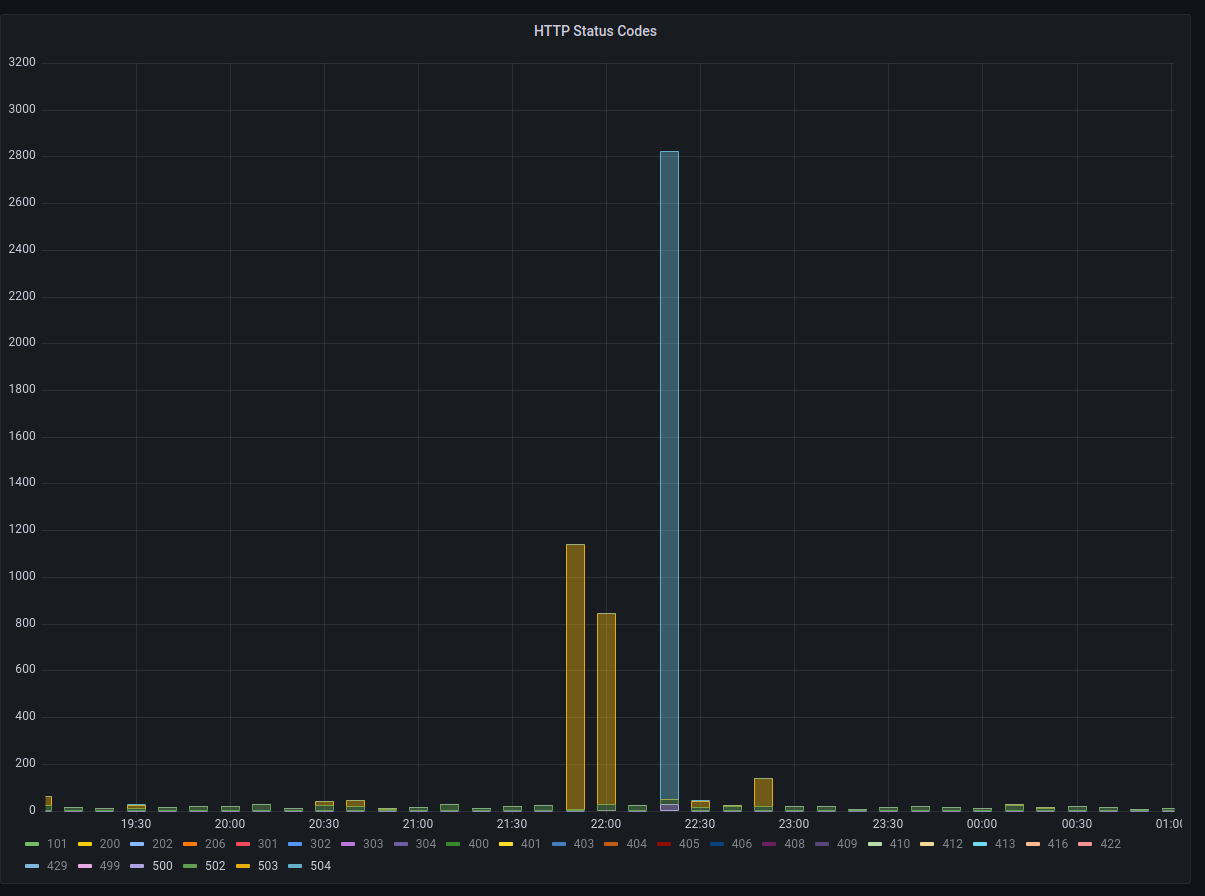
Working backwards from the CDN to fritz we discovered another cascading failure.
Context
There is a fleet of CDN nodes around the world, commonly referred to as “POP” servers (Point of Presence) or even just “The CDN”. These servers reverse proxy over dedicated connections back to our core infrastructure.
These CDN servers served content timeouts at roughly 22:20:00 UTC.
These CDN servers depend on the mastodon-streaming service to offer websocket connections.
Impact
- Total streaming server outage reported in Discord (Uptime Robot)
- Slow/Timeouts reported by users in Twitch chat
- Nóva noticed slow/timeouts on her phone
HTTP Response Times measured > 3s
Background
We received some valuable insight from @ThisIsMissEm who has experience with both node.js websocket servers and the mastodon codebase, which can be read here in HackMD.
An important takeaway from this knowledge is that the mastodon-streaming service and the mastodon-web service will not rate limit if they are communicating over localhost.
In other words, you should be scheduling mastodon-streaming on the same node you are running mastodon-web.
We believe that the way the streaming API works, that if there is a “large event” such as having a post go out by a largely followed account it can cause a cascading effect on everyone connected via the streaming API.
A good metric to track would actually be the percentage of connections that a single write is going to. If the mastodon server has one highly followed user, a post by them, especially in a “busy” timezone for the instance, will result in unbalanced write behaviours, where one message posted will result in iterating over a heap more connections than others (one per follower who’s connected to streaming), so you can end up doing 40,000 network writes very easily, locking up node.js temporarily from processing disconnections correctly.
We believe that the streaming API began to drop connections which cascaded out to the CDN nodes via the mastodon-web service.
We can correlate this theory by connecting observe logged lines to the Mastodon code bash.
Logs from mastodon-streaming on Fritz
06-4afe-a449-a42f861855b2 Tried writing to closed socket
33-414d-9143-6a5080bd6254 Tried writing to closed socket
33-414d-9143-6a5080bd6254 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
41-4385-9762-c5c1d829ba27 Tried writing to closed socket
0f-4eb4-9751-b5ac7e21c648 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
60-40d1-99b4-349f03610b36 Tried writing to closed socket
60-40d1-99b4-349f03610b36 Tried writing to closed socket
33-414d-9143-6a5080bd6254 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
Code from Mastodon main
const streamToWs = (req, ws, streamName) => (event, payload) => {
if (ws.readyState !== ws.OPEN) {
log.error(req.requestId, 'Tried writing to closed socket');
return;
}
Found in mastodon/streaming/index.js
Logs (correlation) from mastodon-web on Fritz
This is where we are suspecting that we are hitting the “Rack Attack” rate limit in the streaming service.
-4589-97ed-b67c66eb8c38] Rate limit hit (throttle): 98.114.90.221 GET /api/v1/timelines/home?since_id=109>
Working Theory (root cause)
We are maxing out the streaming service on Fritz, and it is rate limiting the mastodon web (puma) service. The “maxing out” can be described in the write-up by @ThisIsMissEm where NodeJS struggles to process/drop the connections that are potentially a result of a “Large Event”.
As the websocket count increases there is a cascading failure that starts on Fritz and works it way out to the nodes.
Eventually the code that is executing (looping) over the large amounts of websockets will “break” and there is a large release where a spike in network traffic can be observed.
We see an enormous (relatively) amount of events occur during the second of 22:17:30 on Fritz which we suspect is the “release” of the execution path.
As the streaming service recovers, the rest of Hachyderm slowly stabilizes.
Lessons Learned
Websockets are a big deal, and will likely be the next area of our service we need to start observing.
We will need to start monitoring the relationship between the streaming service and the main mastodon web service pretty closely.
Things that went well
We found some great help on Twitch, and we ended up discovering an unrelated (but potentially disastrous) problem with Nietzsche (the main database server).
We have a path forward for debugging the streaming issues.
Things that went poorly
Nóva was short on Twitch again and struggles to deal with a lot of “noise/distractions” while she is debugging production.
In general there isn’t much more we can do operationally other than keep a closer eye on things. The code base is gonna’ do what the code base is gonna’ do until we decide to fork it or wait for improvements from the community.
Where we got lucky
Seriously the Nietzsche discovery was huge, and had nothing to do with the streaming “hiccups”. We got extremely lucky here.
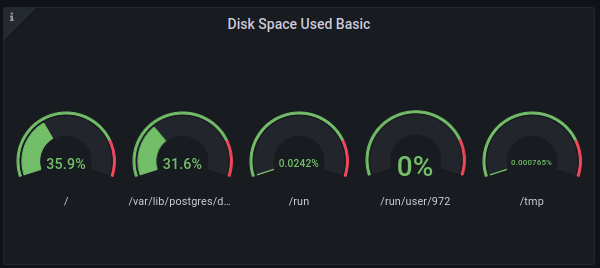
Consequently, Nóva fixed the problem on Nietzsche which was that our main database NVMe disk was at 98% capacity.
- We did NOT receive storage alerts in Discord (I believe we should have?)
- Nóva could NOT find an existing cron job on the server to clean the archive.
- Nóva scheduled the cron job (Using
sudo crontab -e)
The directory (archive) that was full:
/var/lib/postgres/data/archive
Nietzsche is now back down to ~30%
Action items
1) Set up websocket observability on CDN nodes (clients) and Fritz (server)
We want to see how many “writes” we have on the client side and how many socket connections they are mapped to if possible. We might need to PR a log entry for this to the Mastodon code base.
2) Verify cron is running on Nietzsche
We need to make sure the cron is running and the archive is emptying
3) Debug why we didn’t receive Nietzsche alerts
I think we should have seen these, but I am not sure?
4) We likely need a bigger “Fritz”
Sounds like we need donations and a bigger server (it will be hard to move streaming off of the same machine as web).
Fritz on the fritz
On January 3th, 2023 at approximately 12:30 UTC Hachyderm experienced a spike in
response times. This appeared to be due to a certificate that had not been
renewed on fritz, which runs the Mastodon Puma and Streaming services. The
service appeared to recover until approximately 15:00 UTC when another spike in
response times was observed.
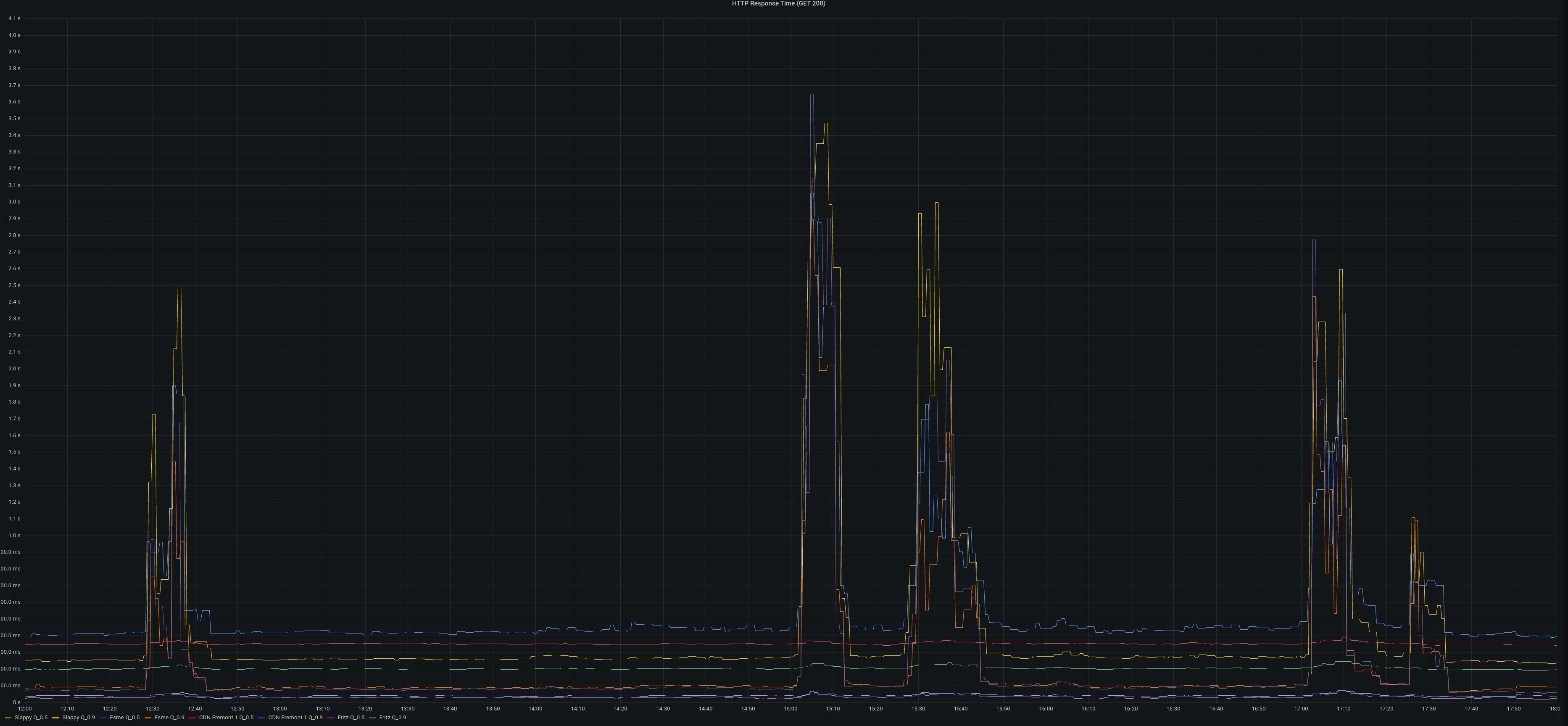
Alerts were firing in discord alerting us to the issue.
Background
fritz runs mastodon-web and mastodon-streaming and all other web nodes proxy
to fritz.
mastodon-web was configured with 16 processes each having 20 threads.
mastodon-streaming was configured with 16 processes
Impact
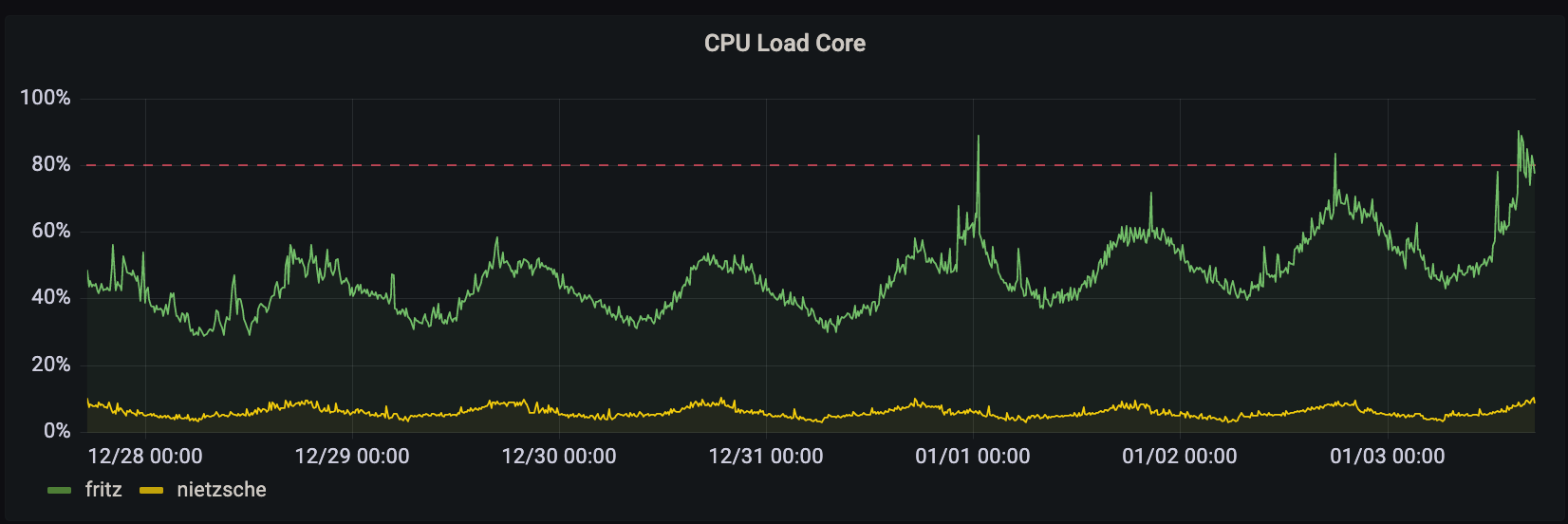
p90 response times grew from ~400ms to >2s. increase of 502 responses to >1000 per minute.
Root causes and trigger
organic growth in users and traffic coupled with the return from vacation of
the US caused the streaming and puma processes on fritz to use more CPU. CPU
load hit >90% consistently on fritz. this in turn caused responses to fail to
be returned to the upstream web frontends.
Lessons Learned
response times are very sensitive to puma threads (reducing from 20 to 16 threads per process doubled GET response times).
the site functions well with fewer streaming processes.
Things that went well
we had the core CPU load on the public dashboard.
Things that went poorly
in an attempt to get things under control both mastodon-streaming and mastodon-web were changed. puma was then reverted as we had over-corrected and response times were getting quite bad.
no CPU load alerts were configured for fritz specifically.
Where we got lucky
@dma was already keyed in to fritz thanks to an earlier issue where
certs hadn’t been renewed.
Action items
1) Streaming processes reduces @dma [repair]
Reduced the number of streaming processes on fritz from 16 to 12.
2) Better alerting on CPU load @dma [detect]
We should implement better CPU load alerting on every host to detect these issues and be able to respond even more quickly.
3) Postmortem documented @dma
This blog post and a hackmd postmortem doc.
The Queues ☃️ down in Queueville
Every Queue down in Queueville liked ActivityPub a lot. But John Mastodon who lived just north of Queuville, did not! John Mastodon hated ActivityPub, the whole Activity season! Now please don’t ask why. No one quite knows the reason.
It could be, perhaps, that his WEB_CONCURRENCY was too tight.
It could be his MAX_THREADS wasn’t screwed on just right.
But I think that the most likely reason of all
May have been that his CPU was two sizes too small.
But, whatever the reason, his WEB_CONCURRENCY or CPUs,
He stood there on Activity Eve hating the Queues…
Staring down from his cave with systemd hacks
At the warm buzzing servers below in their racks
For he knew every Queue down in Queueville beneath Was busy now hanging an Activity-Wreath. “And they’re posting their statuses,” he snarled with a sneer. “Tomorrow is Activity-Mas! It’s practically here!”
Then he growled, with John Mastodon fingers nervously drumming, “I must find some way to keep the statuses from coming”!
For, tomorrow, I know all the Queues and the “they"s and the “them"s Will wake bright and early for ActivitySeason to begin!
And then! Oh, the noise! Oh, the noise! Noise! Noise! Noise! There’s one thing John Mastodon hates: All the NOISE! NOISE! NOISE! NOISE!
And they’ll shriek squeaks and squeals, racing ‘round on their hosts. They’ll update with jingtinglers tied onto their posts! They’ll toot their floofloovers. They’ll tag their tartookas. They’ll share their whohoopers. They’ll follow their #caturday-ookas. They’ll spin their #hashtags. They’ll boost their slooslunkas. They’ll defederate their blumbloopas. But complain about their whowonkas.
And they’ll play noisy games like post a cat on #caturday, An ActivityPub type of all the queers and the gays! And then they’ll make ear-splitting noises galooks On their great big postgres whocarnio ruby monolith flooks!
Then the Queues, young and old, will sit down to a feast. And they’ll feast! And they’ll feast! And they’ll FEAST! FEAST! FEAST! FEAST!

They’ll feast on Queue-pudding, and rare Queue-roast-beast, Ingress Queue roast beast is a feast I can’t stand in the least!
And then they’ll do something I hate most of all! Every Queue down in Queueville, the tall and the small,
They’ll stand close together, with UptimeRobot bells ringing. They’ll stand hand-in-hand, and those Queues will start singing!
And they’ll sing! And they’ll sing! And they’d SING! SING! SING! SING! And the more John Mastodon thought of this Queue Activity Sing, The more John Mastodon thought, “I must stop this whole thing!”
Why for fifty-three days I’ve put up with it now! I must stop ActivityPub from coming! But how?
Timeline
All events are documented in UTC time.
- 13:00
@dmaNoticed the ingress queue was backing up - 16:45
@quintessenceNoticed the ingress queue was still lagging - 17:00
@novaDeclared an incident - 17:30
@hazelweaklyNoticed CPU at 100% on Freud and Franz - 17:34
@hazelweaklyWorked with@dmato rebalance queues across Freud, Franz, and Nietzsche - 17:37
@dmaNotices CPU on Nietzsche is not changing - 17:45
@hazelweaklyChanges 5MAX_THREADSto 20MAX_THREADSon Nietzsche
ActivityEve
“I know just what to do!” John Mastodon laughed in his throat. “I’ll max out the CPU, and cause the network to bloat.”
And he chuckled, and clucked, “What a great John Mastodon trick! With this CPU and network lag, I’ll cause the latency to stick!”
“All I need is a denial of service.” John Mastodon looked around. But since denial of services are scarce, there was none to be found.
Did that stop John Mastodon? Hah! John Mastodon simply said, “If I can’t find a denial of service, I’ll make one instead!”
So he took his dog MAX, and he took some more EMPTY_THREADS.
And he tied big WEB_CONCURRENCY on top of his head.
Then he loaded some cores and some old empty racks.
On a ramshackle sleigh and he whistled for MAX.
Then John Mastodon said “Giddyap!” and the sleigh started down Toward the homes where the Queues lay a-snooze in their town.
All their graphs were dark. No one knew he was there. All the Queues were all dreaming sweet dreams without care. When he came to the first little house of the square.
“This is stop number one,” John Mastodon hissed, As he climbed up load average, empty cores in his fist.
Then he slid down the ingress, a rather tight bond. But if a denial of service could do it, then so could John Mastodon.
The queues drained only once, for a minute or two. Then he stuck his posts out in front of the ingress queue!
Where the little Queue messages hung all in a row. “These messages,” he grinched, “are the first things to go!”
Then he slithered and slunk, with a smile most unpleasant, Around the whole server, and he took every message!
Cat pics, and updates, artwork, and birdsite plea’s! Holiday cheer, Hanukkah, Kwanza and holiday trees!
And he stuffed them in memory. John Mastodon very nimbly, Stuffed all the posts, one by one, up the chimney.
Then he slunk to the default queues. He took the queues’ feast! He took the queue pudding! He took the roast beast!
He cleaned out that /inbox as quick as a flash.
Why, John Mastodon even took the last can of queue hash!
Then he stuffed all the queues up the chimney with glee. “Now,” grinned John Mastodon, “I will stuff up the whole process tree!”
As John Mastodon took the process tree, as he started to shove, He heard a small sound like the coo of a dove…
He turned around fast, and he saw a small Queue! Little Cindy-Lou Queue, who was no more than two.
She stared at John Mastodon and said, “our statuses, why? Why are you filling our queues? Why?”
But, you know, John Mastodon was so smart and so slick, He thought up a lie, and he thought it up quick!
“Why, my sweet little tot,” John Mastodon lied,
“There’s a status on this /inbox that won’t light on one side.
So I’m taking it home to my workshop, my dear. I’ll fix it up there, then I’ll bring it back here.”
And his fib fooled the child. Then he patted her head, And he got her a drink, and he sent her to bed.
And when Cindy-Lou Queue was in bed with her cup, He crupt to the chimney and stuffed the ingress queues up!
Then he went up the chimney himself, the old liar.
And the last thing he took was /var/log for their fire.
On their .bash_history he left nothing but hooks and some wire.
And the one speck of content that he left in the house Was a crumb that was even too small for a mouse.
Then he did the same thing to the other Queues’ houses, Leaving crumbs much too small for the other Queues’ mouses!
Timeline
All events are documented in UTC time.
- 17:58
@dmaNotices we are no longer bottlenecked on Ingress after@hazelweaklymakes changes - 18:03
@dmaProvides update on priority of systemd flags - 18:10
@dmaProvides spreadsheet for us to calculate connections to database
ActivityMorn
It was quarter of dawn. All the Queues still a-bed, All the Queues still a-snooze, when he packed up his sled,
Packed it up with their statuses, their posts, their wrappings, Their posts and their hashtags, their trendings and trappings!
Ten thousand feet up, up the side of Mount Crumpet, He rode with his load average to the tiptop to dump it!
“Pooh-pooh to the Queues!” he was John Msatodon humming. “They’re finding out now that no ActivityPub messages are coming!
They’re just waking up! I know just what they’ll do! Their mouths will hang open a minute or two Then the Queues down in Queueville will all cry boo-hoo!
That’s a noise,” grinned John Mastodon, “that I simply must hear!” He paused, and John Mastodon put a hand to his ear.
And he did hear a sound rising over the snow. It started in low, then it started to grow.
But this sound wasn’t sad! Why, this sound sounded glad!
Every Queue down in Queueville, the tall and the small, Was singing without any ActivityPub messages at all!
He hadn’t stopped ActivityPub messages from coming! They came! Somehow or other, they came just the same!
And John Mastodon, with his feet ice-cold in the snow, Stood puzzling and puzzling. “How could it be so?”
Posts came without #hashtags! It came without tags! It came without content warnings or bags!
He puzzled and puzzled till his puzzler was sore. Then John Mastodon thought of something he hadn’t before.
Maybe ActivityPub, he thought, doesn’t come from a database store. Maybe ActivityPub, perhaps, means a little bit more!
And what happened then? Well, in Queueville they say That John Mastodon’s small heart grew three sizes that day!
And then the true meaning of ActivityPub came through, And John Mastodon found the strength of ten John Mastodon’s, plus two!
And now that his heart didn’t feel quite so tight, He whizzed with his load average through the bright morning light!
With a smile to his soul, he descended Mount Crumpet Cheerily blowing “Queue! Queue!” aloud on his trumpet.
He road into Queuville. He brought back their joys. He brought back their #caturday images to the Queue girls and boys!
He brought back their status and their pictures and tags, Brought back their posts, their content and #hashtags.
He brought everything back, all the CPU for the feast! And he, he himself, John Mastodon carved the roast beast!
Welcome ActivityPub. Bring your cheer, Cheer to all Queues, far and near.
ActivityDay is in our grasp So long as we have friends’ statuses to grasp.
ActivityDay will always be Just as long as we have we.
Welcome ActivityPub while we stand Heart to heart and hand in hand.
Timeline
All events are documented in UTC time.
- 18:10
@hazelweaklyProvides update that queues are now balancing and load is coming down - 18:18
@novaConfirms queues are draining and systems are stabilizing
Root Cause
John Mastodon took the queue hash, and up the chimney he stuck it. The Hachyderm crew was too tired to fill out the report and said “fuck it”.
Nietzsche:
- 4 default queues (unchanged)
- 32 default ingress (changed)
Franz:
- 6 default queues (unchanged)
- 1 ingress queue (changed)
- 5 pull queues (unchanged)
- 5 push queues (unchanged)
Freud:
- 3 default queues (unchanged)
- 2 ingress queues (changed)
- 2 pull queue (changed)
- 2 push queue (changed)
Changes:
Because the database connection count per ingress queue process changed, when necessary, I will clarify queue amounts in terms of database connections.
- Moved 2 ingress queues (40 DB connections) from franz to nietzsche
- Moved 2 ingress queues (40 DB connections) from freud to nietzsche
- Changed DB_POOL on ingress queues from 20 to 5 as they're heavily CPU bound.
- Changed -c 20 on ingress queues from 20 to 5 as they're heavily CPU bound.
- Scaled Nietzsche up from 8 ingress queues to 32 to keep the amount of total database connections the same.
- Restarted the one ingress queue remaining on franz (this lowered ingress DB connections from 20 to 5).
- Restarted the two ingress queues remaining on freud (this lowered ingress DB connections from 40 to 10).
- Removed a "pushpull" systemd service on Freud and replaced it with independent push and pull sidekiq processes (neutral db connection change).
Degraded Service: Media Caching and Queue Latency
On Saturday, December 17th, 2022 at roughly 12:43 UTC Hachyderm received our first report of media failures which started a 2-day-long investigation of our systems by @hazelweakly, @quintessence, @dma, and @nova. The investigation coincidentally overlapped with a well-anticipated spike in growth which also unexpectedly degraded our systems simultaneously.
The first degradation was unplanned media failures, typically in the form of avatar and profile icons intermittently on the service. We had an increase in 4XX level responses due to misconfigured cache settings in our CDN. We believe the Western US to be the only region impacted by this degradation.
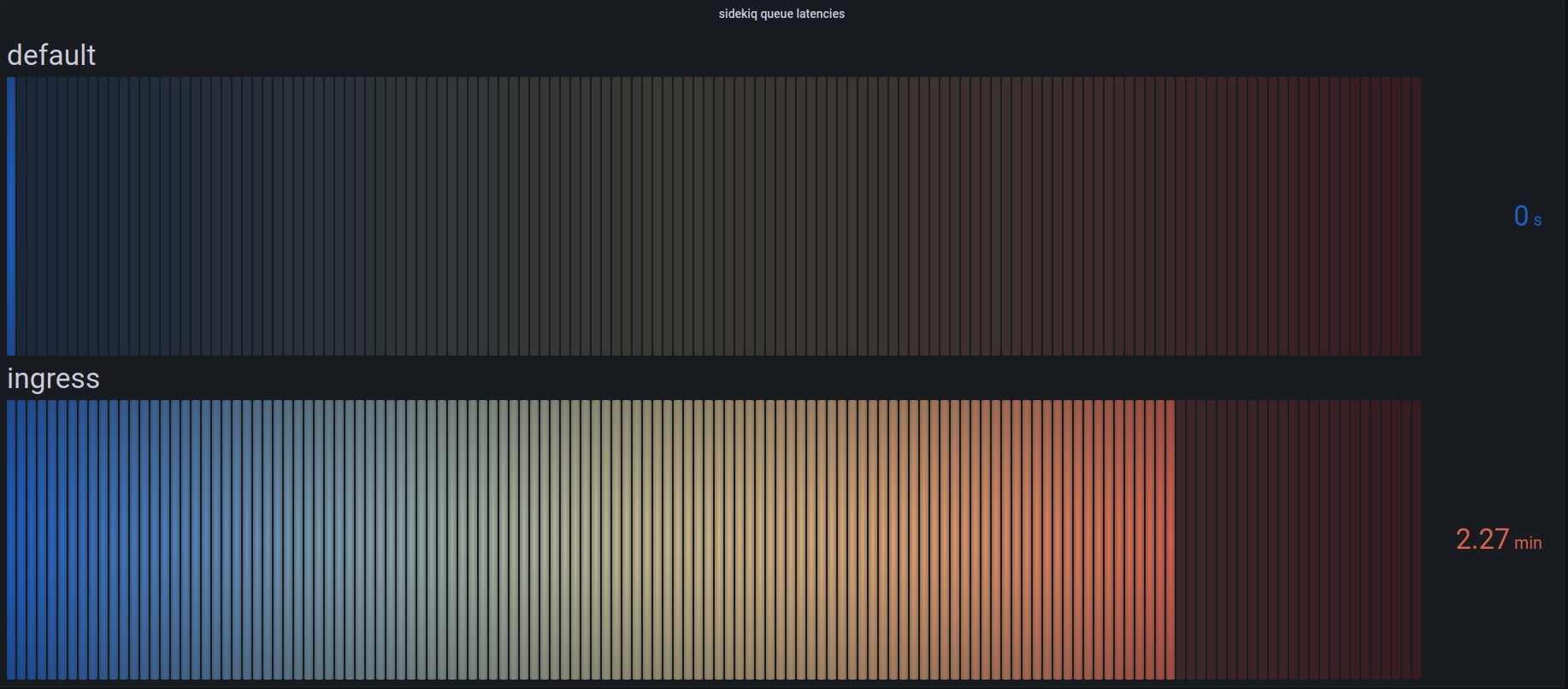
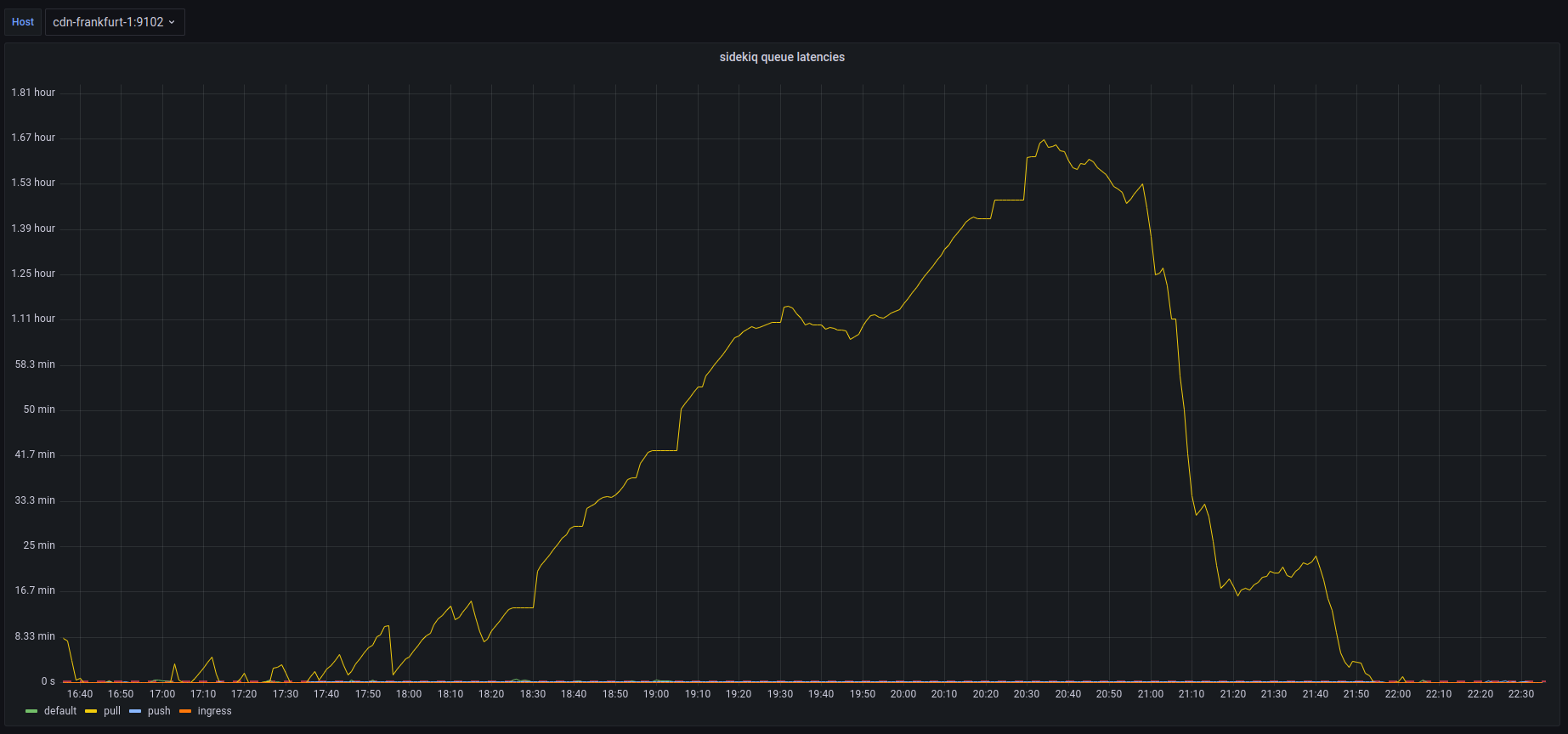
The second degradation was unplanned queue latency increasing presumably from the increase in usage due to the fallout of Twitter mass exodus. We experienced an increase in our push and pull queues, as well as a short period of default latency.
Timeline
All events are documented in UTC time.
- Dec 16th 12:43
@arjenpdevriesFirst report of media cache misses #217 - Dec 17th 08:21
@blueturtleai2nd Report, and first confirmation of media cache misses #218 - Dec 17th 21:43
@quintessence3rd Report of media cache misses - Dec 17th 21:44
@novaFalse mediation ofcmd+shift+rcache refresh - Dec 17th 22:XX More reports of cache failures, multiple Discord channels, and posts
- Dec 17th 23:XX More reports of cache failures, multiple Discord channels, and posts
- Dec 17th 24:XX Still assuming “cache problems” will just fix themselves
- Dec 18th 14:45
@dmaNginx audit andlocation{}rewrite onfritz; no results - Dec 18th 14:45
@dmaNo success debugging various CDN nodes and cache strategies - Dec 18th 15:16
@dmaCheck mastodon-web logs on CDNs; /system GETs with 404s - Dec 18th 20:32
@hazelweaklyDiscovered.env.productionmisconfiguration cdn-frankfurt-1, franz - Dec 18th 20:41
@quintessenceConfirms queues are backing up
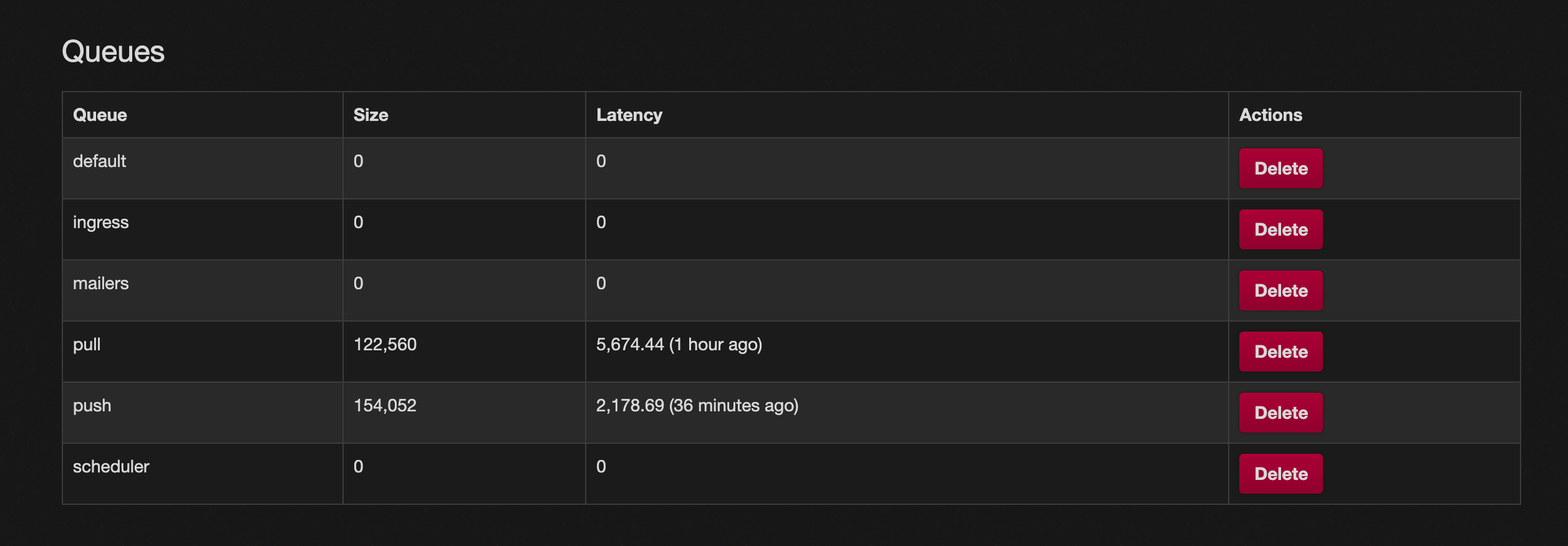

- Dec 18th 20:45
@hazelweaklyConfirms actively reloading services to drain queues - Dec 18th 21:17
@malte_jAppears from vacation, and is told to go back to relaxing - Dec 18th 21:23
@hazelweaklyContinues to “tweak and tune” the queues - Dec 18th 21:32
@hazelweaklyClaims we are growing at <1 user per minute - Dec 18th 21:45
@dmaReminder to only focus oningressanddefaultqueues - Dec 18th 21:47
@hazelweaklyIdentifies queue priority fix using systemd units - Dec 18th 21:47
@hazelweaklySuggests moving queues to CDN nodes - Dec 18th 21:59
@dmaSuggests migrating DB fromfreud->nietzsche - Dec 18th 22:15
@hazelweaklySummary confirms sidekiq running on CDNs - Dec 18th 22:18
@novaIdentifies conversation in Discord, and begins report
Root Cause
The cause of the caching 4XX responses and broken avatars was a misconfigured .env.production file on cdn-fremont-1 and franz.
S3_ENABLED=FALSE # Should be true
3_BUCKET=".." # Should be S3_BUCKET
The cause of the queue latency is suspected to be the increase in usage from Twitter, as well as the queue priority documented here in the official Mastodon scaling up documentation.
ExecStart=/usr/bin/bundle exec sidekiq -c 10 -q default
Things that went well
We have the cache media fixed, and we have been alerted to a high-risk concern early giving the team enough time to respond.
Things that went poorly
An outage was never declared for this incident, and therefore it was not handled as well as it could have been. Various members of the team were mutating production with reckless working habits
- Documenting informally in private infrastructure GitHub repository
- Discord used as documentation
- No documenting just “tinkering” alone
- Documenting after the fact
- Not using descriptive language, EG: “Tweaked the CDNs” instead of changed
on from to .
Unknown state of production after the incident. Unsure which services are running where, and who has what expectations for which services.
The configuration roll-out obviously had failed at some point, indicating a stronger need for config management on our servers.
We seemed to lose track of where the incident started and stopped and where improvements and action items began. For some reason we decided to make suggestions about next steps before we were entirely sure on the state of the systems today, and having a plan in place.
Opportunities
Config management should be a top priority.
Auditing and migrating sidekiq services off of CDN nodes should be a top priority.
Migrating the database from freud -> nietzsche should be a priority.
We shouldn’t be planning or discussing future improvements until the systems are restored to stability. Incidents are not also a venue for decision-making.
Resulting Action
1) Plan for Postgres migration
@nova and @hazelweakly planning live stream to migrate production database and clear up more compute power for sidekiq queues
2) TODO Configuration Management
We need to identify a configuration management pattern for our systems sooner than later. Perhaps an opportunity for a new volunteer.
3) TODO Discord Bot Incident Command
We need to identify ways of managing and starting and stopping incidents using Discord. Maybe in the future we can have “live operating room” incidents where folks can watch read-only during the action.
Global Outage: 504 Timeouts
On Tuesday, December 13th, 2022 at roughly 18:52 UTC Hachyderm experienced a 7 minute cascading failure that has impacted our users around the globe resulting in unresponsive HTTP(s) requests and 5XX level requests. The service has not experienced any data loss. We believe this was a total service outage.
Impacted users experienced 504 timeout responses from https://hachyderm.io in all regions of the world.
Timeline
All events are documented in UTC time.
- 18:53
@novaFirst report of slow response times in Discord - 18:55
@dmaFirst confirmation, and first report of 5XX responses globally - 18:56
@dmaCheck of Mastodon web services, no immediate concerns - 18:56
@novaCheck of CDN proxy services, no immediate concerns - 18:57
@novaFirst observed 504 timeout - 18:58
@dmastatus.hachyderm.io updated acknowledging the outage - 18:59
@novaFirst observed redis error, unable to persist to disk
Dec 13 18:59:01 fritz bundle[588687]: [2eae54f0-292d-488e-8fdd-5c35873676c0] Redis::CommandError (MISCONF Redis is configured to save RDB snapshots, but it's currently unable to persist to disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error.):
- 19:01
@UptimeRobotFirst alert received
Monitor is DOWN: hachyderm streaming
( https://hachyderm.io/api/v1/streaming/health ) - Reason: HTTP 502 - Bad Gateway
- 19:02
@novaRoot cause detected. The root filesystem is full on our primary database server.
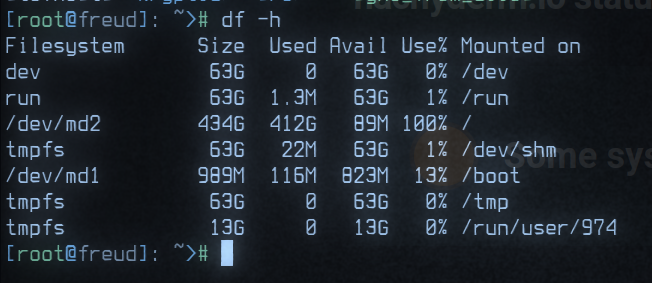
- 19:04
@novaIdentified postgres archive/var/lib/postgres/archivedata exceeds 400Gb of history - 19:05
@malte_jRequest to destroy archive - 19:06
@malte_jConfirmed archive has been destroyed - 19:06
@malte_jConfirmed 187Gb of space has been recovered - 19:06
@dmastatus.hachyderm.io updated acknowledging the root cause - 19:07
@novaBegin drafting postmortem notes - 19:16
@novaOfficial announcement posted to Hachyderm
Root Cause
Full root filesystem on primary database server resulted in a cascading failure that first impacted Redis’s ability to persist to disk which later resulted in 5XX responses on the edge.
Things that went well
We had a place to organize, and folks on standby to respond to the incident.
We were able to respond and recover in less than 10 minutes.
We were able to document and move forward in less than 60 minutes.
Things that went poorly
There was confusion about who had access to update status.hachyderm.io and this is still unclear.
There was confusion about where redis lived, and which systems where interdependent upon redis in the stack.
The Novix installer is still our largest problem and is responsible for a lot of confusion. We do not have a better way forward to manage packages and configs in production. We need to decide on Nix and our path forward as soon as possible.
Opportunities
We need to harden our credential management process, and account management. We need to have access to our systems.
We need global architecture, ideally observed from the systems themselves and not in a diagram.
When an announcement is resolved, it removes the status entirely from UptimeRobot. We can likely improve this.
Resulting Action
1) Cron cleanup scheduled @malte_j
Cron scheduled to remove postgres archive greater than 5 days.
#!/bin/bash
set -e
cd /var/lib/postgres/data/archive
find * -type f -mtime 5 -print0 | sort -z | tail -z -n 1 | xargs -r0 pg_archivecleanup /var/lib/postgres/data/archive
2) Alerts configured @dma
Alerts scheduled for >90% filesystem storage on database nodes.
Postmortem template created for future incidents.
3) Postmortem documented @nova
This blog post as well as a small discussion in Discord.