This is the multi-page printable view of this section. Click here to print.
Hachyderm Blog
- Announcements
- Pixelfed Vulnerability and Impacts to Federation
- Defederation from Threads
- Threads Update
- Crypto Spam Attacks on Fediverse
- Updating Domain Blocks
- Opening Hachyderm Registrations
- Posts
- A Minute from the Moderators
- A Minute from the Moderators
- A Minute from the Moderators
- A Minute from the Moderators
- A Minute from the Moderators
- A Minute from the Moderators
- Ensuring Hachyderm's Future: Improving Safety & Resilience through Strategic Placement of Infrastructure
- Hachyderm's Introduction to Mastodon Moderation: The Report Feature and Moderator Actions
- Hachyderm's Introduction to Mastodon Moderation: Part 1
- MastodonForHarris Hashtag and Mutual Aid Awareness Campaign
- Hachyderm and Nivenly
- The Israel-Palestine War
- A Minute from the Moderators
- A Minute from the Moderators
- A Minute from the Moderators
- Stepping Down From Hachyderm
- A Minute from the Moderators
- A Minute from the Moderators
- Decaf Ko-Fi: Launching GitHub Sponsors et al
- Growth and Sustainability
- Leaving the Basement
- Incidents
Announcements
Pixelfed Vulnerability and Impacts to Federation
A recent Pixelfed vulnerability and how it impacts Hachyderm.
If you’re an instance admin and need to reach out to us to refederate, please skip to the “For mods and admins” section (linked on the right nav menu).
Information about the vulnerability
Pixelfed v0.12.5, released 24 Mar 2025, fixes a flaw in how Follows and Followers Only posts were handled by PixelFed. Before this release, private accounts (accounts that require follower approval) could be followed without approval, and any visible post to any user on a Pixelfed instance was accessible to all users on the entire instance. This allowed unintended access to private content. This is true for all instances federating with the Pixelfed instance, not just the instance itself or other Pixelfed instances.
You can read more about this vulnerability here:
- NIST CVE-2025-30741 (Web Archive Link)
- Github Advisory
- Forkus.Cool Blog Post 25 Mar 2025 (Web Archive Link)
- Fediverse Report for 1 April 2025
Why are we talking about Pixelfed and how does this impact Hachyderm?
To restate succinctly:
This vulnerability can expose followers-only posts on all follower-only accounts for all instances using the ActivityPub protocol, regardless of what implementation they are using.
How? The short version.
Understanding the gist of the vulnerability requires understanding a couple of mechanics around followers / following and followers-only posts. For the former, when you “lock” your account or make it “private,” what you are enabling is the ability to manually approve followers. Only once you have approved the follow request is the follower approved and the follower allowed to follow you. (For public accounts approval is automatic unless the account’s instance is otherwise moderated by you or your instance.)
Another part of follow / following mechanics is a process referred to as synchronization. This is the process that makes sure your followers list stays updated. For example, if someone deletes their account, this process removes it from your follower list.
Furthermore, when you make a followers-only post, what is supposed to happen is that post should go to your followers collection only. This means notifying the instances hosting the accounts of your followers to relay that post to accounts specifically in your followers collection.
What was happening with Pixelfed versions 0.12.4 and earlier was that Pixelfed hadn’t correctly implemented account following, which means “locked” / “private” accounts can be followed by any Pixelfed user without explicit approval. This means that posts federated with Pixelfed instances that were marked as “followers-only” were being displayed to accounts that Pixelfed had allowed to follow you, but were not necessarily the followers you intended.
Since Hachyderm is a Mastodon instance, that also means that any instances running Pixelfed v0.12.4 or earlier that we federate with can expose private posts on Hachyderm to these instances, additionally, any pixelfed servers running v0.12.5 may still be exposing followers-only content until Pixelfed implements follower collection synchronization.
What about other ActivityPub implementations?
This same type of vulnerability can happen in other federated software using ActivityPub as well.
This is why you should never post sensitive or highly private content: the privacy of that content is only as strong as the least secure part of the network or software. (The software itself, the server it’s running on, and everything else it needs to run.)
For highly sensitive content, we recommend using services that support end-to-end encryption and limiting who you are sharing it with. Depending on the type of content and how you need to share it, this can include options like Signal or Matrix.
What actions we have taken
Due to the severity of the issue, we have defederated with all Pixelfed instances that are not running version 0.12.5, since versions prior to 0.12.5 allowed for followers that were not approved to access followers-only content.
In addition, since defederation is a silent action (a defederated instance doesn’t receive a notification), we have reached out to impacted instances, where their contact information was available, to explain the situation and how we can resolve and refederate.
Determining the impact
It is always important to make an informed decision when making a server-wide decision as a moderation team. This includes understanding what options are available to you and their impact.
In this case, the only real tool that prevents data exposure on this scale is defederation. All other solutions, like limiting, still allow data to be shared and thus exposed.
Since we knew we were going to need to make multiple defederations, we made sure we knew the full scope of the impact of this action. This is doubly true for this CVE, as we typically prefer to give instance admins time to react to information they receive, and, as many of us in tech know, upgrade paths are not always smooth and straightforward.
For the impact analysis, we gathered the following data:
- How many Pixelfed instances are we federating with?
- What versions of Pixelfed are those instances running?
- How much cross-pollination (followers / following) is occurring on those instances?
As a result of our analysis, we determined that the risk to Hachydermian’s private data was high and the cross-pollination on the impacted instances was very low.
The impact data
Prior to the vulnerability, Hachyderm was federating with 96 instances running Pixelfed. Due to the CVE, we have defederated with 63 of those instances.
(Since this action is due to a security vulnerability, we will refederate with instances that patch the vulnerability. Head to the mods and admins section of this post to learn more.)
A breakdown of the Pixelfed instances we are/were federating with:
- 33 are running 0.12.5 (released 24 Mar 2025)
- 46 are running 0.12.4 (released 8 Nov 2024)
- 17 are running a version earlier than 0.12.4 (0.12.3 was released 1 Jul 2024)
There isn’t a robust way to query Mastodon for how many offline instances it is still trying to federate with, so an unknown percentage of these were already offline with one or more failed retries to connect. To put it another way, it is likely that a number of instances that haven’t been updated “in a long while” were just offline and that information didn’t propagate properly. There just is not a good way to know exactly how many or which. (This is not a bug in Pixelfed, this is common for federating software.)
For the follower / following relationships:
- For 93 of all 96 Pixelfed instances, regardless of software version, there were 5 or fewer following in either direction.
- For 2 of the instances, there were between 5 and 10 following in either direction.
- pixelfed.social is the outlier and outlined in the next section
What about pixelfed.social
Since pixelfed.social is the largest instance, by far, we’re going to show a little more data. To say it first so it isn’t missed:
pixelfed.social is running v0.12.5, so we will not be defederating with pixelfed.social as part of the response to this CVE. The additional information below is only because we provided comparable information, in aggregate, for the other 95 Pixelfed instances.
Now on to the data:
- pixelfed.social is running Pixelfed v0.12.5
- There are 1073 unique Hachyderm accounts following 956 unique pixelfed.social accounts and 864 unique pixelfed.social accounts following 651 unique Hachyderm accounts.
For mods and admins running Pixelfed instances
First and foremost: HugOps. Planning urgent upgrades for CVEs (and related) is stressful and time-consuming, and that is even more true for the volunteer teams across the Fediverse. You’ve got this!
We’ve also got this with you. We’ve done our best to find contact information to reach out to your admins and mod teams depending on what was listed on your instance or documentation if present, to ensure that you were aware of the situation. Due to the volume of instances impacted by this, this process is still ongoing at the time of publishing this blog post.
We’re happy to refederate with any instance that was defederated from as a result of this CVE. As mentioned in our emails as well, please email us once you have upgraded to 0.12.5 and we will refederate with you. You can also respond to the email that we sent out with the same information.
For anyone looking to communicate with Hachyderm moderation in general, please see both our documentation landing page and our Reporting and Communication page.
For fellow Mastodon admins
In the interest of expediency, we published this announcement so that people can see the analysis and impact of our decision. We will publish a separate, shorter, post to include our methods for gathering the above information for the benefit of the broader Mastodon community.
Defederation from Threads
Defederating from Threads
Hello Hachyderm! In alignment with our prior posts about inter-instance federation, and Threads in particular, Hachyderm has defederated with Threads due to their changes in moderation policy as of the publication of this post.
For those interested in learning more about Threads specifically, please read on.
Changes to Meta’s moderation policies and published statements by Mark Zuckerberg
On Tuesday, 7 Jan 2025, Mark Zuckerberg published a series of posts that described changes to Threads moderation practice, and Wired published an article about Meta’s updated moderation (Hateful Conduct) policies. Other articles have been published while we worked on this blog post as the decisions and implications evolve.
In short, Meta updated its Hateful Content policy to explicitly allow harassment for targeted groups and remove earlier protections. We strongly encourage others, especially moderation teams, to look beyond the current version of their Hateful Content policy and also look at the diff between their 2024 and 2025 policies to see what was altered and removed. You can do this by clicking on the Jan 2025 date on the left nav bar.
Threads is now in conflict with Hachyderm’s inter-instance moderation policies
When we consider defederating instances we consider the Hachyderm community, especially vulnerable members. This means that when we evaluate other instances we look at the impacts of those communities on our community.
We initially Limited Threads primarily to make Threads content “opt-in”, as much as Mastodon tools allow, as there are several news sources, government accounts (people and agencies), and so forth on Threads. (Relevantly, among the top followed Threads accounts were POTUS and Barack Obama.) This meant we also committed to manually moderating individual harmful accounts, and interactions with their content, to maintain community safety on Hachyderm while Threads was Limited.
Threads’ recent changes in their moderation policies, both what they’ve put in and what they’ve taken out (read the diff), puts their moderation practices in direct conflict with ours. Essentially, Threads may indeed be large enough that many users are just looking to exist somewhere on social media and are not necessarily de facto fans of Mark Zuckerberg et al., but we anticipate these changes to moderation will shift the user base of Threads in a way that is damaging to the Hachyderm community, so we are defederating from them before that can occur.
Risk and Value Considerations
When we consider defederating, another factor we consider is actual and perceived loss of value to members of the Hachyderm community. Being able to follow and interact with POTUS, local politicians, government agencies, family, friends, etc. from Hachyderm is potentially valuable.
Mid-2024 it seemed likely that Threads would be the social media platform many of those accounts would use or use as their primary social media presence. So it appeared that the long-term value was medium to high, while the slow roll-out of federation allowed us the ability and time to moderate Threads manually with low to low-medium community risk.
Between Meta’s policy changes and the increasing popularity of Bluesky, it seems many individuals are abandoning Threads. It seems likely that politicians and government agencies will or are moving their primary social media presence elsewhere. It now appears that the long-term value is low, and even with the slow roll-out for federation the risk to our community has changed to high.
There’s no perfect “calculation” here, but essentially the long-term risk/reward ratio went from overall medium-high to very low because of how significantly these policy changes increase risk of harm.
What was the data on Threads prior to defederation?
Part of how we handled Threads was meeting the situation where it was at any given time. This is why we were watching their policies, interactions with Hachyderm, news cycles, etc. This is also another reason that we mention here, and in earlier posts, about the slow roll-out of federation. It means that the “instance”, in the federation sense, is significantly smaller than the broader platform. To clarify what this means:
- Not all Threads accounts are federating, in fact most are not.
- Of the Threads accounts that are federating, not all are fully federating.
- In practice, this means that Fediverse users can see and read a user’s Threads posts, the Threads user cannot see Fediverse interactions with their posts. Functionally, this is/was similar to the experience of posting and boosting posts from Twitter bridges.
Specific data:
- There were ~10,000 total Threads accounts federating with Hachyderm.
- There is no way from the data to tell how many of these are fully or partially federating.
- To put this in perspective:
- This is significantly smaller than Mastodon Social (~265k accounts) and approximately the same size as other larger Fedi instances including Mastodon Online (~25k accounts).
- This is approximately 0.0036% of Threads users overall, as Threads has approximately 275 million active users (as of Nov 2024).
- There was one user-generated report regarding a Threads user. In that case it was not about harmful content but a user interaction. There were no other reports sent to Hachyderm moderation about Threads interactions.
To put this in perspective (and acknowledging that these two instances do not have the same moderation policy that Threads now does), we’ve fielded ~500 reports (in total) regarding Mastodon Social and 45 reports (in total) regarding Mastodon Online.
There were 2033 unique Hachyderm accounts following 919 unique Threads accounts and 26 unique Threads accounts following 22 unique Hachyderm accounts.
- For other mods, note that the queries to figure out are not what the Admin Dashboard is running. We’ll put the queries at the bottom of this blog post.
How does this tie into our overall moderation decision? Essentially, the changes to their moderation policy, whether they revert them or not, increase the risk of harm drastically and have a high likelihood of changing the Threads platform account demographics faster than our ability to manually moderate them. In that respect, the decision that we would need to defederate from Threads was made after we reviewed Threads’ current policy and its diff when it was released on Tuesday.
Before enacting the decision, we needed to understand the impact on the Hachyderm community and prepare this statement. Since the queries on the dashboard didn’t provide the level of granularity we needed, Hachyderm moderation and infrastructure coordinated to ensure that we were surfacing the correct data to inform our decision (the last bullet point above and the queries in the next section). This allows us to know how many Hachydermians would be impacted and to what degree. Thank you for your patience in this regard, as due to the significance of the follow/following severances that are occurring we wanted to be accurate in providing this data.
Queries to run to gather the above data
The query to run for “how many unique accounts on my instance are following Threads accounts” is:
Follow.joins(:target_account).merge(Account.where(domain: 'threads.net')).group(:account_id).count.keys.size
Our result in this case is 2033.
The query to run for “how many unique Threads accounts are following accounts on my instance” is:
Follow.joins(:account).merge(Account.where(domain: 'threads.net')).group(:account_id).count.keys.size
Our result in this case is 26.
The query to run for “how many unique accounts on my instance are being followed by Threads accounts” is:
Follow.joins(:account).merge(Account.where(domain: 'threads.net')).group(:target_account_id).count.keys.size
Our result in this case is 22.
The query to run for “how many unique Threads accounts do accounts on my instance follow” is:
Follow.joins(:target_account).merge(Account.where(domain: 'threads.net')).group(:target_account_id).count.keys.size
Our result in this case is 919.
Queries behind the admin dashboard
These numbers are different from what appears in the admin dashboard (instanceDomain.com/admin/instances/threads.net) because the dashboard runs different queries.
The “Their Followers Here” query is:
Follow.joins(:target_account).merge(Account.where(domain: domain)).count
In our dashboard this displayed as 6014.
The “Our Followers There” query is:
Follow.joins(:account).merge(Account.where(domain: 'threads.net')).count
In our dashboard this displayed as 27.
These numbers aren’t deduplicated, so they may not meet your needs when determining how heavily your instance is interacting with Threads.
10 Jan 2025 update: One of the four queries was dropped when we initially published this announcement late Thursday evening. We’ve added the query, as well as taken the opportunity to fix a couple typos and add small clarifiers.
Threads Update
What is Threads?
Threads is an online social media and social networking service operated by Meta Platforms. The app offers users the ability to post and share text, images, and videos, as well as interact with other users’ posts through replies, reposts, and likes. Closely linked to Meta platform Instagram and additionally requiring users to both have an Instagram account and use Threads under the same Instagram handle, the functionality of Threads is similar to X (formerly known as Twitter)1 and Mastodon.
What is the status of their ActivityPub implementation?
As of December 13, 2023, Threads has begun to test their implementation of ActivityPub. As of December 22, 2023, only seven users from Threads are federating with Hachyderm’s instance. For all other users on Threads, we are seeing that the system is not federating correctly due to certificate errors on Threads side. We understand that they are working to resolve those certification issues with assistance from the Mastodon core team.
Based on the available Terms of Use and Supplemental Privacy Policy provided by Meta, they are not selling any of the data they have. This is not official legal or privacy advice for individual users, and we recommend evaluating the linked documents yourself to determine for yourselves.
With regards to the section in the privacy policy
Information From Third Party Services and Users: We collect information about the Third Party Services and Third Party Users who interact with Threads. If you interact with Threads through a Third Party Service (such as by following Threads users, interacting with Threads content, or by allowing Threads users to follow you or interact with your content), we collect information about your third-party account and profile (such as your username, profile picture, and the name and IP address of the Third Party Service on which you are registered), your content (such as when you allow Threads users to follow, like, reshare, or have mentions in your posts), and your interactions (such as when you follow, like, reshare, or have mentions in Threads posts).
It’s important to remember a few things:
- The Mastodon/ActivityPub at their core uses a form of caching of information in order to make the process as seamless as possible. For example, when you create a verified link on your profile, every instance that your profile opens on does its own checks of the links and saves the validation on that third party server. This helps prevent malicious actors from falsifying their verified links that would then trickle out to other instances.
- We don’t transmit user IP’s to any third party instances as part of your interaction. If Meta is able to collect your IP, it would be through a direct interaction with a post on their server or CDN.
How does this impact Hachyderm?
At this point, Threads tests of the ActivityPub do not impact us directly. Based on the available information, they haven’t breached any rules of this instance, they aren’t selling any of the data as discussed above, and the user pool is so limited that even if they did, our team’s ability to moderate that would be quick and decisive. In addition, any users that do want to block Threads at this time, can follow the instructions in the next section to pre-emptively block Threads at their account level.
As a result, we will continue to follow our standard of monitoring each instance on a case by case to see how the situation evolves, and if a time comes that we see Threads federations as a risk to the safety of our users and community, we will defederate at that time.
Indirectly, we know that admins of other instances have expressed that they will defederate with any instances that will continue to federate with Threads. While we hope that the information in this blog post has helped people understand the currently limited risk of continuing to federate with Threads, we also know that other instances have a much more limited set of resources and may need to preemptively defederate with the Threads instance. The beauty of the Fediverse is that each instance has that right and ability.
How to block Threads.
- Search for “threads.net” in the search box
- Select a user from the results
- Open the menu from the profile
- Select “Block domain threads.net
- Read the prompt and select your desired action
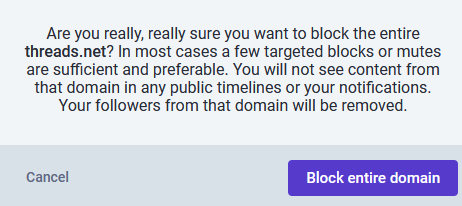
To understand the ramifications of blocking an instance, please review the Mastodon documentation for details on what happens.
Next Steps
As Threads continues to implement their integration with ActivityPub and the Fediverse at large, we will watch how those users integrate with our community and how their service interacts with our servers. If you would like to learn more about our criteria for how Hachyderm handles federating with other instances, please review our A Minute from the Moderators - July Edition where we list out our criteria.
Crypto Spam Attacks on Fediverse
The Situation
Starting around 8 May 2023, we began to receive reports that Mastodon Social was being inundated with crypto spam.

Initially, it appeared that only Mastodon Social, and then Mastodon World, were impacted. In each case we Limited the instance and made a site-wide announcement. As the issue progressed, it became clear that more instances were being targeted for this same style of crypto spam. As a result, we have decided to change our communication strategy to utilize this blog post as a source for what’s happening and who is being impacted, rather than relying on increasingly frequent site-wide announcements.
As it stands: right now we have seen waves of spam from Mastodon Social, Mastodon World, and now TechHub Social. These waves usually mean that we receive over 100-200 reports in less than a few hours. (By contrast, we usually receive ~20 reports per week.)
What this means for Hachydermians (and Mastodon users in general)
Spam attacks seem to make use of open federation to either find accounts to misuse follow/unfollow behaviors, DMs, comments, and other invasive behaviors. In general, Limiting a server is sufficient for mitigating the impacts of these behaviors. Limiting means that Hachydermian’s posts no longer show up in the Federated feeds of impacted instances, which means that bots can no longer use the Federated feed as a vector for malicious behavior. While this is a good thing and means that these bots will no longer be able to spam Hachydermians, the Limit works both ways. This means:
- The posts for Limited instances will no longer show up on the Federated feed
- You will receive approval requests for all accounts on Limited instances
- User profiles will appear to have been “Hidden by instance moderators”
The UI messages for the latter two are a little difficult at times to determine what it means. Essentially, you will see the same message for a user to follow you from an instance that’s been Limited, and for you to view their profile page, as you would if we had only Limited that specific user.
For users on the impacted instances, these messages should not be taken as the individual user has engaged in any sort of malicious activity. In general, when we see individual-level malicious activity, we suspend federation (block) the individual user rather than Limit them. Instead, these messages are only a consequence of us needing to Limit the servers while they are doing their best to manage the spam attacks they are undergoing.
The impacted instances
We are maintaining the list of instances that we are Limiting as a result of the current crypto spam attack here. Note that this is not all instances we currently have Limited for any reason, only the ones that are experiencing this specific scenario. We will continue to announce when new instances are added to this list via our Hachyderm Hachyderm account and link back to this blog post. Instances that are no longer impacted will be un-Limited and removed from the list below. (When the list is empty, that means that all instances have been un-Limited.)
Updates
Update 25 May 2023 - we’ve been crypto spam free from Mastodon Social and Mastodon World, so we’ve gone ahead an un-Limited those instances.
Update 2 Jun 2023 - we’ve been crypto spam free from TechHub Social, so we’ve gone ahead and un-Limited that instance! That’s the last one, so this incident is resolved.
Updating Domain Blocks
Today we are unblocking x0f.org from our list of suspended instances to federate with.
Hachyderm will begin federating with x0f.org immediately.
Reason for suspending
We believe the original suspension was related to early moderation actions taken earlier in 2022. The moderation actions took place before Hachyderm had a process/policy in place to communicate and provide reasoning for the suspension.
Reason for removing suspension
According to our records, we have no reports on file that constitute a suspension of this domain. The domain was brought to our attention as likely flagged by mistake. After review we have determined that there is no reason to suspend this domain.
A Note On Suspensions
It is important to us to protect Hachyderm’s community and our users. We may not always get this right, and we will often make mistakes. Thank you to our dedicated users for surfacing this (and the other 13 domains) we have removed from our suspension list. Thank you to the broader fediverse for being patient with us as we continue to iterate on our processes in this unprecedented space.
Opening Hachyderm Registrations
Yesterday I made the decision to temporarily close user registrations for the main site: hachyderm.io.
Today I am making the decision to re-open user registrations again for Hachyderm.
Reason for Closing
The primary reason for closing user registrations yesterday was related to the DDoS Security Threat that occurred the morning after our Leaving the Basement migration.
The primary vector that was leveraging Hachyderm infrastructure for perceived malicious use, was creating spam/bot accounts on our system. Out of extreme precaution, we closed signups for roughly 24 hours,
Reason for Opening
Today, Hachyderm does not have a targeted growth or capacity number in mind.
However, what we have observed is that user adoption as dropped substantially compared to November. In my opinion, I believe that we will see substantially less adoption in December than we did in November.
We will be watching closely to validate this hypothesis, and will leverage this announcement page as an official source of truth if our posture changes.
For now we have addressed some more detail on growth, registrations, and sustainability in our Growth and Sustainability blog.
Posts
A Minute from the Moderators
Welcome back to Moderator Minutes. This is the third post in our series on Community Care in Online Spaces.
A note before we begin, and as with the rest of this series: these posts run a little denser than our usual Moderator Minutes, and we don’t expect anyone to absorb all of it at once. We’ll keep the recap short, because each post is meant to stand on its own, but if you’d like the fuller picture: Part 1 looked at how shifting norms create friction, and asked you to sit with a question: is it working? Part 2 looked at what drives us toward confrontation in the first place, and at the idea of care webs: the networks of mutual support that let us do collective work without each of us carrying it alone.
Both of those posts asked you to lead with connection. To avoid assuming bad faith. To choose communication over correction, and to extend considered grace to people who are, like all of us, navigating norms that keep shifting under their feet.
You may have noticed that we kept setting something aside. We said, more than once, that choosing community care does not guarantee care in return. We said there are times when connection is not the answer, and that we would come back to them. And we mentioned, briefly, that when connection fails you have other tools available and that we would talk more about those later.
This is later. This post is about what to do when connection isn’t enough.
Connection First Is Not Connection Only
We want to be clear about something up front, because it would be easy to read this post as a reversal of the previous two. It isn’t.
Everything we said about leading with grace still holds. For the vast majority of the friction we see, the person on the other side is not acting in bad faith, and connection really is the better choice. None of that changes.
It’s worth saying why we keep recommending it, because the reason is not sentimentality. Connection-first is, in part, a guard against two equally costly mistakes: the naïveté that insists no one would ever act in bad faith, and the suspicion that treats everyone as an enemy until proven otherwise. When you enter an unfamiliar interaction, you usually don’t yet know which kind you’re in. You’re building that picture in real time, from the data the interaction gives you. Leading with connection means keeping the other person’s humanity in view while that picture forms, rather than deciding it in advance. And there’s another reason, and gently that is: how you treat someone you’ve judged to be acting badly is, in the end, as much a statement about you as about them. That matters especially because the judgment that feels most certain in the moment is exactly the kind we sometimes get wrong.
But “lead with connection” was never the same as “extend infinite grace to everyone, forever, regardless of how they respond.” Those are different claims, and the difference is the whole subject of this post. You can afford to lead with generosity precisely because you are not obligated to keep extending it into a void. Boundaries are not the opposite of community care. They are part of what makes it sustainable. They are how you keep the door open without leaving yourself standing in the doorway indefinitely, absorbing whatever comes through it.
So this is not the post where we tell you to stop being generous. It’s the post about what holds that generosity up.
Boundaries: The Part You Control
A useful place to start is a distinction that quietly resolves a lot of online conflict: the difference between what you will do and what you want or need someone else to do.
The first is a boundary. The second is a request.
“I’m not going to keep discussing this tonight” is a boundary. You control it completely. “You need to stop replying to me” is a request, and whether it’s honored is no longer in your hands. Both can be reasonable. But only one of them is something you can actually enforce, and a great deal of exhaustion comes from trying to defend a line that depends on someone else’s cooperation to hold.
Boundaries phrased as things you control are ones you can keep. Muting a thread you keep getting pulled back into. Saying once, clearly, that you’re stepping away, and then actually stepping away rather than staying to monitor how it lands. Deciding in advance what you’ll do if a particular kind of message arrives, so the decision is already made when it does. None of these require the other person to agree, which is exactly why they work.
Holding a boundary is harder than setting one, especially in public, and extra especially when someone is testing it. The pull to re-engage is not a personal failing; it’s a normal response to the discomfort of leaving something unresolved and the worry that silence will be read as concession. It helps to remember two things. The first: you can’t control how your boundary is interpreted. Trying to, by staying just long enough to correct the record, is usually how it collapses. The second: you can hold the boundary whether or not it is understood. You do not have to announce it twice, defend it, or win the argument about whether you were allowed to draw it.
This is, itself, a form of the community care we’ve been describing. In Part 1 we wrote that the practice of choosing connection over punishment is part of building the community we all want to live in. Setting a clear boundary is part of that same building. It models that limits are normal, that they can be stated without hostility, and that staying in community does not require dissolving yourself into it.
When the Other Person Isn’t Trying to Hear You
Most of what we’ve written about de-escalation, here and in earlier posts, is for situations where the other person wants to understand you. In those situations, it’s often true that if you communicate clearly, you’ll be heard as you both share the goal of understanding.
Sometimes it isn’t true, though. Sometimes you communicate clearly, you make a reasonable request, and the other person still doesn’t hear you. As we noted in Part 1, when that happens, that is not on you. And sometimes the person on the other side is not trying to reach an understanding at all. They are reaching for something else. Maybe they want to change your mind as much as you want to change theirs. Maybe they are starting from a different premise, and the two of you are not actually arguing about the same thing. Maybe they just want a reaction. Whatever the reason, the part you can act on is the same: they aren’t hearing you. Sorting out exactly why rarely changes what you do next.
De-escalation looks different in that situation. It is no longer about reaching the other person, because the other person is not reachable in the way de-escalation depends on. It becomes, instead, about not handing them fuel. You lower your own stakes rather than matching theirs. You decline the thread instead of feeding it. You resist the pull to perform for whoever might be watching. The strongest move available is often simply to stop adding to it, not because you’ve conceded, but because continuing only gives the dynamic more to run on.
Part of what makes these situations so sticky is the urge to make the other person admit the thing. As a slightly more precise example: let’s say you witness someone being ableist, to you or another. You are unlikely to convince them of it in the moment, for any number of reasons. They may tell you they are not being ableist: they are only being direct, or honest, or precise. Here it helps to notice that both things can be true at once. Someone can be direct (or precise, etc.) and ableist. Someone can be giving genuine advice and be ableist in how they give it. “I’m actually doing this other thing” rarely makes the first thing stop being true, and arguing the point usually just feeds the dynamic we just described. So it’s worth asking what you actually want. Maybe part of what you want is for other people to come away with better understanding, so that they have an opportunity to grow. A fresh post in a separate thread often serves that far better than the argument in front of you: the people who want to learn can choose to enter it, and it doesn’t drag in the person who has made clear that is now how they are engaging at this time.
This is where disengagement stops being avoidance and becomes a genuine tool. Walking away from an interaction that has nowhere good to go is not losing. It is refusing to spend your energy where it cannot accomplish anything.
The Tools You Already Have
It’s worth pausing on why a post about bad faith has spent so long on boundaries and self-regulation. The reason is a framing choice: a great deal of bad-faith and inauthentic behavior can be modeled as a boundary violation. Content you don’t want shown to you. A phishing attempt you don’t want to engage with. An effort to extract protected data (e.g. personal information, payment details) that you don’t want to disclose. Attempts to slip past the filters so you see content you opted out of. In person-to-person interactions, it is often true that sometimes the other person genuinely doesn’t understand your boundary, since you are two different people. And it is also true that sometimes others put in real effort to get around boundaries. By choosing to frame these as two sides of the same coin, boundary violations, we have a dual purpose model that serves both when people don’t understand and when they definitely do. And the tools for one are the tools for the other.
While not a software feature, disengagement is a tool at your disposal. It is not the only one, and for the harder situations it is not enough on its own. This is the part Part 1 seeded that we wanted to give real space to here.
Beyond simply stepping away, most platforms give you tools to enforce boundaries directly and Mastodon is no exception: you can mute or block an individual, or block an entire server. You can filter keywords in or out. And you can do this independent of the “faith” of the engagement you are in or witnessing. You can do it for any reason at all. Maybe you dislike the way you see someone engaging with others. Maybe there are some forms of content that aren’t harmful, but that you simply don’t want in your day. These tools are yours, and using them does not require you to build a case.
When an interaction has gone past the point where connection or boundaries can resolve it (someone is harassing you, evading your boundaries, escalating instead of de-escalating, etc.), you have a path that does not require you to either keep absorbing it or handle it alone: you can report it to your moderation team.
Bringing in a moderation team is not an escalation nor a failing. It is the opposite of what was flagged in Part 1, where people are fighting it out instead of reaching for other options. Reaching out for help is a de-escalatory move. It takes a conflict that is not resolving on its own, and diverts it to try another approach or neutral eyes.
You might hold back from reporting because you don’t want to add to a team that is already carrying a lot. That hesitation is its own kind of care, and it is worth setting down gently. A report is not a weight dropped on someone else. It is the web doing what it is built for, and a pattern no one names is harder to hold than one that is reported.
This is, in the most concrete sense, the care web from Part 2 doing what it’s for. You were never meant to carry the whole interaction by yourself. A moderation team is part of the infrastructure that holds it with you. When you report, you are not offloading a problem; you are using a structure that exists so that no single person has to be the entire response to harm directed at them.
And reporting is care directed outward, too. A report is information. It helps the people whose job is to keep a space safe see patterns they would otherwise miss, and to protect others who may be experiencing the same thing and saying nothing. It provides visibility when someone is testing more boundaries than only yours. In this way, choosing to report contributes to community care.
Practical Notes for Hachydermians
Everything so far applies on any instance or platform. These last notes are specific to Hachyderm, so reporting here never becomes a barrier.
Report when behavior crosses into harassment or boundary violations, on or off Hachyderm. For anything that has a lot of complexity or deeper back-and-forth, email us. That is also how we receive security reports. For one-to-one or point-in-time things, the Mastodon’s Report feature works very well. Both reach us, so use whichever suits the moment. Please don’t worry if you have all the details, we’ll ask follow up questions if we have them. What matters is that your report comes through one of these, where we can act on it. When another instance is involved, please feel free to reach out to us if you would like us to engage with their moderation team.
Also, and this is important: none of these are last resorts. You do not have to wait until something is unbearable to use them. They are part of how a healthy space takes care of the people in it.
What Holds It Up
Across these three posts, we’ve described a range of practices where some might feel contradictory. It asks you to lead with connection and extend grace, while encouraging you at the same time to set and maintain boundaries, disengage, and ask for help / report to your moderation team as needed.
The tension is easier to feel once you notice that the tools themselves can be turned to more than one purpose. The same block can enforce a boundary or deliver a punishment. The same report can protect a community or settle a score. This is the line Part 1 drew between connecting and punishing, and it runs straight through the tools. Before you act, the question worth asking is which one you are reaching for, because that is the part still in your hands.
That goal changes how you act, even when the visible outcome looks similar. Someone blocked to keep a boundary and someone blocked to be punished may both simply experience being blocked, and you cannot fully control which way it lands for them. How an action is received is its own matter, with its own weight, and worth a fuller conversation another time. What you can govern in the moment is the aim, and the aim shapes the conduct around it. Protecting your own space tends to look quiet: you do it and then stop. Trying to make someone pay tends to look loud: you reach for an audience, you escalate, you keep going. The boundary closes a door. The punishment tries to follow them through it.
This approach to community care is multifaceted, rather than contradictory. The generosity of the first two posts and the limits of this one are both expressions of one purpose: building and protecting the community you actually want to live in. You can keep choosing connection, again and again, because you are not defenseless when it isn’t returned. That community is shaped as much by where you hold a line as by where you extend a hand. Both are how it gets made.
Thus far, we have described moderation from the outside, as something to reach toward when connection runs out. In future posts we’ll discuss the work of moderation itself; not the reporting that is covered here, but what happens on the other side of it.
How you can help others
We know a lot of people are running low right now, so we’ll keep the prompt light this time: what is a content filter or mute you would recommend to someone new to the Fediverse? Answer wherever feels easy, in Zulip or out on the Fediverse with #CommunityCare. As a reminder: we’re not automating the Discord to Zulip migration, so please check in Discord for information for how to be added to Zulip.
Further reading
(Many of these can also be found at the Further Reading section of Part 2.)
On calling in and calling out. The phrase “calling in” comes from Ngọc Loan Trần’s 2013 essay “Calling IN: A Less Disposable Way of Holding Each Other Accountable,” published on Black Girl Dangerous and archived on TransformHarm.org. Loretta Ross has spent the decade since turning the idea into something teachable, drawing on five decades of organizing. Her TED talk runs about fifteen minutes and is a good place to start. Her book Calling In: How to Start Making Change with Those You’d Rather Cancel (Simon & Schuster, 2025) develops a five-part continuum of responses (canceling, calling out, calling off, calling on, and calling in) with practical guidance on when each one fits.
On online harassment and digital safety. Each is most useful read before you need it; the differences are in emphasis.
- PEN America’s Online Harassment Field Manual: organized by your role in the situation, whether you are being targeted, witnessing it, or running an organization where staff are. Written especially for writers, journalists, artists, and activists. (Appears to have geo restrictions.)
- Games and Online Harassment Hotline Digital Safety Guide: the most granular on specific tactics like doxxing prevention and hate raids, and direct about how well-meaning allies can amplify harassment by stepping in. The hotline closed in October 2023, but the guide is still online.
- EFF’s Surveillance Self-Defense: the deepest on technical infrastructure, with a “Security Scenarios” section that tailors a learning path to your situation.
On community safety and transformative justice. Get in Formation: A Community Safety Toolkit, from Vision Change Win, collects security and safety practices developed over years within Black, Indigenous, and People of Color movements in the U.S. It covers verbal and physical de-escalation, bystander intervention, and organizational safety planning, with handouts and worksheets you can adapt to your own conditions. It lives on The Commons Social Change Library, a broader catalogue of openly accessible movement resources worth browsing when your question is harder to name in advance. For the deeper organizing frame, Beyond Survival: Strategies and Stories from the Transformative Justice Movement (Leah Lakshmi Piepzna-Samarasinha and Ejeris Dixon, eds., AK Press, 2020; review on Autostraddle) gathers approaches to addressing harm without relying on punishment.
A Minute from the Moderators
Welcome back to Moderator Minutes. This is Part 2 of our series on Community Care in Online Spaces.
In Part 1, we explored how norms shift, how those shifts create friction, and how the ways we respond to that friction can either build or erode community. We asked you to sit with a question: is it working? And we talked about the difference between reacting and responding, between correcting and connecting.
This month, we’re going one layer deeper. Rather than looking at what we do when friction arises, we want to look at what drives us there in the first place. What is it about seeing something distressing that makes us want to act immediately, and what happens when that impulse meets the realities of navigating online spaces?
A note before we begin: the posts in this series are denser than our usual Moderator Minutes. We’ll be drawing on work from several writers and activists who have spent years thinking about these patterns, and we’ll include a reading list at the end for those who want to go further. We don’t expect anyone to read all of it. We do hope the ideas here give you something useful to sit with.
The Impulse to Act
When we see something awful happening, most of us are moved to act. The worse it is, the stronger the pull. This is not a flaw. It is, in many ways, one of the better things about us. The desire to do something in the face of harm is the engine behind every mutual aid network, every crisis response, every act of solidarity that has ever mattered.
But there is a difference between urgency and intention. Urgency says: something must be done, now. Intention asks: what am I trying to achieve, and will this action get me there? When we act from urgency alone, without pausing to examine our goals, we may not know whether our actions meet them. Worse, we may not recognize when our actions actively prevent them.
This is not a new observation. In 2013, writer and organizer Ngọc Loan Trần published an essay called “Calling IN: A Less Disposable Way of Holding Each Other Accountable.” Trần, a queer, disabled, Việt/mixed-race activist, wrote it after attending a large racial justice conference, a room full of people who shared values, who understood the stakes, who all “got it.” And what Trần observed was that those same people, in that shared space, had lost compassion for each other.
That observation is worth sitting with. It was not a room full of people who didn’t care. It was a room full of people who cared enormously, acting from urgency rather than intention, and in doing so, causing harm to the very community they were trying to protect.
Trần coined the term “calling in” to describe an alternative: accountability rooted in relationship rather than punishment. The idea took hold, and over the following decade, a lineage of writers and practitioners built on it. We will be drawing on several of them throughout this post.
The reason we start here is that this pattern, good people, strong values, urgency without intention, is not limited to conferences or activist circles. It is the pattern we see in our reports. It is the pattern many of us enact in our own timelines. And it is the pattern that, left unexamined, erodes the communities we are trying to sustain.
The Pressure to Do More
The urgency we just described does not exist in a vacuum. It is fed by something deeper: the persistent feeling that whatever we are doing, it is not enough.
Consider an example. Say you have spent your week writing posts to help people: sharing mutual aid links, amplifying crisis response information, sending messages of care to people in vulnerable or targeted communities. You have been doing real, tangible work. Then you log in and see a wave of news, or an online harassment campaign, or another round of something terrible, and the question surfaces: am I doing enough?
Let’s mirror something from Part 1 and sit with our feelings for a moment.
Do you feel like you are doing enough, with what is happening in the world, right now?
Whatever your answer is, stay with it a little longer. Feel your way through why you do, or don’t, feel that you are doing enough.
This is not a rhetorical exercise. How you answer that question shapes how you behave online. When the answer is “no” (and for many of us, the answer is almost always “no”) it creates pressure. That pressure comes from two directions. It comes from inside: the internal monologue that tells us we should be doing more, doing it better, doing it differently. And it comes from outside: from communities, from trusted voices, from the implicit and sometimes explicit message that if you are not visibly fighting, you are complicit.
Both of these pressures can be valid in their origin. But when they compound, they produce a specific and damaging result: we stop being able to see the work we are already doing. The posts we wrote, the care we extended, the quiet labor of showing up consistently, all of it disappears under the weight of what we haven’t done. And once we can no longer see our own contributions, we become desperate to do something that feels visible, immediate, and unmistakable.
In 2016, writer and activist Maisha Z. Johnson named a version of this pattern in her essay “6 Signs Your Call-Out Isn’t Actually About Accountability,” published on Everyday Feminism and later republished by YES! Magazine. Johnson, whose background includes work with Community United Against Violence, the nation’s oldest LGBTQ anti-violence organization, described what happens when holding each other accountable drifts into punishing each other. She drew a distinction between acting out of love for our communities and acting out of fear and pain. The behaviors can look similar from the outside, both involve publicly naming a problem, but they come from different places and produce very different outcomes.
What Johnson was naming is something many of us will recognize if we are honest with ourselves. There are times when we call something out because we have a clear goal: we want a specific behavior to change, and we believe our words will contribute to that change. And there are times when we call something out because we are exhausted, because we are afraid, because the pressure to do something has become unbearable and this is the something that is available to us. The second is not accountability. It is release. And while the release is understandable, it is not the same as the work it replaces.
Where We Feel Power
There is a concept in psychology called “locus of control.” It describes where we believe power over our lives sits, inside ourselves, in our own actions and choices, or outside ourselves, in forces beyond our control. The term comes from the work of psychologist Julian Rotter in the 1950s, and it has been widely studied since.
We want to be careful with this concept, because the traditional framing carries a bias. The conventional view treats an internal locus of control, the belief that your actions shape your outcomes, as the healthier orientation. But this framing was developed within a Western, individualist perspective, and it has a significant blind spot. For people from marginalized and targeted communities, the feeling that external forces control your outcomes is often not a distortion. It is an accurate reading of the situation. Discrimination, structural oppression, and systemic inequity are real forces that genuinely constrain what individual action can achieve. Scholars studying locus of control in the context of marginalized populations have noted that what looks like a “less healthy” external orientation may in fact reflect a realistic assessment of the limitations that racism, discrimination, and socioeconomic conditions impose.
So we are not using this concept to suggest that feeling powerless is itself a problem to fix. For many of us, the feeling of lacking control is grounded in reality, and naming that is important.
What we do want to examine is what happens next. What we do with that feeling.
Here is an analogy. Imagine you volunteer at a soup kitchen. In relatively stable times, the work feels meaningful. You can see the people you are helping. The scale of the need, while real, feels approachable. Your contribution feels like it matters.
Now imagine the same soup kitchen during an extreme crisis, a climate disaster, an economic collapse, a wave of displacement. The lines are longer. The need is greater. The news is relentless. You are doing the same work, or more, but it no longer feels like enough. The scale of the crisis dwarfs your individual contribution, and the gap between what is needed and what you can provide becomes a weight you carry home with you.
The work did not become less valuable. But your relationship to it changed.
This is what happens in online spaces when the world feels like it is on fire. Even if you are showing up consistently, posting resources, supporting others, extending care, the relentless news cycle and the visible enormity of harm can make all of it feel like nothing. And when your sustained, quiet work feels like nothing, the pull toward something louder becomes very strong.
This can lead to an unhealthy relationship with the negative feelings that accumulate. You may not be able to stop an oppressive force. But you can shout about it. You can name and shame. You can find a target and direct your frustration somewhere, anywhere, because the alternative, sitting with the feeling that you cannot individually fix what is broken, is unbearable.
The shift is subtle, and it is worth naming precisely: the goal stops being “change this specific thing” and becomes “make this feeling go away.” That is the moment where the impulse to act stops serving the community and starts serving our own need for relief. And as we discussed in the previous section, that is not accountability. It is release wearing its clothes.
Misdirected Action
Once that shift has happened, once the goal has quietly become relief rather than change, the question of where we direct our energy starts to matter in a different way.
Not all calling out is the same. There are differences in context, in scale, and critically, in the power held by the person on the receiving end. When we are acting from intention, we tend to account for those differences naturally. We think about who we are talking to, what we want to achieve, and whether this specific action in this specific context will move us toward that goal. When we are acting from urgency and exhaustion, those distinctions collapse. Everything feels equally urgent. Everyone feels equally responsible. And the energy has to go somewhere.
Consider this example. A large company does something harmful. The CEO makes a decision that affects thousands of people. You are angry, and that anger is justified. But the CEO is not on your timeline. The person who is on your timeline is the company’s social media manager, posting the corporate line because that is their job. They did not make the decision. They likely have no authority in the hierarchy that produced it. They may privately disagree with it. They need to buy food and pay rent, and this is the job they have.
There is a reason this feels like a distinction without a difference in the moment. When a person speaks, we naturally assume they are speaking with their own voice, that their words represent their own thoughts, their own positions, their own authority. That is how individual speech works. But corporate speech breaks that assumption. The social media manager is voicing something that was shaped by people they may never have met, reflecting decisions they had no part in making. They are a conduit, not a source. And yet, because we hear a person speaking, we instinctively assign them the ownership that comes with speech. The CEO, the social media manager, the customer support agent, all of them register as “the company” in a way that erases the vast differences in their actual authority. This is natural, but it is not accurate. And when we act on it without examining it, we direct real force at people who have no capacity to give us what we want.
If you spend your afternoon arguing with that social media manager, or ten social media managers across ten companies, you have not changed the company’s behavior. You have not reached the decision-maker. You have not decreased the harm. You have worn yourself out, and a person who was not responsible for the harm has absorbed the force of your frustration.
There is also an alternative that is easy to miss. You can call out the company without engaging with its social media account at all. You can post about what the company did, name it clearly, tag a handle or use a hashtag if you want visibility, and then not respond when the company account replies. The social media manager or their team may be tasked with responding to mentions. That does not obligate you to continue the conversation. You have said what you needed to say. You do not owe anyone a thread. Posting about a company and arguing with its lowest-ranking representatives are very different actions, and only one of them preserves your energy for the work that actually matters.
This is not a moral judgment. It is a practical observation. When we stop distinguishing between targets based on their actual power and responsibility, we spread our energy across surfaces that cannot absorb it productively. It feels like fighting. It is not the same as building.
Kai Cheng Thom, a Chinese-Canadian trans woman, writer, social worker, and conflict resolution practitioner, wrote directly about this dynamic in her book I Hope We Choose Love: A Trans Girl’s Notes from the End of the World. Thom observed that in social justice communities, “accountability” had increasingly become a script, a performance of the correct response rather than a genuine path toward repair. The question she posed was pointed: are we more committed to the feeling of calling out than to the work of resolving conflict?
Thom was writing from inside queer and trans communities, about dynamics she had experienced firsthand, and her observation carries a challenge that applies well beyond those communities. If accountability has become a performance, if we are following the script because the script makes us feel like we are doing something, then we need to ask what the performance is replacing. And whether we would be willing to do the harder, quieter, less visible thing instead.
That question is not comfortable. It is also, we believe, necessary. Because if the patterns we have described in this post are recognizable to you, the urgency, the pressure, the powerlessness, the misdirected energy, then you are already familiar with how exhausting they are. You already know that they are not sustainable. And you may already suspect that there is something better available, even if you are not sure what it looks like.
That is what we want to talk about next.
Channeling Energy Constructively
Everything we have described so far, the urgency, the pressure, the collapse of distinctions, the drift from accountability into release, shares a common feature. It is all individual. It is one person, overwhelmed, trying to address systemic harm through individual action, burning through their own reserves in the process.
This is not a coincidence. The patterns we have been describing are, in large part, the result of trying to do collective work alone.
Leah Lakshmi Piepzna-Samarasinha, a disabled queer writer and longtime disability justice activist, offers a different frame. In their book Care Work: Dreaming Disability Justice, Piepzna-Samarasinha describes a concept they call “care webs,” networks of mutual support that are not built in response to a crisis, but maintained as ongoing infrastructure. A care web is not one person showing up heroically in a moment of need. It is a group of people who have already done the work of figuring out who can do what, who needs what, and how they will sustain each other over time.
The distinction matters for what we are talking about here. When you are operating alone, one person, one timeline, one set of reserves, every new crisis draws from the same finite well. The pressure to do more is a pressure on you, personally, and when you cannot meet it, the failure feels personal too. The urgency becomes yours to carry. The powerlessness becomes yours to manage. And the misdirected action we described earlier becomes almost inevitable, because individual urgency demands individual action, and individual action at that scale does not work.
A care web changes the unit of action. Instead of asking “what can I do about this?” you are asking “what can we sustain together?” Instead of measuring your contribution against the scale of the crisis, a measurement that will always come up short, you are measuring it against what your web has agreed it can hold. The soup kitchen does not become less overwhelming because you joined a care web. But your relationship to the overwhelm changes, because you are no longer the only person responsible for responding to it.
This is not abstract. In online spaces, care webs can take forms that many of you will recognize even if you have not used the term. A group of people who coordinate to amplify mutual aid posts so that no single person has to carry the full weight of visibility. A set of friends who check in with each other before responding to a provocative thread, not to police each other but to ask: are you okay? Is this the thing you want to spend your energy on right now? A community that has explicitly discussed what it is building together, so that when the next crisis arrives, its members have a shared framework for deciding how to respond rather than each person reacting alone.
What these examples share is that they move the question from “am I doing enough?” to “are we building something that can sustain us?” That shift does not eliminate the urgency. It does not make the world less frightening. But it changes the relationship between the individual and the work. It makes the quiet, sustained labor, the posts, the check-ins, the mutual aid, the showing up, visible again as contributions to something larger, rather than invisible drops in an endless ocean.
This is what we mean by channeling energy constructively. Not the absence of anger. Not the suppression of urgency. But the practice of directing that energy into structures that can hold it, that can receive it and convert it into something that outlasts the moment. A post about a company’s harmful behavior, written with clarity and shared once, is channeled energy. A thread that spirals into hours of argument with people who have no power to change anything is not. A check-in with someone in your community who you know is struggling is channeled energy. Doomscrolling until you find a target for the feelings you cannot sit with is not.
The difference is not always obvious in the moment. That is why the infrastructure matters more than any individual decision. If you have already built the web, if you have people who will check in with you, if you have a shared understanding of what you are building together, then the moment of crisis is not the moment where you have to figure all of this out alone. You have already done that work. And the work you did counts.
Sitting With It
We started this post by asking you to go one layer deeper, to look not just at how you respond to friction, but at what drives you there. We have covered a lot of ground: the gap between urgency and intention, the pressure that makes our own work invisible to us, the ways powerlessness channels itself into misdirected action, and the difference between acting alone and building something that can sustain us.
We want to close by returning to the question we asked earlier in this post, with a small shift:
Where is your energy going, and is it creating what you want for yourself and your community?
If you have been sitting with that question as you read, you may have noticed something. The answer may not have changed. But the way you are looking at it might have.
If your energy is going toward things that leave you exhausted without moving you closer to what you want, for yourself or for the people around you, that is not a signal to try harder. It may be a signal that you are carrying something alone that was never meant to be carried alone. It may be a signal that your reserves are depleted and that what you need is not more action, but more support. It may be a signal that the structures around you, the care web, the shared understanding, the people who check in, are not yet built, or need tending.
None of that is a failing. All of it is an invitation.
In our next Moderator Minutes, we will be looking at what happens when these ideas meet friction in real time: how to set and hold boundaries in online spaces, and how to de-escalate when things are already moving fast. If this post was about understanding where your energy goes and why, the next will be about protecting it when it matters most.
Our community discussions have moved to Zulip since the last Moderator Minutes. We are still inviting people in by hand, so if you would like to join us, ping us in our Discord and we will get you added.
As always, processes grow over time, and this conversation is no exception.
Further Reading
References
Ngọc Loan Trần, “Calling IN: A Less Disposable Way of Holding Each Other Accountable” (2013). Published on Black Girl Dangerous. Also archived on TransformHarm.org.
Maisha Z. Johnson, “6 Signs Your Call-Out Isn’t Actually About Accountability” (2016). Published on Everyday Feminism. Also republished by YES! Magazine.
Kai Cheng Thom, I Hope We Choose Love: A Trans Girl’s Notes from the End of the World (2019). Arsenal Pulp Press. Here is a review on Plenitude Magazine.
Leah Lakshmi Piepzna-Samarasinha, Care Work: Dreaming Disability Justice (2018). Arsenal Pulp Press. Here is a review on Autostraddle.
Leah Lakshmi Piepzna-Samarasinha and Ejeris Dixon, eds., Beyond Survival: Strategies and Stories from the Transformative Justice Movement (2020). AK Press. Here is a review on Autostraddle.
If you’d like to read more
On calling in and calling out: Loretta Ross has spent the decade since Trần’s essay turning “calling in” into something teachable, drawing on five decades of organizing. Her TED talk is about fifteen minutes and a good place to start. Her book Calling In: How to Start Making Change with Those You’d Rather Cancel (Simon & Schuster, 2025) develops a five-part continuum of responses (canceling, calling out, calling off, calling on, and calling in) with practical guidance on when each one fits.
On online harassment and digital safety: Each of these is most useful when you read it before you need it. They cover overlapping ground in different registers, so it is worth knowing which is closest to your situation.
- PEN America’s Online Harassment Field Manual: written for writers, journalists, artists, and activists, particularly those who are women, BIPOC, or LGBTQIA+. What makes it distinct is that it is organized by your role in the situation, whether you are being targeted, witnessing someone else being targeted, or running an organization where staff is, rather than as one undifferentiated guide. (This resource appears to have geo restrictions.)
- Games and Online Harassment Hotline Digital Safety Guide: originally written by Jaclyn Friedman, Anita Sarkeesian, and Renee Bracey Sherman, all of whom had been targeted themselves. It is the most granular of the three on specific tactics like doxxing prevention and hate raids, and it is especially direct about how well-meaning allies can inadvertently amplify harassment by engaging on a target’s behalf. The hotline itself closed in October 2023, but the guide is still online.
- EFF’s Surveillance Self-Defense: the deepest of the three on technical infrastructure (encryption, secure messaging, device security, network circumvention). The “Security Scenarios” section lets you pick a situation that matches yours (activist, journalist, abortion access worker, LGBTQ youth) and follow a tailored learning path rather than starting from scratch.
On activism, organizing, and community safety more broadly: The Commons Social Change Library is the broadest of the resources in this section. Run by movement librarians in Australia, it curates over 1,500 free, openly accessible materials from movements around the world, organized into collections on campaign strategy, community organizing, working in groups, justice and diversity, and creative activism. Where the resources above are sharply focused, the Commons is where you go when your question is harder to name in advance.
A Minute from the Moderators
Welcome to February!
For both this month’s and next’s Moderator Minutes, we’d like to spend some time discussing Community Care in Online Spaces: what it looks like, why it matters, and how the ways we engage with each other can either cultivate or corrode it.
What Is Community Care?
Community care, in its most tangible form, tends to manifest as in-person support services. Body doubling for errands, welfare check-ins, shared meals. The kind of reciprocal sustenance that keeps people and neighborhoods intact. While we are not in person here, the underlying ethos translates directly to digital spaces. The way we center our intentions is the same; it is the modality that differs.
Community care in an online context is the practice of centering collective wellbeing in how we engage with each other. Not merely what we say, but also: how we interpret, how we respond, and how we protect. It encompasses the choices we make when we encounter something that confuses us, frustrates us, or frightens us. It is, ultimately, the difference between reacting and responding.
Why Now?
We have noticed an increase in certain patterns appearing in our reports and as well as the broader Fediverse. They tend to cluster into a few categories: people having difficulty expressing or maintaining their boundaries, people having difficulty understanding and respecting the boundaries of others, people struggling to de-escalate conflict, changes and reinterpretations of historical norms and phrases, and an increase in reported posts (on and off Hachyderm) that start to touch on our “No Violence” rule.
We are not going to address all of these in a single post. This month, we are focusing on norm shifts: how they happen, why they matter, and how they can be both a force for care and a vector for harm. In our next Moderator Minutes, we will address some of what drives all of us toward confrontation and what it means to channel that energy safely. Boundaries and de-escalation will follow after that.
These patterns are not unrelated phenomena, and some of them have been building for years. They share a common root: the compounding stress of navigating spaces where the rules of engagement are shifting under everyone’s feet, incumbents and newcomers alike. When our reserves are depleted, our interpretive generosity contracts. Our fuses shorten. Our impulse to correct, rather than connect, intensifies. All of this is understandable, and much of it is even admirable in its origin. But the downstream effects are creating friction and, in some cases, genuine harm within our community.
We want to walk through this pattern. Not to admonish, but to illuminate. And as you read, we’d like to ask you to hold two questions:
- When you encounter a norm violation, how do you tend to respond?
-and- - Has it been working?
Shifting Norms and Maladaptive Responses
When Communities Collide
Norms collide whenever a community changes substantially in size or composition. For the Fediverse, 2022 was a major inflection point. People leaving The Twitter That Was arrived in droves, and with them came an entirely different set of internalized expectations about how to engage on social media.
The existing Fediverse had, over years, developed norms around content warnings, alt text, hashtag usage, thread etiquette, and more. These norms were often unwritten, learned through participation in comparatively small communities where people knew each other. When the population grew by orders of magnitude, those norms didn’t scale with it. There was no infrastructure to onboard newcomers into them. The new arrivals were not being taught; they were being expected to already know.
The response from much of the incumbent population was, understandably, frustration. People who had built something felt it was being overrun. But frustration without a constructive channel tends to curdle. It can stop us from seeing other choicees, and may leave us feeling like there were no choices at all. Justified burnout and ire lead to what some have come to call a “Fedi HOA” culture: hair-splitting interpretations of norms that felt, to those on the receiving end, like their intentions and learning path were being borderline weaponized.
For example, many of us have seen situations where a conversation unexpectedly escalated in visibility, and rather than reaching out to the relevant moderation teams to de-escalate, entire instances were blocked. Sometimes the mods (or admins) themselves were involved in the conflict itself. These scaling problems were felt as acts of aggression. These by type may be a more dramatic example, but the everyday version is equally as pervasive: people being yelled at for not using content warnings rather than being asked to use them. The newcomers were not told what was wanted from them. They were punished for not already knowing. Incumbents were exhausted, trying to bring newcomers into the fold. And on and on the wheel turned.
Here is the uncomfortable question: did all of this work?
If what we tried had been effective, we would now have 100% consistent usage of content warnings, alt text, and hashtag consistency across the Fediverse. We do not. The behavior that felt right, maybe even righteous, of correcting people loudly and publicly, did not produce the outcome it was meant to produce. It produced a population of newer users who were socialized to expect abuse rather than receive guidance. And when newcomers learned to ignore the torrent, they also missed the message.
The Patterns That Persisted
Some of the maladaptive engagement patterns that emerged from this period have calcified into features of how people interact on the Fediverse today. We want to name two, because they illustrate how legitimate needs can generate responses that don’t actually serve those needs.
The first is inconsistent expectations around what degree of diligence someone should read up on all other parties in a thread. People carry a considerable amount of energy into interactions with the presumption that others should have reviewed their biography, their pinned posts, their history before engaging with them at all. And when someone interacts without that context, those who feel unseen and unheard often treat others as if they have been personally affronted.
The underlying need is real. People want to be understood. They want their context to be respected. But expecting every person who encounters your posts to research your biography before interacting is not scalable. It never was, and it certainly is not now. Being angry at an individual for failing to do something that people do not consistently do directs frustration at individual people for a systemic impossibility.
The second is the rise of tools like Do Not Reply cards. These exist to solve a genuine problem: someone posts a question to the public internet, say, “people who have experience with $TOPIC, I’d like to ask…” and everyone answers, including people without the relevant experience. The responses are unhelpful, the poster is overwhelmed, and the signal is drowned in noise.
The maladaptive solution: cards that tell people not to engage with your public posts. Essentially: as a community, we have started posting on the public internet to tell people not to interact with us.
We say this not to mock the impulse. The frustration is legitimate, and the boundary is reasonable. (We even talk about it in our Docs.) But the mechanism is not working as well as people need it to. It is an expression of frustration dressed as a solution. It does not build the connective infrastructure that would actually address the underlying need. And it normalizes a posture of preemptive hostility toward engagement itself, the very thing that online community is built from.
If you use these tools, or if you carry the expectation that others should research you before engaging: we are not asking you to stop having those needs. We are asking you to sit with the question we posed earlier. Is it working?
The Smallest Scale
The same pattern plays out interpersonally. We were recently privy to a situation on the Fediverse involving attribution norms where the phrase “stealing to share” was used. The parties involved interpreted the situation differently, the interaction escalated, and multiple moderation teams became involved. We are not going to recount the specifics or adjudicate who was right, because the specifics are not the point.
What we want to talk about is the pattern. These types of interactions, where a norm in transition meets people with different contexts and expectations, tend to follow a predictable trajectory. Someone perceives a violation. They respond with accusation or correction. The other person, feeling attacked, becomes defensive. The defensive response is read as doubling down. Escalation follows. By the time it’s over, neither party has gotten what they actually needed, and the original issue (in this case, attribution) has been buried under layers of conflict.
This trajectory is not inevitable, but it is common enough to be worth examining. Accusation, even when justified, activates self-protection. Self-protection is not understanding. And understanding is what is actually needed for someone to change their behavior. If the goal is for people to share with attribution, then the response that serves that goal is the one that communicates it clearly: “please credit me when you share.” The response that is least likely to achieve that goal is the one that triggers a defensive reaction and ensures the person never hears the underlying request at all.
This does not mean that the person who feels wronged is at fault for the escalation. Sometimes you communicate clearly, you make a reasonable request, and the other person still doesn’t hear you. When that happens, that is on them. You can choose other tools that available to you at that point that are not esclatory, such as: disengagement and contacting moderation (reporting the behavior, contacting the relevant moderation team). We will talk more about this in our next Moderator Minutes, but we want to name it here: choosing community care does not guarantee care in return. It is still, in our view, the better choice. Not only because it is more likely to produce the outcome you want, but because the practice of choosing connection over punishment is itself part of building the community we believe that we all want to live in.
Two Reactions
Back to the topic at hand, across all of these scales (the ecosystem-wide migration, the persistent patterns, the individual interaction) there are two common response patterns:
Reaction A: correct and punish. Yelling about content warnings. Using content moderation as a tool for retaliation, via blocks and so forth. Treating colloquialisms as transgressions. Responding to perceived norm violations with accusation rather than communication. These responses share a common thread: they express what someone doesn’t want without communicating what they do want. They create conflict in the space where connection could have been.
Reaction B: connect and guide. Reaching out to moderation teams to help onboard newcomers and de-escalate conflict. Telling someone directly what you need from an interaction rather than punishing them for not intuiting correctly. Responding to “I’m going to steal this to share!” with “please credit me when you share with your friends!” Sending requests to moderation teams to please talk to their member about respecting boundaries. These responses share a different common thread: they lead with intention. They identify the actual gap and offer a path across it.
Reaction B is community care. Reaction A, however understandable its origins, is not.
We are not suggesting that Reaction B is easy, or that it should be the default in every circumstance. There are bad-faith actors for whom connection is not the answer, and we will address that directly in our next Moderator Minutes. But for the vast majority of these collisions we see, the person on the other side of the interaction is not acting in bad faith. They are navigating norms that are shifting under their feet, just as you are being exhausted by the same.
When Norms Become Weapons
The dual nature of shifting norms carries a harmful corollary that we need to name explicitly. One of the ways that queer and Black people experience harassment online is not always through direct hostility (slurs, threats, overt bigotry). It is through the selective and disproportionate enforcement of rules and standards.
What this can look like: if a rule exists, queer and Black community members must abide by it more scrupulously, and will be held accountable more harshly for perceived transgressions. The examples above are relatively benign, misinterpretations and scaling failures. But the same mechanism scales toward something that is used as a vector for harm. When norms shift, they do not shift uniformly for everyone. The same behavior that is overlooked or forgiven in one person becomes grounds for a report when performed by someone from a marginalized community. The rule itself may be neutral in its text. Its application is not.
We want to be clear: this is a form harassment. It may not look like a slur, but holding queer and Black people to a different, and often impossible, standard is a form of harm that is both pervasive and difficult to name, precisely because it cloaks itself in the language of fairness and rule-following.
We raise this here because it is inextricable from the conversation about norms. As our community develops and refines its standards for engagement, we must remain vigilant about who those standards are being applied to, and whether the application is equitable. Rules are tools. Like all tools, they can be used to build or to bludgeon.
Choosing How We Respond
We have spent much of this post describing what can go wrong. We want to close with what can go right.
The question we asked you to carry, is it working?, is not meant to shame anyone. It is meant to open space for a different kind of honesty. Many of us have invested significant emotional energy in behaviors that feel right but are not producing the outcomes we want. That is not a moral failing. It is an invitation to try something else.
Reaction B is not just a better response to any single situation. It is a practice. It is the habit of leading with what you want. The habit of assuming the person in front of you is capable of growth rather than deserving of punishment. The habit of asking yourself, before you hit “post,” whether your words are building the community you want to inhabit.
This is not naivete, and it is not asking you to extend infinite grace to bad-faith actors. That is a different conversation, and one we will address next month. It is asking you to extend considered grace to the people around you who are, like all of us, navigating norms that are shifting under their feet.
What if we chose now to stop engaging in behaviors that are not, or no longer, serving us and instead invested in trying new ones that might?
A Question for You
We’d like to close with something for the community to sit with:
When you encounter a norm in transition (something that used to be fine but is now contested, or something that used to be unacceptable but is gaining new context) how do you decide how to respond? What helps you lead with curiosity rather than correction?
We’d love to hear your reflections. Last Moderator Minutes we started a discussion via a Github Issue, this time we’ll actually point you to our Discord‡. In our next Moderator Minutes, we will be discussing what happens when the impulse to act on something distressing meets the realities of online safety, and how community care applies when the stakes are higher than the examples we explored here.
As always, processes grow over time, and this conversation is no exception.
‡ Discord: we’re actually in the process of migrating out of Discord to Zulip! We’re not doing the final leg of the proces until the moderation team feels appropriately comfortable and confident with the new tools, though it’s probable that future discussions will be in Zulip so stay tuned.
A Minute from the Moderators
How we can support our communities
Hello and welcome to the new year! I hope everyone was able to find sources of rest and recouperation towards the end of the year. As we kick things off, I’d like to talk about community support.
As technologists, we care about the open source ecosystem. As people invested in decentralized spaces where others can connect and grow, we care about the sustainability of the platforms that bring people together.
Something I’ve been seeing across all of these fronts is the rise of burnout.
Burnout creates its own forcing function. As ecosystems shrink, fewer people remain to carry things forward. If the work doesn’t also change to accommodate that, then each remaining person’s task load grows. This means that burn out can spiral, and spiral faster.
I see more people discussing concerns that their third spaces are shrinking or disappearing. In the physical world, some of this was driven by the pandemic. Smaller gathering places like cafes and community centers struggled when people couldn’t meet in person, and not all of them recovered. Surveys find that roughly half of adults now report experiencing loneliness, with young people seeing an especially sharp drop in time spent with friends.
In online spaces, we see something similar, but perhaps with a different cause. As people feel greater economic uncertainty at work or greater demands at home, we’re all less likely to give of ourselves to community spaces—not because we don’t value them, but because we simply don’t have it in us.
But: what if we did (have it in us)?
I want to pause here for a few moments of reflection.
First, I want you to remember moments when you felt the most joy. These don’t need to be work-related, or even open source / volunteer org related. Anything in your lifetime, no matter how long or fleeting. Think of past conversations, places, or other moments. Whatever comes to mind, just take your time.
Now, I want you to look for what your moments of joy have in common. Was it connection? A sense of accomplishment? Being seen, or seeing others clearly? Feeling part of something, or feeling free of something? Being able to relax and let your guard down? Make a mental note of any common internal experience you have amongst them.
Now, a second set of thoughts. This time about projects, communities, or other volunteer work. While for many of us here on Hachyderm there may be open source / tech communities in here, I want to emphasize that you do not need to constrain on these unless you wish to. This question is intentionally as broad as you need it to be.
One last reflection exercise: how have things been lately, in your honest assessment?
Have you wanted to do something you couldn’t? More time with loved ones, time to read, to feel the sun or touch grass? Do any of you feel like you might have “time”, in terms of minutes on a clock, but not “the time”, as in no emotional space inside of you?
If any of this resonates, you’re not alone. You’re not failing. A lot of people are sharing similar thoughts and feelings. Feeling like they take actions that don’t have results. Working hard with no, or insuffient, outcome. Participating in community but not feeling connected.
Why this exercise?
The reason I wanted everyone to go through this exercise is to help us all remember that we’re not alone. And that while we on Hachyderm, and many online spaces, welcome volunteers that it helps us help you if you are able to tell us your wants and needs.
When you want to volunteer somewhere, or just generally participate in a community in some way, The Place usually knows What They Need from you. In the case of a social media instance, these are usually tasks that support people supporting each other (handling reports, disagreements, etc.) or support technology that supports people (software updates, server maintenance, security, etc.).
Collaborating together means being able to discussing the intersection of “skills you bring” with “meeting community needs”, but also being able to communicate what brings you joy, and when you need rest, especially in times like what we’re all currently experiencing.
To the point: stepping up to volunteer your time is a gift to others. And being able to know when you need to step back and/or ask for change is a gift to yourself.
Both of these are legitimate. Neither is failure.
Stepping up
Volunteer labor is measured in seconds and spoons.
There are a lot of calls for action out there, and it’s both possible and likely that there are more situations you wish you could share your skills and time with than you’re actually able to. This is okay. It’s a good opportunity to learn more about yourself and to practice having boundaries. After all, a sustainable you is better than a you that’s spread too thin and burning out.
When you’re assessing whether to join a new effort, ask questions of yourself first. Not just “how much time can I devote per week,” but “what do I need to know” so you can better determine how much you can give and whether the organization’s needs match your skills.
Not all time is created equal. As someone who used to take on-call rotations, I used to joke that one minute of incident time is one year of real life. The stress is higher, the pace is higher, everything takes more. There’s a reason organizations with healthy incident response culture ensure people can take time to themselves after a shift with an incident—even if they were scheduled to take that shift.
As you better understand how much time and emotional energy is needed from you, you can not only better decide your capacity but also better communicate the boundaries you need.
Stepping back
Stepping back doesn’t have to mean dramatic exit. It can mean doing less, doing differently, taking a defined break, or shifting into a different role. The key distinction is to step back with intention instead of collapsing from exhaustion. Making choices with intention not only helps you, but also helps give information to the community (or organization) that you’re working with.
If you find yourself overcommiting because you’re worried as you watch your communities struggle: that is absolutely a hard choice. But it helps both you and others to say “not right now” or “not this”. The spaces you’ve helped build do not require your depletion as the price of membership or community. (And honestly, if they did would you want to participate in that environment?)
In the broader open source ecosystem, there’s even data around this. Tidelift surveys show a consistent 60% of open source maintainers either have quit or consider quitting. This means it’s not individual weakness, it’s something we can choose to normalize doing with intention, communication, and without shame, so that communities can adapt rather than being caught off guard.
Asking for change
If you’re volunteering in spaces that you’d like to stay with changes, rather than cutting back, this is both similar and different: you still need to ask for what you need, the needs are just shifted.
Being successful with these types of requests requires knowing what’s depleting you specifically, not just feeling generally exhausted. It requires being able to say “I can do X but not Y” or “this structure isn’t working for me” or “I need this to change in order to continue.”
It also requires being in a community that can receive that. Not every space is ready to hear what its members actually need. But communities that want to survive have to become places where this kind of honesty is possible. Where people can say “this isn’t sustainable for me” without it being heard as complaint or received as abandonment.
If you’re in a position to ask for change, I’d encourage you to be specific. Not “I’m burned out” but “weekly syncs are depleting me and I’d like to try async updates.” Not “I can’t do this anymore” but “I can continue doing documentation but I need to stop doing issue triage.” When you are able to communicate what is contributing to exhaustion or burnout, this gives your community the ability to change specific things and removes guesswork.
How this builds collective capacity
Communities can’t allocate resources they can’t see. If everyone is performing sustainability while quietly running on empty, the system has no signal to work with. It can’t route around problems it doesn’t know exist. It can’t offer support to people who haven’t said they need it.
Honesty is a collective resource. It is something to be cherished and it helps the broader community understand its actual, collective, capacity. This also helps communities make decisions like “what can we actually sustain? What do we need to let go? Where do we need to recruit, restructure, or rest?”
The alternative is what we see too often: projects that seem fine until suddenly they aren’t. Maintainers going silent. Spaces that hollow out from the inside while the exterior looks unchanged. Communities don’t usually die from a single dramatic failure. They disappear from accumulated, unspoken depletion.
Coming back to joy
I asked you earlier to remember moments of joy, and to look for what they had in common. I want to return to that now.
The point of this reflection wasn’t optimization. It wasn’t about finding efficiencies or maximizing output. It was about remembering what it feels like when the things you do actually meet your needs. When actions and outcomes are aligned, and participation is restorative rather than extractive.
The communities and spaces that we build should be the things that sustain ourselves and others. Not every time and always. There will be seasons of giving more than you receive. But if a community is only ever drawing from you, never restoring, something is misaligned. And you’re allowed to notice that. You’re allowed to name it. You’re allowed to step back, or to ask for it to be different.
This is how we rebuild collective capacity: one honest assessment at a time. One clear communication at a time. One person at a time remembering that their sustainability and the sustainability of the things they care about are interconnected.
Quick housekeeping: manual application approvals
As many of you know, we’ve been on manual approvals for about six months now. The main reason for the shift was a dramatic surge in bot sign ups, or Human Sounding Automated Sign Ups.
As many of you are also reporting on an increase in bot traffic / spam overall, this likely doesn’t surprise you (and thank you for continuing to report those!). For those who haven’t encountered it directly, here’s an article we reference often that illustrates just how convincing these bots have become: The future of forums is lies, I guess.
We’ve been working hard on better ways to ensure that the accounts we approve are either for people or, at minimum, entity accounts that are clearly intended to be entities—projects, conferences, and so on.
As concerns around online safety increase, we’ve also been getting more questions about whether certain activities affect your application: signing up with different email providers, using VPNs, what happens if your application is denied and you’d like to appeal. I wanted to take a moment to address these.
The short answer, with context: When we evaluate applications, we’re trying to answer two questions. Is this account a bot? And if not, will this person be a good fit for our instance? This means we don’t have rules for or against the use of specific email providers, VPNs, and so forth.
So what is helpful?
On “bot or not”
Unfortunately, human-sounding reasons to join aren’t always helpful here as now bots write these with ease. That means applications that provide other “proofs of life” in addition to their Reason to Join can be processed more quickly.
Since we have a lot of technologists, this typically means things like GitHub or LinkedIn profiles, though it doesn’t have to be. If you have a pre-existing account you’re migrating from, even if you don’t plan to link them formally, mentioning it helps us look for bot patterns in prior activity.
On “good fit”
This is where your Reason to Join matters. Our number one rule, and our shorthand for following our Code of Conduct, is “don’t be a dick.” If your application tells us enough to know you’re a person and that you’ll follow the Code of Conduct by treating others with respect, that’s all we need.
Prior social accounts help here too. In addition or in lieu of that, having an existing member refer you is also a great way to expedite this process. It means that someone is willing to vouch that you’re not automated and that you’ll be good to others. This shortens the entire application process significantly.
On appeals
All denials are appealable. In many cases the outbound email tells you what to do, but the overall gist is: for most denied account applications, emailing us is a great way to let us know to take a second look at your application. Everythign I said before also applies here: anything you can provide that helps us distinguish you from a bot and establishes that you’re interested in positive engagement goes a long way.
Thank you for your patience
I think I can speak for all mods and instances by thanking everyone for their patience. Each instance is figuring out how to handle both the changes in account sign ups and other concerns, and it means a lot to us when people remember that we’re all trying to create a better, safer, online experience.
A Minute from the Moderators
How can you use mental health to protect yourself online?
Boundaries
Boundaries are a mental health tool for understanding your personal limits. If you feel like you are reaching your personal limits with regularity these days, you likely already know how important it is to not only have healthy boundaries but also have healthy ways of enforcing them.
To show by example, you may want to come online for cat pics and catharsis, but not see food if you’re struggling with an eating disorder - no matter how cute the cat eating their nom noms is. To handle this, you need mental bandwidth and experience actively nurturing yourself. This starts to get into topics that will exceed the scope of this post, but understanding if, when, how, and to what degree you are in control of meeting your own wants and needs is critical to our journeys in life. Mental health work gives us the tools and creativity for solutions like: “I will store a cache of my favorite, trigger-free, cat pics for when I’m just not well enough to be online.”
Why boundaries are important
Calm minds have a greater ability to respond to stressful situations. When we are pressured, we’re likely to make mistakes that cost us. Maybe we say that hurtful thing we didn’t mean, and maybe we click on links instead of typing them, missing homoglyph[1.1] attacks.
It is very common to create a sense of urgency when trying scam[1.2], as the scam relies on impaired judgement to work. The short version is that hijacking the amygdala[1.3], the portion of the brain involved in fight / flight / freeze / fawn, puts a person in a situation where they’re not primarily rationally making decisions, they’re doing so while in a heightened state of stress or other intense emotion.
Understanding this vulnerability is the first step toward protecting ourselves. When we recognize how stress impairs our judgment, we can begin to establish boundaries that help us maintain clarity even under pressure. Boundaries aren’t just about spam and scams, they’re also about recognizing and honoring our limits whether faced with malicious actors or emotionally triggering content.
Learning from prior experiences
Knowing our personal boundaries helps us navigate challenges. For the previous example: can you go online for what you want to accomplish without getting overwhelmed by triggering content? Take time to figure out if you’ll benefit more from engaging or if the stressful exposure will trigger your trauma, and what you can do to support yourself in trauma.
If you choose to engage, remember to prioritize your well being and practice avoiding self-judgement. You do not need to justify taking care of yourself or others. Filtering your feed, blocking sources, taking time before responding, or disengaging completely are all valid choices that need no explanation.
It might not be directly obvious why this is the starting point for talking about spam waves. Health boundaries matter most during a crisis, and we best practice them when we’re not in them (or not in a specific one). Spam waves are a type of boundary violation, where people want you to see or otherwise engage with content without your consent. You will likely also be asked to disclose personal information, click unfamiliar links, or engage in an unfamiliar process.
When we’re struggling to stay grounded, we might react the moment we see content like this. But what if we took a moment and looked again, with a refreshed perspective?
Grounding
Grounding[1.4] and emotional regulation start with recognizing when you’re having a stress response. Notice your heart rate rising? A pit in your stomach? Tight shoulders? Feeling a sudden wave of irritation or panic? Sit with that feeling and make note of it, so you can recognize it once more in the future when it reoccurs. Recognizing when this happens gives you the power to choose your next move deliberately instead of letting urgency push you into an uncontrolled reaction.
This matters because it helps you respond thoughtfully rather than impulsively. That urgent “Click Now” message in your inbox? Click Later. Phone calls, DMs, and so forth? Take small pauses to give you time to ground yourself, both mentally and physically. When you take time for yourself, you are better equipped to think clearly.
First steps for grounding and regulation for online safety
Boundaries around information are protective
There is a lot of common advice around the various types of scams that have become increasingly common for the past couple of decades. A lot of countermeasures for scams rely on teams working together to be effective by establishing trust and sharing information. For individuals, we read about how to recognize phishing links, not to click them, and not to give “certain information” to others.
“Certain information” is in quotes because groups, organizations, and so forth need to say what that “certain information” is, and put boundaries on it. This is why it is common for banks to put out statements like “we will never ask for your social security number or banking information over the phone or via email”. In this pattern, they tell you what “certain information” 1 ) that they will not ask for and 2 ) that is valuable to an attacker, so they probably will ask for it.
Since life is messy, it’s not often that there’s an easy button to press. Scamming is no different. There is often nuance in statements like the above, for example a bank may create boundaries around the conditions where they will ask for certain information. For example, if you call them they may ask for information for you to verify who you are, and if you receive the call, there should be information that you can use to verify the caller.
How does this apply to mental health?
Knowing what information to share is a type of boundary, no different than knowing your personal limits around when to take breaks and set other forms of limits. You need to decide for yourself what personal information you’re comfortable sharing, with whom, and when. Where you are able, deciding in advance helps you know how to navigate as a planned situation unfolds. It also helps you practice for unplanned situations, where you will need to determine this in the moment.
Bypass the request
I’ll admit (me, not Hachyderm), that sometimes rather than verify “real or not” for phone calls, I’ll just ask for a ticket number or similar that I can use, hang up, and then call whatever organization (e.g. bank) through an official phone number and route back in. This trade off in time massively reduces my own cognitive load, and reduces my personal risk when answering an unplanned phone call. Similar can be true of other forms of contact including email and social media.
Another form of “bypassing the request” can be to allow requests to remind you to take action in a way that you are comfortable with.
For example, as various crises escalate simultaneously, there are various individual and regional aid campaigns. If you see these requests, or even are directly tagged by them, you might feel overwhelmed trying to figure out which requests are for bots, other scams, or real people. Instead of trying to verify every request, consider this: if the cause resonates with you, support it through existing channels you already trust or seek out an official channel.
Seeing online fundraisers for a particular issue? You can choose to donate to a local organization or individual doing similar work that you know and feel comfortable with. You’re still giving your help to those who need it, just in a way that leaves you feeling peaceful instead of uncertain.
How does this apply to mental health?
Building skills to allow you to reduce your mental burdens and protect your emotional states are both critical to maintaining your wellbeing. Many of us don’t have unlimited spoons to do detective work, so using our energy and creativity to focus on how we can help ourselves is exactly the type of work we should be doing, and that is what this strategy focuses on.
Hachyderm commitments
Moderation communication
Part of the work that we as instance moderators need to do in light of various online scams is communicate to you what we will and will not ask for, and how we will or will not ask for it. This mirrors other industries that have also done education and awareness about what information they will and will not ask for and in what way e.g., “we will never ask for your account information via email”.
For Hachyderm moderation communications:
- Hachyderm doesn’t request or require anyone to click links for handling accounts.
- Hachyderm works to avoid urgency in moderation communications.
For the latter, while it is true that we can and have sent out time bounded requests, we have worked to ensure that the timeframes in those requests don’t create a sense of urgency or pressure someone to act against their best interests. We also try our best to remind people that moderation decisions are not permanent, and can frequently be reversed with appeals. Over the course of the next month, we will create documentation around what we will communicate and include it in our docs.
If you receive a request from the Hachyderm moderation team, you absolutely can verify the request either by DMing our main account (@hachyderm@hachyderm.io) or emailing us (admin@hachyderm.io). If it helps, a common pattern would be to verify a request through a different communication method than the one you were contacted from. For example, if you receive a DM from an account that looks like a moderation account, email the support address and vice versa. To practice avoiding copy-pasting any potential phishing links or other codes from the message you received, make sure you have either separately stored the relevant links or only copy-paste from official documentation if it is present. (Hachyderm’s contact information is on our About page and Docs.)
Scams vs legitimate campaigns
We also do our best to keep track of various campaigns and differentiate “real or scam”, to the degree that we are able. For campaigns that are identified as scams, we do our best to research and prevent that traffic from coming to Hachyderm. There are few well known campaigns, including but not limited to: impersonation scams to moderation / staff accounts, Jimmy Truth with other name iterations, and various automated scam campaigns[1.5]. A few of you have also done a wonderful job assisting us in research and detection for a few active campaigns, without being asked. Thank you so much for contributing to community safety! For those who are interested in helping out like this, even if you don’t have time to be a moderator, we always make time to help people submit reports of this nature without increasing risk to themselves or others on the platform.
A legitimate campaign
We also recognize that there are legitimate campaigns. One relatively new effort is the Gaza Verified project. I (Quintessence) spoke to Aral to ask questions and generally understand the process, and am comfortable confirming that 1 ) Aral is a real person who is doing the work he states and 2 ) that the people that are being listed on Gaza Verified are confirmed with in-person verification with the network that he and Joy are building. To be overclear: the work is being done, and being done the way it is being communicated.
In-person verification is slow work, as it requires each new contact to be verified by an existing contact. They also take the time to attempt to onboard people who mostly are unfamiliar with the technology we take for granted, and therefore both do not have prior exposure to cultural norms and also due to suffering, do not have a lot of mental bandwidth to “just learn it”.
How to help crisis groups
Whenever you see a group working to help people in crisis, whether it’s this one or others you already know, remember:
- Always ask the group how you can help, instead of showing up with answers first.
- Always make sure to quickly include what skills you have, so they can easily map them to areas you can help.
- Everyone can help people in crisis, it’s just a matter of the how.
“Everyone can help” doesn’t necessarily mean that everyone does a specific task or that everyone has one specific, trained skillset. Help is also approaching situations with empathy and care. As is remembering that you can choose your responses, by practicing good mental health hygiene. For example: recognizing when a new group of people 1 ) isn’t respecting established cultural norms and 2 ) having the awareness to recognize that there might not be a course or a doc ensuring that they do, means that you can choose how you want to move forward. You can choose to attempt to use shame[1.6][1.7] and harm others for not knowing what you know. You could choose to protect your own boundaries non-interactively, by muting or blocking until the situation resolves. And still further you could choose to actively help, by reaching out to the individual or group and offering what you know and why it’s important.
I realize I am being very verbose in that last example, but I do want to be clear: the rise of various global crises have caused many of us to lash out (“shoot first and ask questions later”) towards each other. Some of this is learned, having to scream on the Twitter-that-was to get your airline ticket refunded when the support email doesn’t work or having to submit your full address to sales just to ask a question about a product you don’t own but would like to know about without being followed forever, has caused us to internalize a lot of harmful patterns. I won’t continue to go into this here, as I will be expanding on it in the next Moderator Minutes, but it is important to start the conversation.
Question for Hachydermians
As an experiment, I’d like to end this post with an open question to the community:
What strategies have you found useful, that you’d like to share, to reduce your stress online?
To help make it easier to participate, we’ve made a Github Issue to serve as a discussion thread.
Resources
In-post
[1.1] Wikipedia article about what homoglyphs are
[1.2] How Fraudsters Build Scams and Use Urgency to Trick You
[1.3] Wikipedia article on Amygdala Hijacking
[1.4] VeryWell Mind: Grounding
[1.5] IFTAS Spam Fediverse Services (published 25 Oct 2025)
[1.6] Shame vs Learning
[1.7] Where Does the South End and Christianity Begin? Understanding the role of shame/honor culture in the roots of Christian rage. (Web Archive link due to soft paywall.)
General information about phishing and online scams
[2.1] https://department.va.gov/privacy/fact-sheet/the-four-ps-of-spotting-fraud/
[2.2] https://www.cloudflare.com/learning/access-management/phishing-attack/
[2.3] https://www.usmetrobank.com/wp-content/uploads/2023/06/Phishing-Fundamental-Warning-Signs.pdf
[2.4] https://consumer.ftc.gov/articles/how-recognize-avoid-phishing-scams
[2.5] https://www.verywellmind.com/9-common-scams-to-watch-out-for-8703530
A Minute from the Moderators
Hello Hachydermia!
It’s been a while since we had one of these, and we thank you for your patience. We have more posts queued up on additional topics, but as promised we’ve been handling a sign up wave so we wanted to take time to explain what we’re seeing and how we’re working on it.
As always: processes grow over time, and moderation decisions are appealable. In cases like account applications, especially with regard to verifying identity, we won’t typically accept an appeal via the Appeal button unless we explicitly request an appeal that way. When that happens, the email that we send you will explain how to appeal that type of decision. We’ll get into appeals in a moment, but first we want to explain a concept called “inauthentic activity”.
Inauthentic Activity
Inauthentic activity is a term that you may hear in moderation in a variety of contexts. To be clear about what we mean when using the term in this post:
Inauthentic activity is any activity that intends to mislead.
It is important to understand this concept, because like all things inauthentic activity has a spectrum. The most extreme cases of inauthentic activity are activities like: harassment, stalking, and so forth. However, there are less extreme forms of inauthentic activity such as fake accounts which are created to post spamming links or text.
Case in point: Nicole, Fediverse Chick
Many on the Fediverse have encountered inauthentic account creation already. A notable example of this type of activity involved a wave of nearly identical accounts across the Fediverse that is likely familiar to all: Nicole, the Fediverse Chick. These accounts typically shared the same display name (“Nicole”) and a nearly identical profile bio. “Nicole” accounts engaged in mass direct messaging, and often introduced themselves in a uniform, scripted way.
Though each account had a unique handle (evading simple filters), they functioned as a coordinated spam campaign. The accounts were not genuinely attempting to represent an individual named “Nicole”, they were created to distribute spam making them a clear case of inauthentic account creation. There are also numerous posts and analysis on the Fediverse regarding elements that indicated a potential targeted harassment campaign, compounding the nature of the activity.
What Hachyderm is seeing
So what are we seeing right now? The primary form of inauthentic account creation attempts we’re seeing on Hachyderm specifically are accounts that are created with the intent to post spam links and/or text. Most of the spam is what we’ll loosely call “relatively benign”. By that we mean they mostly do not appear to be attempts to phish, post traumatic or other forms of harmful content, and so forth.
While none of these types of spam accounts are new, the main change we’re seeing now is that more and more of the account creators seem to be using automation to generate “plausible reasons to join”. While there are more than a fair few that we suspect (or have enough text that we can confirm) are using AI text generation tools to “write a human sounding reason to join an instance”, simple scripting can also accomplish the same end. This basically means that historically it was more straightforward to determine if an account was a “bot or not” because, candidly, most bots prima facie looked like bots. Now that is no longer the case, so we’re continuing to improve our processes to adapt to this new reality.
How Hachyderm is currently handling applications
Right now we’re trying to find the right balance between reasonable friction to reduce inauthentic activity, while still allowing a smooth onboarding experience for new Hachydermians. We know this will introduce more friction than was present in the past, but we’ll continue to re-evaluate our decisions as different inauthentic activity campaigns occur, and we welcome your feedback on ways we could make this easier.
To help future Hachydermians and to provide better transparency, this post is to explain and set expectations on the process, its limitations, and how you can help make the process faster and smoother.
How we’re using the Mastodon tools
It’s important to understand how the tooling works to then understand how pending applications can be actioned. Right now, it is not possible to directly message a pending account on Hachyderm via Mastodon’s platform tooling while the account application is still in a “pending” state. That means there are two ways to try to contact account applicants:
- Attempt to contact the applicant via the email on the account application
- Still try to contact the applicant in-platform
While there are situations where we would try to reach someone via email, we generally prefer to do so via Mastodon. This is doubly true for cases of identity verification. Because it’s easy to create new email addresses—and many people use unique addresses for different services as a security measure—email alone isn’t a reliable way to determine whether an account is inauthentic
That means that we try to find alternative ways to contact applicants where we can. There are two things we are doing:
- If an applicant says they are migrating from a different account or Fediverse instance, we message that account to verify their identity. We will only do this by sending a DM (“mentions-only message”) from the official hachyderm@hachyderm.io account.
- If we need to contact the account holder for a different reason, we may need to “Approve” the account to get it out of “Pending” state, and then take a moderation action, such as a ”Freeze” or “Suspend”.
This process can feel confusing—particularly when an approval is quickly followed by a freeze or suspension. We handle it this way because suspensions and freezes can be appealed and reversed, whereas application rejections are final and can’t be undone. Until we have better processes or tools to manage this more cleanly, we’ll continue approving and then freezing / suspending suspected inauthentic accounts to leave room for correction if we’ve made an error.
How applicants and Hachydermians can help
For applicants
Writing at least a sentence makes it easier to determine if an account is a bot or not. You don’t need to write an essay, but one word reasons don’t really help the “bot or not” assessment. If a Hachydermian has offered to vouch for you, please include their handle as well.
If you’re moving instances, or are otherwise applying and referencing an existing Fediverse account either on Hachyderm or elsewhere, watch for a DM from our official hachyderm@hachyderm.io account to verify your application.
This information is helpful even if you’re not migrating accounts and are planning to either have two separate accounts or if you plan to eventually delete one. In either case, we can refer to / work with your existing account to do the necessary checks to approve your Hachyderm account application.
This is doubly true for entity accounts (projects, community based conferences, etc.) as we want to make sure that people are not creating third party accounts claiming to be managed by someone who isn’t managing them.
If you miss a DM from us or have otherwise haven’t heard from us in more than a few days, don’t worry! We may put your account temporarily into an “approve-suspend” state until we hear back from you. In this case, the email you receive will include what to do next.
If you believe that we’ve made a mistake, just let us know by sending us an email at admin@hachyderm.io. If you have other issues that you want to get a hold of, please read the “Reporting Issues and Communicating with Moderators” page.
For Hachydermians
If you know that you’ve recommended that someone joins our instance specifically, and you know them well enough to vouch for them, please let them know to include your Hachyderm handle as part of their application. When we receive their application we’ll reach out to you also to confirm that you did in-fact vouch for them. Please know that we do not share any 1:1 communications outside of the moderation team, so if you cannot vouch for them and/or have other information you need to provide, it will be kept in confidence. If you would like to report any other issues or if you need to get a hold of the moderation team, please review the “Reporting Issues and Communicating with Moderators” page.
Ensuring Hachyderm's Future: Improving Safety & Resilience through Strategic Placement of Infrastructure
Preamble/Disclaimer
This document has not been reviewed by a lawyer and must not be considered legal advice. Hachyderm and its volunteer staff will make a best effort to keep Hachyderm running and safe from government interference, but we cannot guarantee any particular legal outcomes.
That being said, we are going to do our best to provide a service that is resilient, available, and safe to use.
As a Fediverse user, we strongly encourage you to develop your own operations security (opsec) plan and evaluate your personal risk profile. If you’re not sure how to do this, we’ll follow up with a post/blog with reading material so you can think through and improve your online defense posture.
Finally, you are welcome to share this document and engage others in the conversation; you don’t have to have a Hachyderm account. As we begin executing on the plan, one key tenet is to share as much as we can so others can prepare their corners of the Fediverse.
tl;dr
Hachyderm operates primarily out of the EU. We will reduce our exposure to US-based companies and continue to place key infrastructure in the EU.
Introduction
Hachyderm has, over the last two years, established itself as a small corner of the Fediverse where approximately 54,000 users (~11,000 monthly active users) have made their fedi-home.
From our About on Hachyderm:
Here we are trying to build a curated network of respectful professionals in the tech industry around the globe. We welcome anyone who follows the rules and needs a safe home or fresh start.
We are hackers, professionals, enthusiasts, and are passionate about life, respect, and digital freedom. We believe in peace and balance.
With the outcome of the 2024 US elections, the United States electorate has signaled – confirmed? – a shift toward a strongly conservative government. Rightfully so, many people in the Hachyderm and Fediverse communities are anxious, worried, and fearful for the actions this new administration will pursue in the coming years.
It is not hard to envision a future in the US where new legislation, executive action, or court orders threaten the availability and even existence of Hachyderm and similar sites in the Fediverse.
Resolution
Hachyderm must continue to be a safe space for our community that is dependable, available, and secure.
Risk-model. To this end, we will use a risk-based model to reconsider the placement of our infrastructure components to increase the safety and resilience of our platform. In particular, we must reduce our exposure to providers and services that could be compelled by the US government to disrupt our ability to serve the community.
Diversified providers. While we identify our future configuration, we must also continue to hold dear the value of diversifying across providers to avoid the risk of service suspension through a single provider. This was a core architecture principle in the current iteration of Hachyderm, and it will continue to be one in our future configuration.
Always test first. Although we want to act quickly, as a matter of good infrastructure stewardship, all changes we are proposing *must *be tested first against hachyderm.wtf (our dev instance) before they are applied to hachyderm.io. This may require us to improve our infrastructure delivery pipeline (using this phase very broadly).
Share broadly. Finally, we must share our process, thinking, and learnings openly so that the rest of the Fediverse community can benefit. Where possible, we should also open source our infrastructure and scripts as code – this will require additional effort to sanitize things like secrets or Hachyderm-specific configuration.
Scope
While there are many other influencing factors that could affect Hachyderm, we are focused on the technical architecture and placement of infrastructure. For example, we will discuss where our media is stored, but we aren’t addressing the fact that our bills are paid from a US-based credit card and bank account. We will address those other operational risks in a separate document.
For the moment, we are also not addressing German political risks - we may expand the scope of this initiative based on the results of the planned February 2025 snap election.
Sites
Hachyderm’s infrastructure consists of several layers, designed to be modular, interchangeable, and replaceable with a reasonable amount of effort. Hachyderm operates two types of “sites”: the core site, and our edge sites.
Core Sites
The core site is where the Mastodon components, data and media are stored and processed. This includes components like the Mastodon software, our media storage system, and the Hachyderm database. Since this houses our data – multiple terabytes of information - the core site is harder to replace and would likely incur downtime if we had to create a new one.
Edge Sites
Edge sites are “points of presence” we deploy across the globe that help speed up access to the core. For example, a user in Osaka, Japan would connect through the Tokyo, Japan edge site which then connects them to the core.
Edge sites will store temporary copies of assets like images and content to speed up access for other users connecting to that edge. It’s a little slower for the first person to download the new viral catte.jpeg in a region, but then it’s faster for everyone else. Edge sites are designed to be lightweight and replaceable; if we lose the Fremont, US site due to a technical issue, we don’t lose any data. Users in the US are shortly – usually after about 30 seconds – routed to the next nearest site, in this case, Newark, US.
Current State (November 2024)
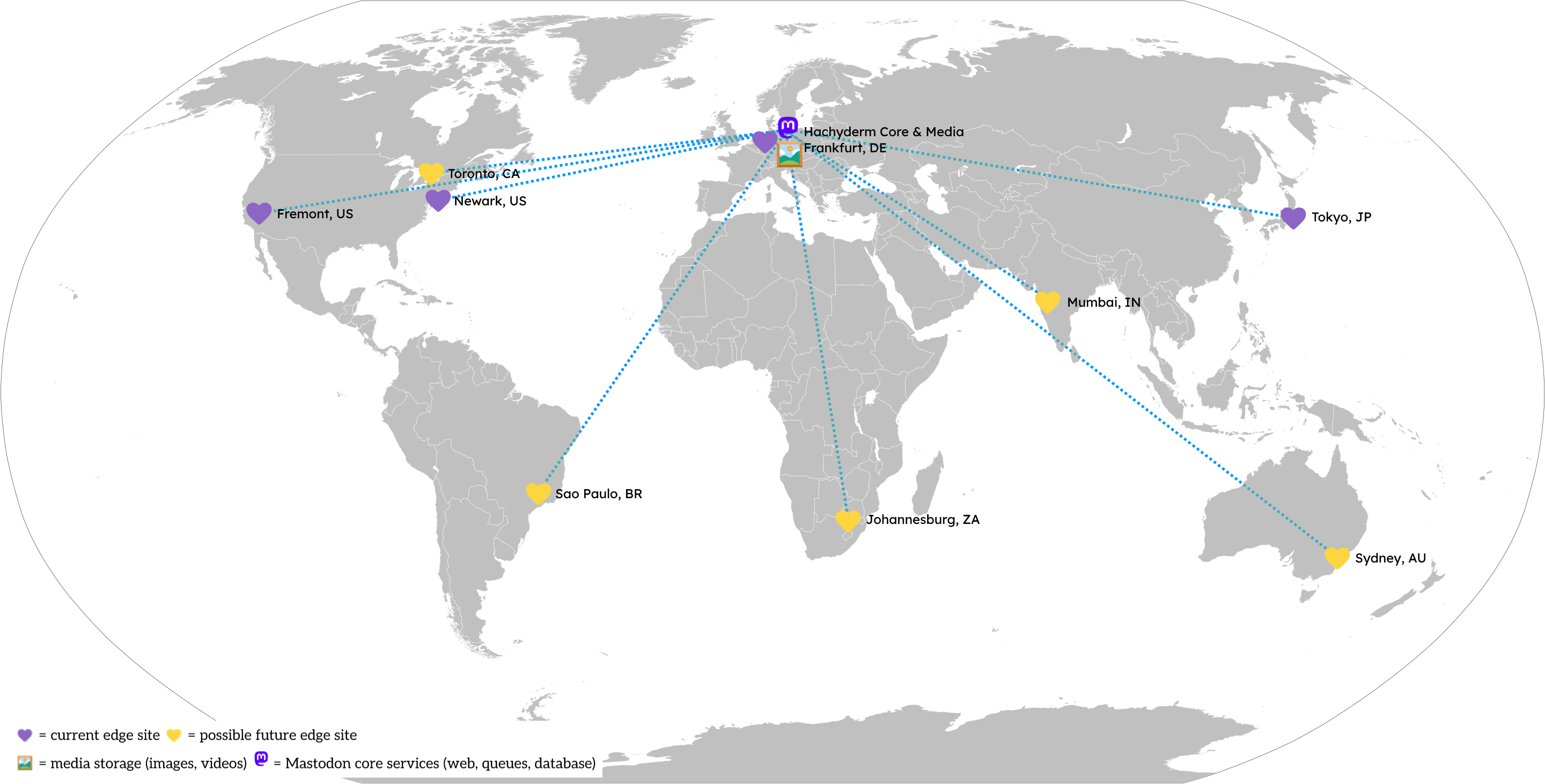
Our Core Site is in Frankfurt, Germany and operated by Hetzner (a German provider). In 2022, we chose to deploy to Germany due to the protections offered by laws like the General Data Protection Regulation (GDPR) that regulate how people’s data is processed and handled by providers. Since it’s harder for us to move or replace the Core Site – there’s a lot of data! – we put this site in a location that offered the strongest legal protections for free speech and data privacy. In hindsight, we reaffirm this choice and commitment to keeping our data in the EU.
As you can see in the map above, our current Edge Sites are spread across the globe, with two of our four current sites in the United States. All of our Edge Sites are provided by Akamai’s Linode platform, a US-based company. Since Edge Sites are easier to replace, making a “wrong” decision is much less costly. If we find the location of an Edge Site is no longer desirable, we build a new one and shift traffic to it.
A more detailed analysis is available in Appendix A: Infrastructure Component Locations & Providers, below.
Component-by-component Analysis
The next level down from a Site is a Component. Each Component provides a distinct feature to our users, whether it’s directly visible or not.
For each Component, we will assess:
- The impact should we do nothing and this component is affected,
- the likelihood of the risk being realized, and
- a relative sizing of the effort to reduce the risk both in the short and long term.
We’ll then provide a short-term and long-term recommendation for investigations, research, experiments, and actions we can take to mitigate our exposure.
Service Discovery
| Impact | Severely degraded, mostly **not** usable |
| Likelihood | Possible |
| Short-term effort | Small (1 month) |
| Long-term effort | Large (2 quarters) |
Service discovery is the ability for our users to find Hachyderm in a predictable and human-accessible way. These are the mechanisms that let you type “hachyderm.io” and find Hachyderm. If you had to remember “https://74.207.251.5”, you’d probably forget it pretty quickly.
Externally, Hachyderm depends on DNS for service location via https://hachyderm.io. Both our domain name registrar and DNS provider are Amazon Web Services, a US-based corporation. We use Route 53 Geolocation Routing to direct users to the Edge Site nearest to where the user is accessing Hachyderm.
Furthermore, the .io domain suffix has an uncertain future with the impending dissolution of the British Indian Ocean Territory.
Recommendations:
- Sooner
- Migrate DNS services to a non-US provider, or self-host
- Migrate hachyderm.io to a non-US registrar
- Consider leveraging Anycast-based providers, as a comparable Geo DNS provider to Route 53 might be hard to find
- Research implications of changing/adding new domain to a Mastodon instance (initial research indicates this is not feasible)
- Later
- Use one of our alternate registered domains in an EU registrar, or register a new hachyderm.tld domain with a non-US registrar and TLD
Edge Sites
| Impact | Inconvenient |
| Likelihood | Possible |
| Short-term effort | Medium (1 quarter) |
| Long-term effort | Medium (1 quarter) |
We currently leverage Akamai (who purchased Linode), a US-based company for our Edge Sites. Akamai has the advantages of being very affordable, established in many regions, and well-connected through their highly performant Internet backbone.
As previously mentioned, setting up a new Edge Site is a relatively quick operation.
Recommendations:
- Sooner
- Consider establishing additional edge locations in the US in “blue” states (both current edge nodes in the US are in California and New Jersey)
- Improve process to spin up CDN nodes & register them
- Consider establishing process for CDN nodes outside of Linode
- Adjust logging levels to retain for the minimum needed for day-to-day operations; ensure logs are shipped off-host to the EU for longer-term analysis
- Later
- Experiment with presenting Hachy through Tor https://docs.joinmastodon.org/admin/optional/tor/
- Consider establishing additional edge locations (no particular order):
- Johannesburg, ZA
- Sao Paulo, BR
- Mumbai, IN
- Sydney, AU
- Toronto, CA
Media Storage
| Impact | Inconvenient |
| Likelihood | Possible |
| Short-term effort | Small (1 month) |
| Long-term effort | Very Large (1 year+) |
Media is stored in Germany in an S3-like service provided by Digital Ocean, a US-based company. Despite the media residing in Germany, because DO is a US company, we could be exposed to service suspensions, although we hypothesize the risk of this is low. Suspension of media would cause a significant impact to our services, as many posts include images, videos, and audio as the main component of their message. We would also lose access to older media, which would disrupt historical preservation of messages.
We also store our weekly and incremental daily database backups with DO. Loss of our backups would make it difficult for us to restart service if we needed to rebuild the database from scratch.
Due to the size of the content (~23 TiB) and number of files, we consider this a hard-to-move component. We could, however, start storing media in a new location, or replicating to additional locations. Beyond this, we could consider a CDN-style delivery with multiple backing storage S3s. Fortunately, we “hide” the actual storage URL using our media.hachyderm.io domain, so assuming we did the work to move the media, storing media in a different location is a straightforward change.
Like the database, media storage is a bandwidth intensive application, and replicating to multiple providers could be costly due to costs increasing linearly with storage and egress bandwidth costs.
Recommendation:
- Sooner
- Identify non US-based corporations with S3-compatible storage
- Replicate database backups to an additional provider
- Establish a media retention policy and periodically expire Very Old media to keep the total size of our media infrastructure to a somewhat predictable size (vs. growing infinitely)
- Later
- Consider CDN-style delivery mechanism for media with write-through caching capability to store media in multiple backing stores across multiple providers
Hachyderm Core (Web, Queues, Database)
| Impact | Completely unusable |
| Likelihood | Unlikely |
| Short-term effort | Large (2 quarters) |
| Long-term effort | Large (2 quarters) |
The “core” Mastodon components – Mastodon web, sidekiq queues, redis, and database – are hosted in Hetzner in Frankfurt, Germany. In terms of exposure from the US, we classify this risk as significantly lower than our other providers.
We have recently established real-time replication from our primary database to a secondary read replica. In the event we lost our primary database, we could manually cut over to the replica with minimal disruption to service (est. < 1 hour).
Similarly, each of our redis instances (persistent & cache) are singletons and co-located on servers that perform other tasks like sidekiq. We could establish redis replication for each to improve resilience, and this could be taken further by doing so across multiple providers.
Naturally, as both redis and the database are high-throughput, latency and bandwidth sensitive components in our architecture, homing across multiple providers may prove challenging and unreasonably costly due to egress bandwidth charges.
Recommendation:
- Sooner
- Improve process to spin up mastodon web, sidekiq, and redis nodes in Hetzner
- Build redundant mastodon-web and redis nodes
- Research options for distributed postgresql, and identify potential additional providers that could provide near-local networking for establishing shards/hot spares
- Research German law requirements for content scanning for adult content
- Later
- Execute plan for hosting primary and secondary databases in different providers, if found to be necessary and reasonably cost-effective
- Establish process to spin up mastodon core infra in providers other than Hetzner
Internal Networking
| Impact | Completely unsuable |
| Likelihood | Unlikely |
| Short-term effort | Small (1 month) |
| Long-term effort | N/A |
Internally, we leverage Tailscale, which is a Canada-based corporation. They provide control and data planes, which includes API, PKI, and DERP relay servers. It’s possible they could be forced to suspend our service, which would break many internal communication paths. See their Terms of Use, particularly:
“4.4 Termination by Tailscale. We reserve the right to terminate these Terms and close your account upon notice to you in the event that we determine we are required to do so by law” (emphasis added)
and
“4.5 Effect of termination. Upon termination of these Terms, Customer’s right to access and use the Tailscale Solution will immediately end” (emphasis added)
We’ve asked Tailscale a hypothetical about the ToS here. Despite their response being somewhat tepid and noncommittal, this is balanced with the fact that Tailscale is a Canadian company, so a US court attempting to enforce an order in Canada would be challenging at best.
Given this context, we do not think there is significant risk from continuing to use Tailscale, and the benefits we get from them outweigh this small risk. In any case, we will research running our own control plane as a potential mitigation against this risk.
Recommendation:
- Short-term
- Investigate running our own control plane, like headscale
We also leverage Hetzner’s vSwitch capability in our core network. Hetzner; however, is based in Germany and not as exposed to US legislation.
Observability
| Impact | Partially degraded, but usable |
| Likelihood | Possible |
| Short-term effort | Small (1 month) |
| Long-term effort | Large (2 quarters) |
Our observability infrastructure (Prometheus, Grafana, Loki) is currently hosted on a single instance in Linode (esme.hachyderm.io) in their Frankfurt datacenter.
We also leverage Uptime Robot, based in Malta, to perform periodic synthetic checks that alert to our Discord.
Finally, we recently added honeycomb.io as a destination for OTel traces from Mastodon. We are currently storing tracing data in the US; however, Honeycomb offers the option of storing this data in the EU.
Recommendation:
- Short-term
- Automate stand up of observability infrastructure
- Move Honeycomb infrastructure to the EU
- Long-term
- Split components into distinct hosts
- Build redundancy into critical components
Other Supporting Tools
There are many tools that aren’t directly part of the above categories that help run Hachyderm. Most of these are SaaS solutions provided by US-based companies.
- 1Password
- Canadian company.
- Data stored in North Virginia, US.
- Lower risk.
- Stores both Nivenly and Hachyderm secrets.
- Recommendations
- Consider moving our instance to 1password.eu, which is in Frankfurt, DE.
- Consider an open source alternative like https://github.com/bitwarden/server.
- This would probably be a Nivenly project - not just Hachyderm, but we could act independently.
- Terraform Cloud
- US company.
- Lower risk since this isn’t a critical component, primarily for convenience & speed.
- Given Hashicorp’s embrace of the BSL license, we should stop using Terraform Cloud.
- Actions
- Consider open source alternatives like Atlantis - https://www.runatlantis.io/guide.
- Github
- US company based in California; however, Microsoft ownership could complicate this.
- Low-medium risk, primarily because Github is our main way to store infrastructure configuration.
- Our infrastructure configuration is stored at https://github.com/hachyderm/infrastructure. Today, this also includes secrets!
- In some cases, we use Github Accounts as identity (like for Grafana)
- Recommendations
- Short-term, extract secrets from Git and perform full rotation of all secrets.
- Evaluate Github Enterprise Cloud and its ability to store data in the EU. Would need to consider cost.
- Consider self-hosted Git like Gitea https://github.com/go-gitea/gitea or Codeberg.
- Once established, we must always fork projects and libraries we use from the open internet to our self-hosted Git.
- Let’s Encrypt
- ISRG non-profit based in California, US.
- Low-medium risk.
- terms of service
- “or to further unlawful acts” → what happens if LGBTQIA+ content becomes “unlawful”?
- “the Content is not pornographic, does not contain threats or incite violence, and does not violate the privacy or publicity rights of any third party;” —> definition of “pornographic” could change
- Recommendations
- Need to identify an EU-based alternative like https://www.buypass.com/products/tls-ssl-certificates/go-ssl (Needs research!)
- Could consider establishing our own Nivenly Intermediate CA that trusts up to a EU-based root. Could even consider a Nivenly Root CA based in the EU that we cross-sign this with. (high effort)
- Discord
- Today, ops are coordinated in Discord, a closed-source, US-based solution.
- Recommendations
- Consider a self-hosted, open-source solution like https://matrix.org/.
- This would likely be a Nivenly project given the scope (bigger than Hachy).
- Google GSuite
- Today, Nivenly (and Hachyderm) use Google Workplace for e-mail, calendar, and group e-mails. Many of our notifications and accounts are configured to use Google-based e-mail accounts.
- In some cases, we use Google Accounts for identity.
- Recommendations
- Consider a self-hosted, open-source solution like https://github.com/nextcloud.
- Unclear how Nextcloud App Store works re: open-source.
- Unclear what all experiences/use cases are supported – needs research.
- Talk - voice/video chat
- Office - google docs based on libreoffice
- Groupware - email, calendar, contacts
- Files - drivers
- Consider a self-hosted, open-source solution like https://github.com/nextcloud.
- Not very excited about the notion of hosting/maintaining our own e-mail server.
- This would likely be a Nivenly project given the scope (bigger than Hachy).
- SSH Access
- Today, we directly expose 22/tcp to the internet to allow operators to SSH in with SSH keys (no passwords).
- We also leverage Digital Ocean storage in Frankfurt as a staging place for our sshd public key file. Low risk.
- Recommendations
- Configure fail2ban in aggressive mode across all servers.
- Consider putting SSH behind Tailscale or other SSH-type bastion/proxy.
Appendix
Appendix A. Infrastructure Component Locations & Providers
In this table, we make a distinction between assets and the provider itself. For example, for Media Storage, we run Digital Ocean’s Spaces product in Frankfurt, Germany. Digital Ocean is a US-based company.
When determining our risk profile for a component, we are making the following broad assumptions:
- The safest posture is for both the asset and providers to be outside of the US.
- The next safest posture is for the asset to be outside the US but operated by a US-based provider.
- The least safe posture is for both the assets and provider to be in the US.
| Component | Asset Location(s) | Provider(s) & Country | Services Provided |
| Edge CDN |
| US - Akamai |
|
| Mastodon Web |
| DE - Hetzner |
|
| Mastodon Sidekiq (Queues) |
| DE - Hetzner |
|
| Mastodon Redis |
| DE - Hetzner |
|
| Mastodon Streaming |
| DE - Hetzner |
|
| Mastodon Postgresql (Database) |
| DE - Hetzner |
|
| Observability Metrics & System Logs |
| DE - Hetzner |
|
| Mastodon Media Storage |
| US - DigitalOcean |
|
| Observability Traces |
| US - Honeycomb |
|
| Connectivity Mesh |
| CA - Tailscale |
|
| Code Version Control |
| US - Github/Microsoft |
|
| Secrets Management |
| CA - 1Password |
|
Hachyderm's Introduction to Mastodon Moderation: The Report Feature and Moderator Actions
Hello Hachydermia and broader Fediverse! Thank you for your patience with this blog post, which is about Moderation Reports and Actions. It is significantly longer than the other blog posts will be in this series for a couple reasons:
- Multiple screenshots from the different menus and types of reports
- Responding to reports is one of the many critical activities of a moderation team
This blog post is also intended to function both as a blog post and as entry level user documentation for the Mastodon Moderation Report feature and the actions moderators can take. As already mentioned it is long, so there are two parts. This post is Part A and the next part will be Part B and focus on communication strategies relevant to moderation activity.
- Context setting
- Getting started
- Mastodon reports
- What users look like in the Mastodon Moderation UI
- What the moderation queue looks like
- What actions a moderator can take on a report
- Moderation notifications are heavily restricted as moderation is confidential
- Not all report data is stored permanently
- Report data cannot be aggregated by moderators
- Strategies for report data
- A quick hat tip to Mastodon v4.3
- A very, very quick summary of this post
- What’s next: tools to communicate about moderation issues
Context setting
In order for this post and future posts to make sense, we’ll be making use of common vocabulary and test users that we’ve created on a few instances. We’ll be introducing those users, and the common vocabulary, in the next section.
As mentioned in the intro, this post is focused on Mastodon Moderation Reports and Actions. So we’ll be covering:
- How to file a report (which is also in our Community Docs)
- The anatomy of a report (which is also in our Community Docs)
- What information is included in a report
- How long report data persists for (report data is not always permanent)
- Which moderation team(s) can see what report(s)
- What information moderators can see about users and how that differs between remote and local users
- What actions a moderator can take on a report and how that differs between remote and local users
- How to search what reports have been filed / How to see how many reports have been filed
Some things to keep in mind as you’re looking at the features in this blog post:
- Moderators can surface some data about reports, but not all.
- Moderators cannot forward a report directly to a remote team, but can create a new report if they determine the remote instance’s moderators should be made aware of a report that was not forwarded. The exception to this is if any “Followers Only” posts or DMs were included in the report, then they would not be visible to add to a new report.
- Moderation reports and actions are not shared between instances by Mastodon, which means remote users and remote moderation teams don’t have a way of knowing what actions were taken, against whom, or when.
- Local moderators see all locally generated reports, but only see remote reports if they were forwarded to them.
In general, the Mastodon Moderation Tools (not only the report feature) prioritize keeping information available to the local instance only, which again makes sense for user privacy. That said, there are other implications from this that we’ll be exploring in this post.
Getting started
Our test accounts
In order to show how different accounts interact, we’re using three test accounts. All test accounts are regular user accounts and do not have escalated privileges. Introducing:
@RedSalamander on Hachyderm.io, which is running Mastodon v4.2.10
@BlueOtter on Hachyderm.wtf (our test / canary instance), which was running Mastodon v4.3.0-alpha5 at the time of this writing
@PurpleHyacinth on Infosec.Exchange, which was running Mastodon v4.3.0-alpha5+glitch (the Glitch fork) at the time of this writing
We’re primarily focusing on “how things are today” with Mastodon v4.2.10, though we will call out visual differences as they apply and we’re taking screenshots. Moderation interface screenshots and screen recordings are all of v4.2.10 unless otherwise specified.
Necessary concepts
Local vs remote
Local vs remote is present for all aspects of Mastodon moderation tooling, not only Reports and Actions.
Local is local to the instance where the moderator has moderation privileges. i.e. Hachyderm users are local to the Hachyderm instance and Hachyderm moderators moderate the Hachyderm instance.
Remote is for users on other instances, or the entire instances themselves, that is not the instance where the moderator has moderation privileges. e.g. Both Infosec.Exchange and Hachyderm.wtf, and their users, are remote to Hachyderm.
Instances and servers
For the purposes of this blog post, we refer to “Mastodon instance” as the service people use and “Mastodon server” for what is running the Mastodon software (and its services). e.g. “The Hachyderm instance” would be where users log in, post, etc. and “the Hachyderm server(s)” would be what is hosting that instance.
Beyond this blog post, please be aware that in the broader Fediverse the terms “instance” and “server” are used interchangeably.
Home instance
Usually used when talking about a remote user, the user’s home instance is local-to-them. So for our test accounts, RedSalamander’s home instance is Hachyderm, BlueOtter’s is Hachyderm.wtf, and PurpleHyacinth’s is Infosec.Exchange.
Admin vs moderator
In some contexts, administrators (admins) and moderators are synonymous. This is especially common if an instance is using a Mastodon service and not self-hosting. In other cases they are different, the admins are those keeping the service online and the moderators are the ones managing the community - i.e. reports and so forth. In this blog post:
- “Moderator” means “anyone who makes and enforces policy decisions, either for individual users or instances”. (i.e. “Do they handle user reports and federation / defederation or not”.)
- “Administrator” means “anyone who handles the infrastructure running the Mastodon software and its dependencies”.
As a relevant aside, Hachyderm has separated the duties of moderation and server administration. This means that moderators can action reports but administrators can’t, and administrators manage the infrastructure but moderators can’t.
Scope of moderation
In this case, what we mean by “scope of moderation” is the scope of impact: user level and instance level. Instance level would be a decision made for or about an entire instance. User level is a decision made for or about a user. Distinguishing between “is this something that needs to happen for the whole instance” vs “is this something that an individual user or users should manage” is a big part of decision-making for any moderation team. Two examples:
- Defederating an instance that is a known bad actor on the Fediverse would be an instance level, or instance wide, decision. The impact is that no members on either instance can see each other’s posts and it also severs any following relationships.
- An individual local user decides to block a user (local or remote) or domain that they don’t like interacting with. The impact of this is specific to the user and not the rest of their instance. This is referred to as a user level decision.
Throughout this series we’ll make references to “instance level”, or “instance wide”, and “user level” when we discuss impacts and outcomes of decisions.
User actions vs moderator actions
It exceeds the scope of this blog post series, but we did want to be explicit that users do have a level of moderation control about their own account. Individual users can not only mute or block other users and filter in or out keywords and hashtags, but they can also block (defederate from) entire domains as well. This allows you to have more granular control for your individual account.
Mastodon reports
How a user generates a report
Local user reporting a local user
Note: the video should play at 720p or higher by default. If it is blurry for you, please change the Quality setting.
In the video above we can see that the user is reporting the post for violating Hachyderm’s Don’t Be A Dick rule. Let’s see what Hachyderm Moderation sees in their report:

This example demonstrates:
- The reporting user
- The rule violation they selected
- The comment they wrote
- The post they reported
Local user reporting a remote user
Note: the video should play at 720p or higher by default. If it is blurry for you, please change the Quality setting.
Again, we can see the user was reported for violating Hachyderm’s Don’t Be A Dick rule. But what do the moderators see? Let’s take a look.
Hachyderm.io Moderation

Since RedSalamander is on Hachyderm.io, the Hachyderm.io Moderators can see:
- The reporting user
- The rule violation they selected
- The comment they wrote
- The post they reported
This is the same as before.
Hachyderm.wtf Moderation

RedSalamander is not local to Hachyderm.wtf. So the Hachyderm.wtf moderators see:
- The originating server name only, not the specific user on that server who filed the report
- They do not see the rule violation that the user selected, the report is categorized as “Other”. Remote reports will always be categorized as “Other”, regardless of whether the user selects a rule violation, spam, or legal.
- They do see the comment that the user provided
- They do see the post that was reported
We will be diving into the nuances of local vs remote as we dig further into the Report structure itself and the actions that moderators can take. The main takeaway here is that remote moderators will see less information about the reporting user and the category they select than the reporting user’s home instance will. In fact, the report category will always show as “Other” no matter what is selected.
We’ll be covering the structure of these reports in the next section.
Side note: since Hachyderm.wtf is testing 4.3.x right now, there are some minor layout differences between the Hachyderm.io and Hachyderm.wtf report screenshots.
Forward report “to all”
When choosing who to file a report to, a user can send a report:
- To their own moderators only
- To the reported user’s moderators only
- To all the instance moderators involved
This last option usually causes some confusion. Let’s think about our test users again:
- RedSalamander on Hachyderm.io
- BlueOtter on Hachyderm.wtf
- PurpleHyacinth on Infosec.Exchange
Let’s say that PurpleHyacinth on Infosec.Exchange says something problematic, BlueOtter on Hachyderm.wtf responds, and RedSalamander on Hachyderm.io reports the exchange without posting. This is what the reporting forwarding would look like:

You cannot opt-out of sending reports to your own moderators, as again local moderators see all reports. This is why Hachyderm.io is not visible here. The forwarding lists the instances of all users who are tagged in the thread of the post(s) reported.
The intent of the feature is to increase visibility of a problematic user to the moderators of all users involved in a thread rather than limiting it to only the reporting user’s instance moderators and the reported instance user’s moderators. This gives more moderators the ability to protect their instances from harmful content.
That said, for moderators not expecting this situation, it can be confusing to know if the report is “meant for you” and if you should action it. The short answer is that the goal is to help give you visibility into behaviors that haven’t been otherwise reported to you, and that you should action it (or not) according to your existing instance policies.
What your moderator sees in a report
Moderators see all reports generated by their own users, regardless of whether the reported user is local or remote.
Moderators see all reports generated by their own users and users also have the option of sending the report onward to both the reported user’s moderators and the moderators of any other instances involved in the reported posts. Involvement in this case is the home instances of the users tagged in the posts being reported.
Anatomy of a report

(We have some documentation about the anatomy of a Mastodon report on our Community docs as well.)
So let’s look at the sections. In the first section (above the Category header) the moderation team can see:
- The display name, user name with server domain, avatar, and banner image
- The date and time of the report
- If the report is local (like this one), the reporting user’s handle is displayed. For a remote report, only the domain of the reporting user is displayed (as shown previously)
- The status as Unresolved or Resolved
- The report status: forwarded (local only) or not forwarded (sent to one or more remote instances)
- The ability to assign the report to themselves (you cannot assign to a different moderator)
In the Categories section, the moderation team can see:
- Other
- Legal
- Spam
- Content violates one or more server rules, and then the rules themselves
- The comment provided by the reporting user, if any
In the Reported Content section, moderators can see:
- The post(s) being reported
Note that public or followers only posts can be reported and that a user can be reported for boosting problematic content.
For followers only / permissions limited posts: moderators can only see those posts in the report itself, they cannot view it by going to the post’s URL like they can for public posts. In situations where a report was not forwarded and the moderators believe it should be, this can create a problem as moderators cannot forward a report - they can only generate a new report and choose to forward that new report to the remote moderation team. This limits moderator ability to directly forward posts with limited permissions (though they can screenshot and email the other moderation team(s)).
The actions taken and moderator comments are at the end of the report. Since the available moderation actions differ between local and remote reports, we will cover that in the Moderator Actions section.
What users look like in the Mastodon Moderation UI
Local Users

This is what a local user looks like in the 4.2.10 moderation interface. Here you can see:
- The full profile text (user set)
- How many posts they’ve made
- How many followers they have
- If they’ve made any reports (local or remote)
- If they’ve been reported (local or remote)
- If they have escalated privileges (e.g. are a moderator or administrator)
- What their registered email is
- Selected language
- Join date
- IP address(es) where they’ve logged in (useful for finding spam patterns / multiple accounts created)
- When they last logged in
- Their login status (this means if they’re currently moderated, e.g. frozen or suspended)
- Any account notes
You can also see that moderators can take an action on an account directly, even without a report. If there had been any moderation action taken on this account, there’d be an Audit Log that would display right above the “Notes” header.
Remote Users

This is what a remote user looks like in the 4.2.10 moderation interface. As you can see they are mostly the same, except:
- There are fewer moderation actions available
- There is no personal data (email, IP address, etc.) available
These make sense. To send a Warning, you need the ability to contact the user - which you cannot contact a remote user. To Freeze an account you’re allowing a user to log in but not post, effectively, which is something you (as a moderator) can only do if you control their account.
Similar to the local user, if this user had a history where they had been moderated in the past, there’d be an Audit Log that would appear right above the Notes section.
What the moderation queue looks like
Reports by local users show the username of the reporting user. Reports from remote users show the server, but not the user name, of the reporting user.
 |  |
| Moderation queue from Hachyderm.io | Moderation queue from Hachyderm.wtf |
For the purposes of this example, both reports were forwarded to the home instance.
- In the Hachyderm.io queue, the Hachyderm user has reported the remote user BlueOtter at Hachyderm.wtf and an unknown user from Hachyderm.wtf has reported the Hachyderm.io user RedSalamander.
- In the Hachyderm.wtf queue, an unknown user from Hachyderm.io has reported the local user BlueOtter and the local BlueOtter user has reported the remote user RedSalamander at Hachyderm.io
How to search for reports from an instance and regarding an instance
As you can see in the above section, the moderation interface allows you to search by the domain of the reported account, which is referred to as the target domain. To put it another way, if a Hachyderm.io moderator only wanted to see reports about Hachyderm.wtf users, they would search for Hachyderm.wtf in that search box.
The moderation interface does not currently allow for you to search for an originating domain (though work on this has started). If you wanted to see all reports from an instance, e.g. all reports originating from Hachyderm.wtf, then you’d need to run a database query (if you’re self hosting). The general query looks like this:
Report.where(account: Account.where(domain: 'example.com')).count
If the result is one or more, you can see the full URLs of the report(s) by running:
Report.where(account: Account.where(domain: 'example.com')).map { |r| puts admin_report_url(r.id) }
The query and output of the latter looks something like this:
> Report.where(account: Account.where(domain: 'example.com')).map { |r| puts admin_report_url(r.id) }
https://hachyderm.io/admin/reports/XXXX
https://hachyderm.io/admin/reports/YYYY
Where example.com would be changed to whatever instance you want data on and both XXXX and YYYY are specific report IDs.
As far as we know you can only run these queries if you are self hosting. If you are using a Mastodon hosting provider, you will need to reach out to your provider to see if you have access to run queries like this one.
Responding to requests for information
The only searchable information for reports at this time are the source and target domains. Basically, as a moderator you can answer the following very quickly:
- Our users have made N reports about users on Instance A and we have received M reports from Instance A about our users.
You cannot, however, determine how many reports have violated a specific server rule or that were marked as Other, Legal, or Spam. There also isn’t a way to provide additional tags to a report so they’re searchable by shared vocabularies, such as provided by IFTAS’s Shared Vocabulary List. (You can do this with your Blocklist / Moderated servers list, which will be discussed in a later post.)
As a moderator, make sure you set reasonable expectations with whomever is requesting information regarding what information you are able to share both due to what the platform allows you to find and what you are allowed to share under your terms of service, privacy rules, any regulations, etc.
What actions a moderator can take on a report
Moderation actions for local users
 |  |
| Default actions | Custom actions |
You’ll notice that there are some actions that can be either Default or Custom. Some actions are Default only and some actions are Custom only. In both cases a moderator can compose a custom message to the moderated user to explain the reason the action was taken. To quickly overview the actions:
- Mark as resolved: this closes a report with no action.
- Delete posts: deletes the reported posts
- Limit: does not sever any follower/following relationships, does limit post and account visibility
- Suspend: deletes the user (data is still in the system for 30 days)
- Warning: sends a message to the user
- Freeze: Allows the user to log in, but not post
- Sensitive: Marks all media posted by the user, images or video, as sensitive
On the Custom actions view, you can also see the option to use “warning preset”. This is another way to refer to canned messages. Basically if you are, as a moderator, sending the same message or messages with your moderation actions, you can create presets so you’re not typing them every time. Canned messages can only be accessed in the UI by navigating to a custom action (like in the screenshot) and clicking the “add warning presets” link under the Custom warning label. Alternatively, you can access them by the admin/warning_presets endpoint (e.g. example.com/admin/warning_presets ).
A quick example
Let’s take a look at what happens when you Limit an account in a report both either as a Default or Custom action.
Limit: Default action
 |  |
| This is what the moderator composes | This is what the user receives |
Limit: Custom action
 |  |
| This is what the moderator composes | This is what the user receives |
As you can see, in both cases the user receives the same email. So from a custom messages standpoint, you are able to send custom messages either using Default or Custom.
Moderation actions for remote users
 |  |
| Default actions | Custom actions |
The actions available for moderating remote users is similar, but not identical, to local users:
- Mark as resolved: this closes a report with no action.
- Delete posts: makes the posts not visible to your instance
- Limit: does not sever any follower/following relationships, does limit post and account visibility
- Suspend: defederates from the individual user
- Sensitive: Marks all media posted by the user, images or video, as sensitive
Note that neither remote users nor their moderators are notified of moderation action(s), so there are not options to send warnings or custom messages. There will be more about communications in the next post.
Moderation notifications are heavily restricted as moderation is confidential
The only way to know if any moderation action was taken on a report is to follow up with the moderator team or teams involved.
Something we want to directly call out is that a Mastodon Moderation Report is not like a “report ticket”, similar to some customer service platforms and/or Facebook support. This means that the following do not exist in platform:
- The user who created the report is not notified that it was sent, opened, actioned, or closed. This is not due to moderators opting in or out of this communication.
- The reported user will not see any reports generated against them, no matter how many there are or their sources (local, remote). Again, this is not due to a setting that users have or that moderators make for an instance.
- The only time a local user is notified is when their moderators take a moderation action (like sending a warning, limiting, etc.). They are not notified about the reports themselves.
- If the reported user is a remote user, they are not notified about anything at all. To be explicit: they are not notified when a report is generated and they are not notified about moderation actions taken.
- Remote moderators are not notified if another instance takes moderation action against one or more of their users. This is because user roles are not federated, all remote users are simply users. (For those that note that on some instances labels like “Owner” or “Admin” or “Mod” appear on a user’s profile: this is not federated. This is only displayed on the user’s profile.)
- Instance moderators only see their own report queue and information. There is no way for a remote user, even if they are a moderator, to see another instance’s report queue (to know what was sent to them) or know what actions were taken. They can only request this information from the other instance’s moderators.
This means that:
- No one has information about an instance’s moderation process besides that instance’s moderators, not even remote moderators or the user(s) who filed the report(s).
- So if you suspect you may have been moderated by a remote instance, you will need to reach out to that moderating team specifically.
- You can contact your own moderating team if you wish to have them relay a request on your behalf if that adds comfort and/or reduces stress. That said, to state it again, since role information is not federated they cannot answer questions directly as they don’t have any additional visibility to remote situations.
We will be covering moderation communication strategies in our next post.
Not all report data is stored permanently
Any change that results in a removal of data (delete post, suspend) causes that report data to be purged after 30 days.
The reason for this makes sense when you understand how posts are included in a report:
Posts are not “copied into” or “stored in” a report - they are linked.
Understanding this helps when trying to understand how reported posts persist, or not, in the report itself. Whenever a post is deleted after it is reported, no matter whether by a moderator or the user, it looks like this:
 |  |
| Report with post prior to user deleting post | Report with post after user deleting post |
30 days after the post is deleted it is removed from the report entirely. In this case, that means this report will appear blank after 30 days.
In the case where a user is suspended, the posts in the report would not show the red “deleted” text, the posts will stay in the report for the short term, but will still be deleted and therefore the report will also be blank after 30 days. (Suspended in this case means both when a local user is suspended and their account information is deleted after 30 days and when a remote user is defederated from.)
Report data cannot be aggregated by moderators
Usually more than one person sees a problematic post, what does this look like in the moderation queue?
Mastodon’s moderation interface has reported posts aggregated by user - regardless of the source of the report or the post or posts being reported. It looks like this:

At a glance, which of BlueOtter’s posts do you think are in these reports? Let’s take a look from the perspective of a Hachyderm moderator.
Here are the two reports originating from the Infosec.Exchange instance:
 |  |
| First report from Infosec.Exchange | Second report from Infosec.Exchange |
And now let’s look at the one generated locally by the Hachyderm user:

Here we can see that:
- The two Infosec.Exchange reports are not about the same post
- One of the Infosec.Exchange reports and the only Hachyderm.io report are about the same post
Something you may have noticed, that was also pointed out earlier in this post, is that both remote reports are categorized as “Other”. This is because the report type is not federated (for those familiar / to be explicit: the report category and rule violations are not federated with the Flag activity.)
As a moderator, you should expect all of your remote user generated reports to be categorized as Other. This is especially noteworthy if you’re running your own self hosted instance, as there are no local users (other than you), so in your case all of your reports will show as Other.
Moderators have some control over report categories
Moderators can change the report category. So if the report category needs to be changed, or set in the case of Other, this is something moderators can do.
Moderators cannot create new categories outside of the ones automatically generated as Rule violations. If you want to change the rules that are listed under Rule Violations, you must change the server rules at admin/rules. (If you are a moderator this is under Administration → Server Rules.) This means that the only categories that you can use are one of Other, Legal, Spam, or one or more Rule Violations. You cannot select more than one top-level category.
Moderators cannot analyze report data
Only the reporting (source) and reported (target) domains are searchable. No other data is searchable.
We stated this earlier, but wanted to repeat ourselves for a moment while we’re talking about changing report categories and moderator notes.
Moderators can use common vocabulary, like IFTAS’s Shared Vocabulary list, in their moderator comments. They can also choose to include other data, like demographic information regarding the report, in the moderator notes. This information is helpful when reviewing individual reports.
That said, Mastodon Reports cannot be searched by anything other than the reporting (source) or reported (target) domains. You cannot search or otherwise analyze data about Report categories or keywords (tags) used in moderator notes. You cannot search for individual report IDs either, though you can use them directly if you know the ID of the report you’re looking for by going to admin/reports/XXXX.
Make sure to set expectations about what questions are or are not answerable, not only by whatever moderation policies you have around disclosing user information but also around what you can use the tools to find.
For some Hachyderm specific information relevant to this section:
- We will not release individual moderation information or user data to others.
- A consequence of this is if there’s a situation where 2 or more users are moderated in an interaction, each user will only know what we’re asking of them, not anyone else involved. If there are enough users interacting in a situation where we are able to answer questions about the situation without calling out an individual user, we can disclose information such as “multiple users were moderated in this situation” and/or “we have temporarily moderated multiple users to enforce a cool down period”.
- We will, to the best of our ability, answer questions about reports. Our answers will usually be about general policies, in part due to the inability to surface category / type information about reports.
- We are willing to revisit moderation decisions when moderated users (or instances) reach out.
Some limitations for how reports are aggregated in the moderation queue
To put them in one spot, here are some of the limitations that we’ve covered for how the report feature and queue work today (Mastodon v4.2.10):
- Remote reports will always come through as Other, regardless of what the reporting user selects.
- Moderators can change the category of a report.
- Multiple reports about the same post are separate and cannot be consolidated.
- As a result, “one issue” may look like “many issues” (multiple reports on the same topic) or “many issues” may be “one issue” (multiple contexts in one report).
- Reports cannot reference each other. (For those familiar with GitHub, this would be similar to tagging a PR, Issue, etc. in comments and now you can see each PR or Issue from all the other PRs and Issues. For those unfamiliar with GitHub, you can see an example of this on Mastodon’s GitHub Issue # 31083.)
- Reports cannot be aggregated by the instance the reported user(s) are on (e.g. if you wanted to track if multiple reports are coming in for multiple users on the same instance).
- Reports cannot be aggregated to track a user that is creating multiple accounts on separate servers, typically referred to as sock accounts. (e.g. if you wanted to track sock accounts of a specific individual who is engaging in harassment)
- Important clarification: sock accounts are not the same as people who park user names on various instances.
- Reports cannot be forwarded from the moderation queue. So if a user has chosen to report to their local moderators only, and the local moderators decide it should be forwarded to the other server, they need to generate a new moderation report to forward to the remote moderation team.
- If the report contains one or more posts where a user is abusing the “Followers Only” feature of Mastodon, that report cannot be recreated as the moderators cannot see those posts to report. They will need to contact the remote moderation team through one of their contact methods.
Strategies for report data
In order to store moderation report data for greater than 30 days or to put information from multiple sources into one place, you will need to use some sort of third party tool. What tool or tools you use will depend on complexity and how much data you need to include.
- For simple reports, you may want to copy the plain text of the reported posts into the moderator comments. This way if you are asked about the reports past the 30 day mark, you can still see the original text even if the posts were removed and/or the user was deleted. (For 4.3.x - the report comment field is being expanded from 500 characters to 2000, so this will be even easier to do.)
- For more complex reports (such as issues that have multiple reports and/or corresponding emails to one or more parties) you will need to use some sort of documents that have access controls on them. Depending on your needs, Google Docs or GitHub’s Wiki on a private repo could work here.
- Google Docs and/or a GitHub Wiki or similar is also useful if your moderation team is generating their own report data or making / maintaining intelligence data about bad actors or instances on the Fediverse. Examples can include things like instances hosting illegal content or users that are making sock accounts across instances.
A quick hat tip to Mastodon v4.3
Although this post, and the rest of the posts in this series, are being written for 4.2.10 (and potentially 4.2.12), we want to acknowledge that there are feature changes that will be appearing in 4.3.x when it is released. For more information about which features, please follow mastodon/mastodon releases on GitHub.
A very, very quick summary of this post
- Mastodon moderation reports are a part of the process that allows moderators to maintain community safety.
- There are limitations to what information is available and to whom.
- While local moderators see all outbound reports, there are limits to what inbound reports may be sent in.
- Not all reports are directly actionable by a local moderation team, especially if it is a remote user who was reported. Moderators can contact the reported user’s moderation team for action.
- Moderators can contact their own users in-platform but not remote users or moderators.
- Moderators can determine how many reports have been filed from/about an instance, but not about what category.
- Moderators can determine what reports were filed by or about an individual user via their user profile in the moderation UI.
- Moderators cannot directly forward reports to remote moderators but can generate new reports if they believe the report should be sent and it wasn’t forwarded by the reporting user.
- Moderators should have a firm understanding of what data they can pull from the moderation platform and what information their policies allow them to share, so they can set expectations on information requests.
What’s next: tools to communicate about moderation issues
This post focused on the mechanics of how reports are generated, what information they display, and what actions moderators can take. Many users and moderators also need the ability to communicate with each other to ensure that the moderation process is beneficial to communities and does not itself introduce additional harm.
After that post, we’ll be providing another context setting post before moving on to the next sections of the moderation UI (order still being determined).
Licensing
Our blog posts and documentation are all under the CC-BY-SA 4.0 license, so please feel free to use and attribute them as needed.
Hachyderm's Introduction to Mastodon Moderation: Part 1
Hello Hachydermia! There has been recent, extensive, interest in Mastodon’s moderation tooling and moderation in the Fediverse in general. As part of that conversation, it became apparent that the built-in Mastodon moderation tools aren’t well known or understood. In the past, we’ve only provided a light amount of “Mastodon docs” type of documentation, for a few reasons:
- We didn’t want to host Mastodon project documentation, as that belongs with the Mastodon project.
- Due to software release cycles, documentation can become outdated quickly which would add to the burden of maintaining the documentation for software we don’t control (as we are not Mastodon maintainers).
- Since we are not Mastodon maintainers, it could also cause confusion with what the appropriate “source of truth” is if our documentation differs from the Mastodon project documentation.
For reference, Mastodon’s documentation is here:
https://docs.joinmastodon.org/
We also, truthfully, did not expect as much interest in the high level detail of How Stuff Works as there appears to be. All of that said: there is an interest, there is confusion, so we’re happy to help contribute to the corpus of information that makes being on the Fediverse better. This first post will be about expectation setting and some common themes we see, subsequent posts will be about specific tools (with screenshots).
Expectation setting
Some expectations for the blog posts:
- To state it again, none of us are Mastodon maintainers though we do have extensive experience with the tooling and do submit tickets to the Mastodon maintainers.
- All of these blog posts will likely be long.
- These blog posts are Mastodon specific and Mastodon is not the only tool in the Fediverse.
- As such, there is a variety of “what moderation tools are even available” depending on what type of Fediverse software is in use on a specific instance. We won’t be covering the broader Fediverse, only Mastodon.
- We will be showcasing the version of Mastodon that we are currently running, which is v4.2.10.
- We are not running any forks of Mastodon, such as Glitch or Hometown, so we will not be covering / discussing them or their peers.
- These blog posts will neither praise nor criticize Mastodon or the instances running it; they are simply providing information to help us all meet the situation where it’s at.
- There may be mention of third-party tools that we (Hachyderm) use such as email, GitHub, etc. Other instances may use different, but similar, tools in similar contexts. We’re not suggesting these as “one size fits all”, we’re only providing information.
- Due to the labor involved, each post will likely take a couple of weeks. We, like many instances on the Fediverse, are volunteer run.
Some context: a common paradigm we see
Before we focus heavily on “how do the moderation tools work”, we wanted to acknowledge and explain a common pattern we see a lot on the Fediverse:
Person A: YOU HAVE NO IDEA THE HARASSMENT I RECEIVE!
Person B: Oh no! Have you tried changing instances?
Person C: OMG is your instance not moderated?
Person D: I don’t see it? What are you even talking about?
Person E: Are you reporting these to your mods? People can’t fix what they don’t see!
Person F: Are you reporting these to other mods? People can’t fix what they don’t see!
Intentions behind Persons B-F aside, here are a few “did you knows”:
Limitations of “Oh no! Have you tried changing instances?”
- Did you know that when you migrate instances you lose your posting history?
- Did you know that migrating instances is not as simple as “create account on new instance, point old account to new account”? You need to export and then import data to keep your: followers, following, filters, and so on?
- Did you know that changing instances does not necessarily address the root cause of the harassment? In other words, harassers may and will try to follow targets to new instances?
Limitations of “OMG is your instance not moderated?”
- Do you know how the moderation tools work (highly relevant to upcoming blog posts)?
- Do you know the instance’s moderation process and policies (also highly relevant to upcoming blog posts)?
- In the case of moderation by reports, did you consider that when someone files a report they’ve already experienced the harm being reported?
- Regarding the previous, have you considered that some communities may have a higher risk of impact than others when it comes to moderation?
- Is the issue they’re experiencing systemic and omnipresent? If so, while moderation will help, it cannot stop what is happening by itself.
Limitations of “I don’t see it?”
- Are you a marginalized person? If not, then you’re not a target of what Person A is experiencing.
- Are you a marginalized person, but not the same as Person A? i.e. There are some types of hate that target specific demographics. If that’s not you, then you’re not a target of what Person A is experiencing.
- Did you know that depending on what your instance is or is not moderating on a server level influences what you see? Therefore if one or more sources that are targeting Person A are moderated on Person D’s server, then no one on Person D’s server will see those posts from their home instance. They’d need to log out to see them. (Moderator note: you can do this as an exercise in empathy, but please proceed with caution. Reply guys are not the only situations that are moderated on instances: instances also moderate violence, jump scare gore, CSAM, slurs, and so forth.)
- Did you know that you can choose to limit who can see your reply to a specific post to “followers only”? Did you connect that this same feature can be used to harass so that the only people who can see the harassment are the harasser and the target?
Limitations of “Are you reporting these to local or remote mods?”
- If a user needs to report their own harm, that’s additional harm experienced. (Our blog post with this topic.) So a report may prevent future harm from that same source, but reporting in and of itself won’t stop the next time.
- When you send reports, there are options on whom to send it to (more on this later). If you see, for example, a slur do you, as in you personally the ally who Wants To Do Good, know if that instance will moderate that? Do you know if the moderators for that instance use reports as vectors of harassment, screenshotting their report queues for their followers? With all this in mind: where do you choose to forward the report? (We’ll be revisiting this one again when we discuss reporting.)
- If you, Person E or F, are not on Person A’s instance, do you know how to send the report to their moderators either instead of or in addition to 1 ) your own moderators and 2 ) the offenders moderators?
Why this is important
Issues with All the Suggestions, Broadly
They assume that the problem Person A is experiencing is easy to solve. If it was easy to solve, then a better assumption would be that Person A would’ve done those things to protect themselves already.
How does this apply to moderation?
Visibility into how the moderation tools work will absolutely help people understand what actions are even possible. That said, it’s important to understand that good behavior, or “being a good citizen of the Fediverse”, is about more than what the tools are or are not doing. It’s about individual behaviors as well.
Shit, is it all hopeless? How do I/we help?
No, it’s not hopeless! We need to work together. Understanding what tools are available is only part of the solution. Our shared humanity, communication, empathy, and respect are required to do the rest.
Helping the Fediverse
- If you’re reading something that “you can solve” in 30 seconds or less, pause to see if there’s any information as to why it hasn’t been solved in 30 seconds or less already. This will likely require some searching.
- Whenever you have an idea to improve Fediverse tooling, look for existing solutions first. There are many groups working on Fediverse tools, and it’s better for the community to focus our energy and support on these existing projects rather than develop yet another one. Supporting projects run by marginalized groups is also important, as they are the ones that are on the receiving end of tooling abuse.
- Prioritizing existing projects also increases the number of instances that are using whatever that software is - more collective safety - than would be otherwise possible if you have it as your pet project.
Trauma-informed communication
- Don’t feel like you need to fix everything. A common response to bearing witness to another’s trauma is to try and fix it. We don’t want others to suffer. That said, you may not be offering what the other person or group is clearly stating they need. If they need you to listen, and you choose to act but not listen, then you have both not supported them in their trauma and violated a boundary. (Our docs page about mental health covers boundaries.)
- Don’t offer solutions you don’t have, especially things that fall out of your lived experience. Listen, learn.
- If you’re not sure, ask: does the person need someone to listen, someone to help, or some space? (This 30 second video can help. Apologies for the Facebook link, but that’s where the OptionB organization is.)
Clarifying your own communication
- Ask direct questions. If what you are looking for is a specific answer, like an outcome of a specific situation, asking very broad questions about policies in general or tooling in general will get you answers to what you asked for but will not answer the question you actually have.
- Assert boundaries when you need boundaries; request actions when you need actions. If you ask someone to leave a conversation when what you want is an apology, then when they (hopefully) respect your boundary you won’t have what you were really looking for.
What will be in our next post
In our next post we’ll be covering the report feature in Mastodon. We’ll specifically show:
- What it looks like when you report an issue
- What moderators see, and the difference between local and remote reports
- The different actions that moderators can take, which can vary between local users, remote users, and remote instances. (Yes, moderators can moderate individual remote users.)
- What communications come from the platform (or not) when moderation actions are taken.
In order to showcase the above, we’re going to generate faux reports using our main and test instances. As always, we look forward to your questions and feedback.
MastodonForHarris Hashtag and Mutual Aid Awareness Campaign
Hello Hachyderm! This blog post is a copy of a Hachyderm Announcement made by the Hachyderm Moderation Team earlier today. The purpose of copying to the blog is to make it more accessible, due to its length.
Hello all! We have somewhat long announcement from Hachyderm Moderation. Please read in its entirety.
We’ve been receiving reports that groups are using the MastodonForHarris / Mastodon4Harris fundraiser as a means to promote awareness around Mutual Aid - both in general awareness and in specific cases. We support people trying to bring awareness to the most vulnerable.
As moderators, we want to ensure that people are able to see the content they wish to see as long as isn’t harmful to others. This is the main “line in the sand” that would differentiate between us taking a server-wide action from individual users using the tools at their disposal to enforce individualized boundaries like muting, blocking, etc.
https://community.hachyderm.io/docs/hachyderm/mental-health/
As of right now, Hachyderm does not enforce a “correct” use for hashtags since hashtags are typically short lived and their meanings evolve rapidly. The three we do enforce are FediBlock and FediHire (Fediverse-wise) and HachyBots (Hachyderm specific):
https://community.hachyderm.io/docs/hachyderm/hashtags/#fediverse-reserved-hashtags
That said, as we are approaching a US election and a large percentage of our instance is US based, we will be proceeding through the coming months with caution to ensure that people can follow the news and conversations around the upcoming elections to the degree they wish to.
All posts, Mastodon(For|4)Harris or otherwise, will still be moderated according to our current guidelines. This includes posts that are not marked sensitive that should be, that have a false or misleading content warning (“jump scare”), bait-n-switch / deceptive links*, or posts that harass others. We have information about these on both our Content Warnings doc and the No Violence section of our rules:
https://community.hachyderm.io/docs/hachyderm/content-warnings/ https://community.hachyderm.io/docs/rule-explainer/#no-violence
One last reminder: as Hachydermians you are expected to respect boundaries, even in disagreement, and to walk away from engagements that go awry rather than escalating them. Do not enter into conversations that you’ve been explicitly asked not to, or have been explicitly asked to leave / disengage. Not all discussions “in public” are for all of the public to participate in. To put it another way, being on a social media site is very much like walking in Central Park - there may be events open to everyone as well as small private groups existing in public spaces. (So enjoy the public conversations and abide by wishes for private spaces in public.) We have this outlined in our docs as well:
29 July 2024 23:04 UTC
* Minor edit to explicitly call out deceptive linking.
Hachyderm and Nivenly
Hey Hachyderm!
We’re continuing to post on more important topics as previously promised. For today’s topic, we wanted to cover something that we know a lot of people have had questions about, the relationship between Hachyderm and Nivenly. Our discussion will focus on the relationship structure, our commitment to Nivenly, and our assurance to the community.
Structure of Nivenly and Hachyderm
The Nivenly Foundation is founded on the principle that project maintainers should share in their projects’ success. This foundation brings sustainable governance to open source projects and communities around the globe and supports the maintainers’ independent oversight of their projects. In addition, Nivenly is a decentralized, democratically-governed non-profit technical organization, that focuses on building an equitable future for technology communities.
In 2023, Hachyderm was transitioned from individual private ownership to stewardship under Nivenly. This transition helped to give the Hachyderm the financial structure needed to get to a stable point. This included access to a non-profit organization that can help facilitate donations and help us handle the legal requirements that come with scaling.
Nivenly’s relationship to Hachyderm is comparable to the Cloud Native Computing Foundation (CNCF) stewardship of Kubernetes. The parallels in our relationship do not stop at structure, but extend to our mission as well. Having accepted Kubernetes as its first project in 2015, CNCF provides a neutral home for Kubernetes, fostering its growth and ensuring its development through a community-driven, collaborative approach. This relationship has facilitated Kubernetes’ evolution into a leading platform for container orchestration, widely adopted in the industry for deploying and managing applications in cloud environments. Nivenly aims to enable the same growth in safe spaces through Hachyderm.
Our commitments to Nivenly
Our commitment to Nivenly is plain and simple: Ensure that hackers, professionals, and enthusiasts that are passionate about life, respect, and digital freedom are provided a safe space where they can find peace and balance.
While this is a tall order, everyone at Hachyderm believes and has a commitment to deliver on this vision.
Our assurance to the Community
Over the months, we have made a number of posts discussing the moderation process and the team as a whole. You can find more details from last May’s Moderator Minutes https://community.hachyderm.io/blog/2023/05/08/a-minute-from-the-moderators/. We won’t be rehashing the details of those posts here. Instead, we want to share with the community how our relationship with Nivenly impacts the decisions that we make as a moderation team.
We look to Nivenly for reassurance that we are acting in a way that aligns with the stated commitment. In addition, Nivenly supports us in ensuring that we have the support necessary to deliver on those commitments. However, Nivenly doesn’t otherwise participate in the day to day of Hachyderm’s operations. We firmly believe that this distinction is of utmost significance. By enabling Hachyderm to have the independence to operate independently, we can ensure the decisions that we made do the best to represent the community as a whole.
Disclaimer: There are people who volunteer at both Nivenly and Hachyderm, but their roles are separated by the tasks that they are completing.
The Israel-Palestine War
Hey Hachyderm,
Before we get started, we wanted to acknowledge that it’s been a while since we’ve written a blog post. Thank you for your patience! We’ve made a content plan and you should expect to see more activity through the blog starting this month covering a range of topics.
Today we wanted to discuss the ongoing war between Israel and Palestine. There are a lot of emotions tied to the conversation because it hits home for many of us.
Where We Stand
Firstly, we want to make it clear that we’re heartbroken by the violence and the loss of innocent lives, and we stand firmly against war. The devastation and suffering caused by this war are tragedies, and we believe in the importance of peace and understanding to resolve disputes.
Speaking Up, With Respect
We uphold the right of our community members to express their views and critique political structures. However, we feel it’s important to remind our community that the guidelines don’t allow for blanket statements or sweeping claims about religions or people of a specific faith. It’s important to separate the actions of a government from the beliefs of individuals.
When it comes to the Israel-Palestine war, we know religion is a big part of society for both sides. However, let’s not forget that religions aren’t defined solely by these governments, even if their leaders are prominent figures with loud voices. As moderators, we support Hachydermians when they need to vent or criticize situations and decisions. That said, sweeping generalizations and intolerance will not be supported.
As we continue to discuss this topic, let’s strive to promote understanding, empathy, and respect. Remember, behind every post and comment there’s a real person that we could learn from and grow with through respectful and open-minded conversations.
We recommend reviewing the Give Yourself permission section of our Mental Health and Boundaries document for help and ideas to support yourself when having conversations involving long term crises: https://community.hachyderm.io/docs/hachyderm/mental-health/#give-yourself-permission
Warmly,
Your Hachyderm Moderators
A Minute from the Moderators
We hope everyone had a wonderful and safe new year celebration!
In today’s moderator minutes we will be focused on the continuing conversations around Threads and how Hachyderm moderation is continuing to expand our collaboration with our community.
What’s going on with Threads?
Status
As of December 13, 2023, Threads has begun to test their implementation of ActivityPub. As of January 5, 2023, there are nine users from Threads are federating with Hachyderm’s instance. This is an increase of two users from our prior report.
When reviewing their available Terms of Use and Supplemental Privacy Policy provided by Meta, we don’t see any significant changes. This is not official legal or privacy advice for individual users and we recommend evaluating the linked documents yourself to determine for yourselves.
It’s important to remember a few things:
- The Mastodon/ActivityPub at their core uses a form of caching of information in order to make the process as seamless as possible. For example, when you create a verified link on your profile, every instance that your profile opens on does its own checks of the links and saves the validation on that third party server. This helps prevent malicious actors from falsifying their verified links that would then trickle out to other instances.
- We don’t transmit user IPs to any third party instances as part of your interaction. If Meta is able to collect your IP, it would be through a direct interaction with a post on their server or CDN.
For more details, review our original update about Threads
Limiting Threads
Based on user concern, we are shifting to a Limited status with Threads.
We have included the definition of limit below that comes from the mastodon documentation.
A limited account is hidden from all other users on that instance, except for its followers. All of the content is still there, and it can still be found via search, mentions, and following, but the content is invisible publicly.
What this means:
- You will still be able to follow people from Threads when they federate those users
- You will not see Threads posts on your timelines unless you follow the user
- You will be required to approve all followers from Threads
- You will be required to accept a prompt before viewing a Threads user’s account unless you are following them
Next Steps
As Threads continues to implement their integration with ActivityPub and the Fediverse at large, we will watch how those users integrate with our community and how their service interacts with our servers. If you would like to learn more about our criteria for how Hachyderm handles federating with other instances, please review our A Minute from the Moderators - July Edition where we list out our criteria.
Very, very quick Q&A on Threads
Q: What happens if there is a problematic account on Threads that is federating?
A: They will be blocked by our existing moderation policies.
Q: What happens if there are multiple problematic accounts on Threads that are federating?
A: Depending on the volume, we will either block all those individual accounts or Threads as a whole.
Q: I am concerned about anti-trans and other hate content that may come from Threads.
A: We are too! And we continue to monitor the instance for any of these behaviors. If and when that type of content appears, we will block it the way we do with any other instance.
Q: Why are you giving Threads “a chance”? We know about the parent company.
A: We’re not giving Threads “a chance” so much as meeting the current situation where it’s at with plans to continue to adapt as the situation changes. Since there are 9 users, we’re treating this instance like a 9 user instance. In cases with instances that are ~50 users or less, unless the instance is cohesive (e.g. examplenazi.com where they all espouse that ideology), we moderate individual accounts. This means that regardless of the status of Threads as a whole or the number of federating accounts, accounts like Libs of Tik Tok would never federate with Hachyderm for being in violation of our federating policy.
Community Collaboration
Community Votes
In the approximately 15 months since Hachyderm scaled, we have limited or suspended federation with 19 instances per month for a total of 285 instances. These instances in large part have been banned in order to pre-emptively protect our users. In almost every case, we know that these instances go against everything we stand for as a group. However, in a few of those cases, it’s more nuanced to determine if/when we should block an instance and how we should communicate those changes.
For example, if we blocked exampleillegal.com for illicit materials. We wouldn’t announce the change and we expect that none of our users will take issue with us blocking that material.
In contrast, on Jun 30, 2023, 22:12 UTC, we made the following announcement:
👋 Hello Hachydermia!
Due to the number of Twitter/Bird Site relay servers that have gone offline after the pricing update to Twitter’s API, we have recently started cleaning up servers that federate with our environment but appear to be offline.
If we removed a server that was functional and it has impacted your experience, please open a ticket on our GitHub issue page and we can evaluate reestablishing access.
Since making that decision, we had a few requests from users to re-evaluate 2 instances that we blocked but the other instances that we blocked remain blocked and the search box is clear of those invalid instances. While it was a change that was made for convenience and not protection, it is a change that had a large scale impact.
There are some cases that are more complicated and we would like to gather feedback from our community to determine which route best aligns with the entire community. We are releasing a new process to collect that information.
- Moderation team determines that we need a survey from the community
- Moderation team develops a multiple choice set of options for how to respond
- Moderation team will make a post informing the community about a survey
- A new announcement will be published
- Users will be able to respond to the announcement for 72 hours
- At the end of the 72 hours, the moderation team will collect the results from the community and close the poll.
This method isn’t perfect, but we are excited to continue to work on a method to collaborate with our community in convenient and meaningful ways.
Trusted reporters
Starting this month, the moderation team will be reaching out to select users to ask them to join our Trusted Reporters group. These users will be selected based upon the quality of the reports that they have submitted that have resulted in actions by the moderation team. This group of individuals will be given an opportunity to learn more about the moderation process. The goal is to ensure that community members are able to deliver the most meaningful reports to our moderation team. In exchange, these trusted reporters will have a more direct line of communication to a few members within the moderation team that can help assist in the event of a time critical need for moderator support.
How to become a trusted reporter
It’s important to note that Trusted Reporters will not have access to the moderation interface, admin interface, infrastructure, or tooling. The primary goal of the Trusted Reporters reporters program is to ensure the delivery of high quality reports and faster responses for time critical issues. As a result, the moderation team will select trusted reporters by reviewing users that submit quality reports that contain:
- What - Ensure that all of your reports include the posts that you are concerned about
- Why - Ensure that you provide a written explanation of your concern and categorize the report appropriately
Thanks to everyone in the Hachyderm family for the laughs, love, and support through 2023. We look forward to an incredible 2024!
Your Hachyderm Moderation Team!
A Minute from the Moderators
Hello and welcome to this month’s Moderator Minutes. Apologies for missing June, we have a blog post that we’ll post later this month as a belated post for June. The short version is we were completing that one while compiling for this one, and a lot is going on for the summer. So let’s get started!
This month we will cover: welcoming new users to Mastodon, volunteering with Hachyderm, decisions around Lemmy/kbin, and what’s going on with the Meta instance.
- New to Hachyderm and Mastodon? Welcome!
- Interested in volunteering? We’re growing our moderation team!
- What did we decide about Lemmy and kbin?
- Let’s talk about Meta.
- Hachyderm inbound and outbound communications
New to Hachyderm and Mastodon? Welcome!
We’re seeing an increase in Fediverse usage of users arriving from other platforms. Welcome new users! We have an explainer for How to Hachyderm in our documentation, which includes both Hachyderm specific information as well as links to common sources you’ll want to keep handy for general Mastodon or Fediverse information. Some things you’ll want to make sure to explore:
- Understanding home, local, and federated timelines
- Understanding how DMs work and their visibility (importantly: if you add someone to a DM thread they see the history, Mastodon doesn’t create a new thread).
- There’s a strong culture of content warning and alt-text (in our Accessible Posting doc) usage in the Fediverse. We do not expect anyone to be experts on these, only to iterate and improve over time.
As always, we encourage everyone to be welcoming to new transfers from other platforms. Everyone is encouraged to help new users learn the new tools and features available to them. Please keep in mind that shaming people for not knowing something goes against the ethos of the Hachyderm server, so please only enter conversations you can participate in that will foster the growth of others.
Interested in volunteering? We’re growing our moderation team!
Also, as a response to the growth we’re seeing, we’re scaling the Moderation team! If you’re interested in volunteering on the moderation team, please read on.
Hachyderm is operated by two teams: moderation and infrastructure. In an effort to protect the instance, we have implemented a SOD (separation of duties) policy, where team members can only operate in one team at a time. For those that know that they will be interested in volunteering with different teams over time, we ask that you commit to a given team for a minimum of three months (within reason). At this point in time, we are calling for volunteers to support the moderation team.
Hachyderm Moderators are expected to be able to create and maintain safe spaces. The easiest moderation decisions we make are around “banning the Nazis”. This can include literal Nazis, of course, but also extends to all forms of extremism and their “friendly federators”. It is more difficult and nuanced to handle genuine interpersonal conflict than to simply remove harmful content and sources, local or remote. In order to handle interpersonal conflict on the instance, understanding if there’s a path back into the community or not is important. In order to handle interpersonal conflict where there are one or more remote users, who have agreed to different instance rules, involves understanding which of Hachyderm’s rules are local and which are global.
As part of our current call for moderators, we included some Q&A that showcases this in the application form. It’s important to know that there are no right or wrong answers on the volunteer form and that everything we do here on the instance is covered in moderation training. What we’re looking for from you is just for you to explain to us how you’d interpret and handle the concepts and two examples we’ve provided. If you are interested in applying, please respond to our call for moderators here:
If you have any questions about volunteering in general, the application form, and so on please email us at admin@hachyderm.io.
What did we decide about Lemmy and kbin?
Many of you have been waiting for the results about whether or not Hachyderm will be running a Lemmy or kbin instance. The short, at the top, answer is:
We’ve decided that a Lemmy / kbin instance will actually need to be a Nivenly project, rather than be a sub-project of Hachyderm. There will be an upcoming announcement from Nivenly about this.
In addition to information about how to apply to Nivenly as a Lemmy or kbin instance, their post will include other project announcements and exciting status updates that they know everyone has been waiting for. While the Nivenly post will have more details about what they’re looking for specifically, we can share a bit of our experience to help as well.
As one of the first two (the other being Aurae) Nivenly Projects, we can share that two things to be aware of if you’re interested in scoping out the project: Nivenly will want to ensure that any projects brought on can commit to safe spaces and there will be expectations for what that means as well as projects that are interested in improving the community space overall. This can mean that an infra team will need to have one or more members (but not all) that are interested in contributing to the project’s software where / as applicable.
For anyone with preemptive questions about this, please reach out to Nivenly using their email: info@nivenly.org.
Let’s talk about Meta.
Lastly, let’s talk about Meta and Threads. We’ve received a lot of questions and discourse about this in general over a few different comms channels, including Hachyderm itself, email, and Nivenly’s Community Discord. By the nature of these different communication pathways, this means that essentially small bubbles of conversation have appeared that don’t have a lot of visibility. We’re consolidating some of the outcomes of those discussions here, for reference. And of course, since information is ongoing that means we’ve had to make a few revisions to this blog post while we were writing it to account for newly released information.
For this section, the first thing that we’ll be covering is how we’ll come to consensus about Meta’s instance, Threads. Then we’ll go into a bit about how Hachydermians can communicate their wants and needs to us, as well as a refresher on how we send out communications.
How the Hachyderm instance will reach consensus about Meta and communicate about it
How Hachyderm handles federating with other instances
Due to the size of our instance, we openly federate by default. This is not unchanging: as we research and become aware of instances that have a negative impact on the Hachyderm community or otherwise pose a risk, we can limit or fully defederate from other instances. The most common situation for this is when we research DarkFedi instances, though this is not exclusive.
In general, there are two sets of criteria that determine whether we federate with an instance. One set for moderation, the other for infrastructure. In both cases, the instance must be federating in order to prompt defederation research.
For moderation:
- The instance must not be a source of extremist content of any format
- The instance must not be a source of illegal content of any format
- The instance must not engage in trolling or brigading of other instances or users
- The instance must not stalk or otherwise harass other instances or users
- The instance must not monetize their users’ data without their informed consent or monetize the data of other users on the Fediverse without their informed consent
- The instance must not be a “friendly federator” with an instance engaging with one or more of the above
Note: in the above criteria, we specifically do not allow instances to stalk, target, and otherwise harass either instances or individuals. Users that target other users will be defederated from, and instances that target individuals will also be defederated from. We also evaluate “friendly federation”, which analyzes the federation impact of instances actively federating with instances who are engaging in these behaviors or who are joining in outright. We take steps, which can include defederation, to protect our space from “friendly federators” just as we do the source instances.
For infrastructure:
- The instance must not be a source of spam
- The instance must not be a source of excessive traffic, such as a denial of service (DDoS)
- The instance must not be a source of any other malicious traffic or activity, including but not limited to attempts to compromise the security of the servers or the data they store.
Hachyderm teams also differentiate if an activity is limited to a specific account or accounts, rather than instance-wide. To put it another way, “is there a spam account on the instance or is the instance being overrun by spam”. In order for action to be taken against an instance in its entirety, what we surface in our research must be consistent on the instance as a whole.
As a point of clarification: although an instance must be federating for us to evaluate if we should be federating with them or not, that instance does not need to be directly engaging with Hachyderm in any way to prompt our research. The vast majority of instances that we end up researching are found proactively.
The current status of Meta / Threads
Meta formally released their Threads product this week. Currently, Threads is not federating, and cannot be defederated from until it does. Current news sources (e.g. this TechCrunch article) indicate that Meta does plan to federate with Threads and support the ActivityPub protocol, which is in use on the Fediverse, but is not doing so at this time. Less than a day into launch, and there are already reports that Twitter is threatening to sue Meta over intellectual property. (Ars Technica article here.) Basically: it launched, and there is uncertainty to the product’s future.
If and when Threads starts federating, similar to other instances on the Fediverse, Hachyderm will evaluate our federation status using the above criteria. If Threads is found to be a source of harm or risk to the Hachyderm community or Hachyderm itself, then we would defederate from them.
Several Hachydermians have indicated an interest in the above analysis and how they will know what our stance is. As a reminder, we send out announcements using one or more of the following:
- Site wide announcements
- Posts on the Hachyderm account, which are cross posted to the Nivenly Community Discord
- Blog posts
Due to high user impact of any decisions on Meta / Threads, Hachydermians should expect:
- A post from our Hachyderm account when research has begun.
- A blog post with the results of our research once it’s concluded. We will announce the blog post via a site-wide announcement and a post on the Hachyderm Hachyderm account.
Once Threads starts federating, we will do research and commit to take action, with initial announcement, within two weeks. We will follow up with a more detailed blog post within 30 days of the decision.
As a reminder, any Hachydermian can bring up questions, concerns, and requests for changes at any time. This means that regardless of the decision that is ultimately made regarding Threads, users can voice their concerns and request that decision be reversed.
Resources for finding out more about the implications of Meta / Threads
We’ve received some Q&A over a few different channels as more information started coming out over the course of June. Some of the questions asked around what would happen if the Meta instance / Threads was a source of extremism, illegal content, and so forth. The answer to all of these is the same as the above: we block and ban users and instances that engage in those activities.
There are also lots of questions about “what would happen if”. For example, what would happen if the Meta instance becomes large or starts federating? There is also a lot of speculation around concern that Meta could deploy what’s called the “embrace, extend, extinguish” strategy against ActivityPub. This basically means that Meta would adopt it, start to build it out, and then (try to) eliminate its use.
Another concern in this area is what would happen with user data. To state it clearly: Hachyderm does not and will not ever sell user data. Due to the consequences of federation, we also cannot federate with instances that sell user data.
This means that if Hachyderm does ultimately federate with Threads, if and when they start federating, it will be because they pass all the above tests and, importantly, doing so does not result in Hachydermians data being used or sold without their consent. If Hachyderm does not ultimately federate with Threads, then it will be because the instance violated one or more of our policies for federation.
As the situation is still evolving, there is a lot of speculation to be answered. The Mastodon project has a blog post that answers some of these, including what can (and cannot) be done with ActivityPub or the Mastodon software. Similarly, Nexus of Privacy is writing a deep dive into issues and concerns with Fediverse Privacy and Threat Modeling. The article is still a draft, but already contains great points to consider if you or your instance are not doing so already.
Hachyderm inbound and outbound communications
A few quick reminders for how to communicate with the Hachyderm maintainers, if you have questions or concerns or need to request changes.
Reminder that we use Github Issues for consolidated, searchable, discussion threads
We use Github Issues as a means of communication - including intentionally leaving some threads open as Community Discussions. For 1:1 conversations, please feel free to continue to use email and Hachyderm’s Hachyderm account. We’ve also created a Hachyderm Maintainers Discord user that we use for Q&A in Nivenly’s Community Discord. That said, for wider conversations please consider using the Github Issues, as other users can search for and join in on the conversation! We mention this here mostly because Github Issues is the only place we haven’t received Q&A about Meta yet.
How we communicate site-wide
We also wanted to provide a refresher for how we communicate anything that is user impacting, including decisions, outages, and so forth, as it’s relevant to both the Meta Q&A and our communications in general. The tools we use to send announcements are one or more of the following:
- Hachyderm site announcements
- Posts on Hachyderm’s Hachyderm account, which are also cross posted in the Hachyderm category of Nivenly’s Community Discord
- Blog posts and documentation
All site announcements are also cross posted as a post on Hachyderm’s Hachyderm account. We include blog posts when there is additional detail that needs to be included, for example the Crypto Spam incident from May 2023.
We take into account how high the user impact of a decision is before choosing which, or all, of the communication paths to use. So in a case where the user impact is high you can expect to see site announcements and Hachyderm posts, as well as a blog post if additional detail is needed; whereas in situations where there is low to no user impact we’d only make a Hachyderm post if one is needed.
For 1:1 communications, like Q&A and other discussions that are not announcements, we use:
- The Hachyderm Hachyderm account
- The Hachyderm Maintainers Github account
- The Hachyderm Maintainers Discord account
- Our email, which is admin@hachyderm.io
We have communications documented on our Reporting and Communications documentation page for reference.
A Minute from the Moderators
Hello Hachydermia! It’s time for, you guessed it, the monthly Moderator Minute! Recently, our founder and former admin stepped down. As sad as we are to see her go, this does provide an excellent segue into the topics that we wanted to cover in this month’s Moderator Minute!
- The big question: will Hachyderm be staying online?
- Moderation on a large instance
- Harm prevention and mitigation on large instance
The big question: will Hachyderm be staying online?
Yes!
At Hachyderm we have been scaling our Moderation and Infrastructure teams since the Twitter Migration started to land in November 2022. Everyone on both teams is a volunteer, so we intentionally oversized our teams to accommodate high fluctuations in availability. Each team has a team lead and 4 to 10 active members at any given time, meaning Hachyderm is a ~20 person org. What this means for the moderation team specifically is the topic of today’s blog post!
Moderation on a large instance
Large instances like ours are mostly powered by humans and processes. And computers, of course. But mostly humans.
And for a large instance, there needs to be quite a few humans. In our case, most of our current mods volunteered as part of our Call for Volunteers back in December 2022.
How moderators are selected
Moderators must first and foremost be aligned with the ethos of our server. That means they must agree with our stances on no racism, no white supremacy, no homophobia, no transphobia, etc. Beyond that baseline, moderators are also chosen for:
- Their lived experiences and demographics
- Their experience with community moderation
For demographics: it is important to ensure that a wide variety of lived experiences are representative on the moderation team. These collective experiences and voices allow us to discuss, build, and enforce the policies that govern our server. Ensuring that there are multiple backgrounds, including race, gender, orientation, country of origin, language, and so on helps to ensure that multiple perspectives contribute.
For prior experience: there was also an intentional mix of experience levels on the moderation team. Ensuring that there are experienced mods also means that we have the bandwidth to onboard new, less experienced moderators. Being able to lay the groundwork for mentorship and onboarding is crucial for a self-sustaining organization.
Moderation onboarding and continuous improvement
Before moderators can begin acting in their full capacity, they must:
- Agree to the Moderator Covenant
- Be trained on our policies
- This includes the server rules, account policies, etc.
- Practice on inbound tickets
- Practice tickets have feedback from the Head Moderator and the group
The first two points go hand-in-hand. Our server rules outline the allowed and disallowed actions on our server. Our Moderator Covenant governs how we interpret and enforce those rules.
When practicing, new moderators are expected to write their analysis of the ticket including how they understand the situation, what action(s) they would or would not take in the given scenario, as well as why they are making that recommendation. When training the first group of moderators, this portion of the process was intended to last a week, but it worked out so well that we have kept the process. This means it is common for multiple moderators to see an individual ticket and asynchronously discuss prior to taking an action. This informal, consensus-style review has led to our team being able to continue to learn from each individual’s experiences and expertise.
When moderators make a mistake
We do our best, but are human and are thus prone to mistakes. Whenever something like this happens, we:
- May follow up with the impacted user or users
- Will review the policy that led to the error
When we make mistakes, we will always do our best by the user(s) directly impacted. This means that we will take ownership for our mistakes, apologize to the impacted user(s) if doing so will not cause further harm, and also review any relevant policies to ensure it doesn’t happen again.
Harm prevention and mitigation on large instance
How we handle moderation reports is driven by the enforced stance that moderation reports are harm already done. (We mentioned this stance in our recent postmortem as well.) Essentially, this means that if someone has filed a report because harm has been done, then that harm has been done.
How we determine what to do next depends on several factors, including the scope and severity of what has been done. It also depends on the source of the harm (local vs remote).
Using research as a tool for harm prevention
To say it first: in cases of egregious harm that originates on our server, the user is suspended from our server.
Reports of abuse originating from one of our own are exceedingly rare. More commonly, the reports of egregious harm come from remote sources. The worst cases are what you’d likely expect and are easy to suspend federation with.
The Hachyderm Moderation team also does a lot of proactive research regarding the origins of abusive behavior. The goal of our research is to minimize, and perhaps one day fully prevent, these instances’ ability to interact with our instance either directly or indirectly. To achieve this, we research not only the instances that are the sources of abusive behavior and content, but also those actively federating with them. To be clear: active here means active participation. We take this research very seriously and are doing it continuously.
Nurturing safe spaces by requiring active participation in moderation
The previous section focused on how we handle the worst offenders. What about everyone else? When someone Well Actuallys or doesn’t listen, or doesn’t respond properly when a boundary has been specified? (For information about setting and maintaining boundaries, please see our Mental Health doc.)
In situations where the situation being reported is not an egregious source of harm, the Hachyderm Moderation team makes heavy use of Mastodon’s freeze feature. The way we use it is to send the user a message that details what they were reported for, including their posts as needed, and use the freeze to tell them what we need from them to restore normal activity on their account. To prevent moderation issues from going on for long periods of time, users must respond in a given time frame and then perform the required action(s) in a given time frame.
What actions we require are situationally dependent. Most commonly, we request that users delete their own posts. We do this because we want to nurture a community where individuals are aware of, and accountable for, their actions. When moderators simply delete posts, the person who made the post is not required to even give the situation a second thought.
Occasionally, we may nudge the reported user a little further. In these cases, we include some introductory information in our message and also request that the person do a brief search on the topic as a condition of reinstating the account. The request usually looks a bit like this:
We ask that you do a light search on these topics. Only 5-15 min is fine.
The goal of this request is that we can all help make our community a safer place just by taking small steps to increase our awareness of others in our shared space.
If you agree to the above by filing an appeal, we will unfreeze your account. If you have further questions, please reach out to us at admin@hachyderm.io .
– The Hachyderm Mods
The reason we ask for such a brief search is because we do not expect someone to become an expert overnight. We do expect that all of us take small steps together to learn and grow.
As a point of clarification: we only engage in the freeze and restore pattern if the reported situation does not warrant a more immediate and severe action, such as suspending the user from Hachyderm.
And that’s it for this month’s Moderator Minute! Please feel free to ask the moderation team any questions about the above, either using Hachyderm’s Hachyderm account, email, or our Community Issues. We’ll see you next month! ❤️
Stepping Down From Hachyderm
Stepping Down From Hachyderm
Recently I abruptly removed myself from the “Admin” position of Hachyderm. This has surfaced a number of threads about me, Hachyderm, and the broader Fediverse. Today I would like to offer an apology as well as provide some clarity. There are a lot of rumors going around and I want to address some of them.
Before I get into why I am stepping down as admin, I want to be crystal clear: Hachyderm allows mutual aid. Hachyderm has always allowed mutual aid.
There has never been a point in Hachyderm’s history when mutual aid was not allowed. What we have never allowed on Hachyderm, is spam. Which we see a lot of, including phishing. What we have changed positions on, is corporate and organizational fundraising.
For us to say “Hachyderm does allow mutual aid,” and “Hachyderm does not allow spam or organizational fundraising,” requires the mods to define “Mutual Aid,” “Spam,” and “Organizational fundraising.” Once defined, Hachyderm need to come up with policies for these concepts, and instruct moderators to manage them. We do not always get this right, and we rely on the community’s help to tell us when we get it wrong, and how we can be more precise in our language and our actions.
One of the things I’ve found difficult about engaging in moderation discussions on the Fediverse, is the inability to agree on the facts at hand. I’ve always been very willing to take accountability for my actions, and take feedback on how to improve and make things better for all of our users. But that’s not possible to do when we can’t even agree on the topic at hand, and when we don’t engage with each other. In this most recent incident, I’ve had to spend significantly more time re-stating that Hachyderm does support mutual aid, and less time focusing on improving our policies and communications, so that our anti-spam and anti-organizational fundraising policies don’t harm members of our community that we want to support.
I would be very happy to have conversations about how Hachyderm’s policy, language, and enforcement were wrong, caused harm, and need to be fixed. That is a conversation worth having. I was also happy to have conversations around our stance on organizational fundraising. But the conversations about how I personally “contribute to trans genocide because I don’t support mutual aid,” are untrue, hurtful, and in my opinion, unproductive. Yes, this is extra hurtful to me, as I have experienced homelessness, and my own dependency on mutual aid as a transgender person. This is dear to my heart.
In many cases, decisions by other admins and mods were made on the assumption that I don’t support mutual aid, and this has been hard for me to reconcile.
I want to address something else, as my departure has some folks in our Hachyderm community and the broader Fediverse concerned about who will lead moderation after I leave. Moderation at Hachyderm will continue to be led by our lead moderator, as it has always been. I have never been the moderator of Hachyderm. In fact, on several occasions, I was moderated by the moderation team, including being asked to remove my post on Capitalism. This is as it should be, and I accepted the decisions of the moderation team on each occasion. In a healthy community, no one is above the rules.
Regarding the post on BlueSky, my hope was to push BlueSky towards an open identity provider such that the rest of the Fediverse could leverage the work. This would address the problem with people not owning their own identity/authentication, which is something that is important to many Hachydermians. People are already asking about this, and the AT protocol in general.
Effectively my intention was to utilize BlueSky’s hype and resources on behalf of federated identity such that people can own their own identity. Mastodon also has open issues about this. At this point I am exhausted and am abandoning BlueSky as well. I am taking a break from all social media at this time to protect my mental health.
The Hachyderm service has grown unexpectedly and I have tried my best to build a strong organization to live on without me. I have always intended on stepping down such that the collective could continue without me. Part of relinquishing control involved slowly stepping back one position at a time. It is up to the collective now to manage the service moving forward, and I deeply believe there are wonderful people in place to manage the service.
A Minute from the Moderators
Hello and welcome to April! This month we’ll be reviewing the account verification process we rolled out as well as two more classic moderation topics: how to file a report and what to do if you’re moderated.
- Account Verification
- How to file outstanding moderation reports
- Meter yourself when filing reports
- When you’ve been moderated
Account Verification
Throughout the month of March we started circulating an account verification process that launched. What does this mean, how do we use it, and what does it tell Hachydermians?
Mastodon account verification is like an identity service
Verification in the Mastodon context is similar to an ID verification service.
When you build your profile you have four fields that are labeled “profile
metadata”. When you include a URL that you have a rel=me link to your
Mastodon profile on, then that URL highlights green with a corresponding
green checkmark. In that case, the URL is verified: confirming that the person
who has control of the account also has control of the domain.
Hachyderm verification makes verification visible on an account profile
Since some specialized accounts are restricted on Hachyderm, we decided to make it more immediately visible which accounts are approved or not. As part of these discussions, we also extended the verification process to even non-restricted specialized accounts.
In order to verify, specialized accounts use the process outlined on our Account Verification page which includes agreeing to the Specialized Account Expectations and using our Community GitHub issues to submit the request. Once approved, we add their Hachyderm account to an approval page we created for this process. For an example of what the end result looks like, take a look at one of our first corporate accounts, Tailscale:

Specialized accounts should be verified
As a reminder, the only accounts we’re currently requiring to be verified are:
- Corporate accounts
- Bot accounts
- Curated accounts
That said, the account verification process is open to all specialized accounts. This includes but is not limited to: non-profits, conferences, meetups, working groups, and other “entity” based accounts.
Account verification is not open to individual users at this time. That said, if you are an independent contractor or similar type of individual / self-run business please read on.
We support small orgs, startups, self-run businesses, non-profits, etc.
Please email us at admin@hachyderm.io if this applies to your account or an account you would like to create. This is the grey area for all accounts that due to size, model, or “newness” don’t fit cleanly into the account categories we’ve tried to create.
In particular, if you suspect you might fit our criteria for a corporate account but the pricing model would be a burden for you: please still reach out! We’re happy to help and try to figure something out.
How to file outstanding moderation reports
First of all: thank you to everyone for putting your trust in us and for sending reports our way. Reports on any given day or week can vary and include mixtures of spam, on and off server bad behavior, and so on. When you send reports our way, here are the main things to keep in mind so that your reports are effective.
Please see our Reporting and Communication doc, which details Hachyderm specific information, and our Report Feature doc, which shows what we see when we receive a report, for reference.
Always include a description with your own words
You should always include a description with your report. It can be as succinct as “spam” or more descriptive like “account is repeatedly following / unfollowing other users”. You should include a description even if the posts, when included, seem to speak for themselves. If you are reporting content in a language other than English, please supply translations for any dog whistles or other commentary that a translation site will likely miss in a word-for-word translation.
Mastodon also deletes posts from reports more than 30 days old. So in the event that we need to check on a user and/or domain that has been reported more than once, but infrequently, the added context can also help us capture information that is no longer present.
(Almost) Always include relevant posts
If you are reporting a user because of something they have posted, you should (almost) always include the posts themselves. When a post is reported, the post is saved in the report even if the user’s home instance deletes the posts. If the posts are not included, and the user and/or their instance mods delete the posts, then we have an empty report with no additional context.
Please feel free to use your best judgement when choosing to attach posts to a report or not. In the rare situation where you are reporting extreme content, especially with imagery, you can submit a report without posts but please ensure that you have included the context for what we can expect when we investigate the user and/or domain.
Be clear when you are forwarding a report (or not)
When you file reports for users that are off-server, you will have the option to forward the report to the user’s server admins. When a report is not forwarded, only the Hachyderm moderation team sees it. Reports forward to remote instance admins by default. If you are choosing not to forward a report for a remote user, please call it out in your comments. Although we can see when a report isn’t forwarded, the added visibility helps.
There will be times when a reported user’s infraction falls under the purview of their instance moderators and whatever server rules that user has agreed to and may be in violation of. Typically, we will only step in to moderate these situations when we need to de-federate with a remote user and/or instance completely.
Meter yourself when filing reports
We appreciate everyone who takes the time to send us a report so we can work towards keeping the Hachyderm community safe. Make sure when you are doing so that you are being mindful of your own mental health as well. As a moderation team, we are able to load balance the reports that come through to protect us individually from burnout or from seeing content that can strongly, negatively, impact us on a personal level.
Even in situations where there is yet another damaging news cycle, which in turn creates a lot of downstream effects, individuals should avoid taking on what it takes a team to tackle. In these situations, please balance the reports you send with taking steps to separate yourself from continued exposure to that content. For tips and suggestions about how to do this, please see our March Moderator Minute and our Mental Health doc.
When you’ve been moderated
Being moderated is stressful! We understand and do our best to intervene only when required to maintain community safety or when accounts need to be nudged to be in alignment with rules for their account type and/or server rules.
For additional information on the below, please see both our Reporting and Communication doc and our Moderation Actions and Appeals doc.
Take warnings to heart, but they do not require an appeal
Warnings are only used as a way to communicate with you using the admin tools. They are not accrued like a “strike” system, where something happens if you exceed a certain number. Since we only send warnings when an account needs a nudge, either a small rule clarification or similar, they do not need to be appealed. Appeals to warnings will typically receive either no action or a rejection for this reason.
Always include your email when appealing an account restriction
If your account has been restricted in some way, e.g. either frozen or suspended, then you will need to file an appeal to open a dialogue for us to reverse that decision. You should always include how we can email you in your appeal: the admin UI does not let us respond to appeals. We can only accept (repeal) or reject (keep) the decision.
Let us know if we’ve made a mistake
If we’ve made an error in moderating your account: apologies! We do our best, but mistakes can and will happen. If your account has been restricted, please file an appeal the same as in the above: by including the error and your email so we can follow up with you as needed. Once we have the information we need we can reverse the error.
A Minute from the Moderators
We’ve been working hard to build out more of the Community Documentation to help everyone to create a wonderful experience on Hachyderm. For the past month, we’ve focused most heavily on our new How to Hachyderm section. The docs in this section are:
When you are looking at these sections, please be aware that the docs under the How to Hachyderm section are for the socialized norms around each topic and the subset of those norms that we moderate. Documentation around how to implement the features are both under our Mastodon docs section and on the main Mastodon docs. This is particularly relevant to our Content Warning sections: How To Hachyderm Content Warnings is about how content warnings are used here and on the Fediverse, whereas Mastodon User Interface Content Warnings is about where in the post composition UI you click to create a content warning.
Preserving your mental health
In our new Mental Health doc, we focus on ways that you can use the Mastodon tools for constraining content and other information. We structured the doc to answer two specific questions:
- How can people be empowered to set and maintain their own boundaries in a public space (the Fediverse)?
- What are the ways that people can toggle the default “opt-in”?
By default, social media like Mastodon / the Fediverse, opts users in to all federating content. This includes posts, likes, and boosts. Depending on your needs, you may want to opt out of some subsets of that content either on a case-by-case basis, by topic, by source, or by type. Remember:
You can opt out of any content for any reason.
For example, you may want to opt out of displaying media by default because it is a frequent trigger. Perhaps the specific content warnings you need aren’t well socialized. Maybe you are sensitive to animated or moving media. That said, perhaps media isn’t a trigger - you just don’t like it. Regardless of your reason, you can change this setting (outlined in the doc) whenever you wish and however often as meets your needs.
Hashtags and Content Warnings
Our Hashtags and Content Warnings docs are to help Hachydermians better understand both what these features are and the social expectations around them. In both cases, there are some aspects of the feature that people have encountered before: hashtags in particular are very common in social media and content warnings mirror other features that obscure underlying text on sites like Reddit (depending on the subreddit) and tools like Discord.
Both of these features have nuance to how they’re used on the Fediverse that might be new for some. On the Fediverse, and on Hachyderm, there are “reserved hashtags”. These are hashtags that are intended only for a specific, narrow, use. The ones we moderate on Hachyderm are FediBlock, FediHire, and HachyBots. For more about this, please see the doc.
Content warnings are possibly less new in concept. The content warning doc focuses heavily on how to write an effective content warning. Effective content warnings are important as you are creating a situation for someone else to opt in to your content. This requires consent, specifically informed consent. A well written content warning should inform people of the difference between “spoilers”, “Doctor Who spoilers”, and “Doctor Who New Year’s Special Spoilers”. The art of crafting an effective content warning is balancing what information to include while also not making the content warning so transparent that the content warning is the post.
Notably, effective content warnings feature heavily in our Accessible Posting doc.
Accessible Posting
Our Accessible Posting doc is an introductory guide to different ways to improve inclusion. It is important to recognize there are two main constraints for this guide:
- It is an introductory guide
- The Mastodon tools
As an introductory guide, it does not cover all topics of accessibility. As a guide that focuses on Mastodon, the guide discusses the current Mastodon tools and how to fully utilize them.
As an introductory guide, our Accessibility doc primarily seeks to help users develop more situational awareness for why there are certain socialized patterns for hashtags, content warnings, and posting media. We, as moderators of Hachyderm, do not expect anyone to be an expert on any issue that the doc covers. Rather, we want to help inspire you to continue to learn about others unlike yourself and see ways that you can be an active participant in creating and maintaining a healthy, accessible, space on the Fediverse.
Content warnings feature heavily on this doc. The reason for this is Mastodon is a very visual platform, so the main ways that you are connecting with others who do not have the same experience of visual content is by supplying relevant information.
There will always be more to learn and more, and better, ways to build software. For those interested in improving the accessibility features of Mastodon, we recommend reviewing Mastodon’s CONTRIBUTING document.
More to come
We are always adding more docs! Please check the docs pages frequently for information that may be useful to you. If you have an idea for the docs, or wish to submit a PR for the docs, please do so on our Community repo on GitHub.
April will mark one month since we launched the Nivenly Foundation, Hachyderm’s parent org. Nivenly’s website is continuing to be updated with information about how to sponsor or become a member. For more information about Nivenly, please see Nivenly’s Hello World blog post.
The creation of Nivenly also allowed us to start taking donations for Hachyderm and sell swag. If you are interested in donating, please use either our GitHub Sponsors or one of the other methods that we outline on our Thank You doc. For Hachyderm swag, please check out Nivenly’s swag store .
Decaf Ko-Fi: Launching GitHub Sponsors et al
Since our massive growth at the end of last year, many of you have asked about ways to donate beyond Nóva’s Ko-Fi. There were a few limitations there, notably the need to create an account in order to donate. There were a few milestones we needed to hit before we could do this properly, notably we needed to have an EIN in order to properly receive donations and pay for services (as an entity).
Well that time has come! Read on to learn about how you can support Hachyderm either directly or via Hachyderm’s parent organization, the Nivenly Foundation.
First things first: GitHub Sponsors

Actual Octocat from our approval email
As of today the Hachyderm GitHub Sponsors page is up and accepting donations! Using GitHub Sponsors you can add a custom amount and donate either once or monthly. There are a couple of donation tiers that you can choose from as well if you are interested in shoutouts / thank yous either on Hachyderm or on our Funding and Thank You page. In both cases we’d use your GitHub handle for the shoutout.
The shoutouts and Thank You page
#ThankYouThursday is a hashtag we’re creating today to thank users for their contributions. Most posts for #ThankYouThursday happen on Hachyderm’s Hachyderm account, but higher donations will be elible for shoutouts on Kris Nóva’s Hachyderm.
- $7/mo. and higher
- Get a sponsor badge on your GitHub profile
- $25/mo. and higher or $100 one-time and higher
- Get a sponsor badge on your GitHub profile
- Get a shoutout on the Hachyderm account’s quarterly #ThankYouThursday
- $50/mo. and higher or $300 one-time and higher
- Get a sponsor badge on your GitHub profile
- Get a shoutout on the Kris Nóva’s account’s quarterly #ThankYouThursday
- $1000 one-time and higher
- Get a sponsor badge on your GitHub profile
- Get a shoutout on the Hachyderm account’s quarterly #ThankYouThursday
- Be added to the Thank You List on our Funding page
- $2500 one-time and higher
- Get a sponsor badge on your GitHub profile
- Get a shoutout on Kris Nóva’s quarterly #ThankYouThursday
(All above pricing in USD.)
A couple of important things about the above:
- All public announcements are optional. You can choose to opt-out by having your donation set to private.
- By default we’ll use your GitHub handle for shoutouts. This is easier than reconciling GitHub and Hachyderm handles.
- We may adjust the tiers to make the Thank Yous more frequent.
Right now the above tiers are our best guess, but we may edit the #ThankYouThursday thresholds in particular so that we can keep a sustainable cadence. Thank you for your patience and understanding with this ❤️
And now an update for the Nivenly Foundation
For those who don’t know: the Nivenly Foundation is the non-profit co-op that we’re founding for Hachyderm and other open source projects like Aurae. The big milestone we reached here is that 1 ) we’re an official non-profit with the State of Washington and 2 ) we have a nice, shiny, EIN which allowed us to start accepting donations to both the Nivenly Foundation as well as its two projects: Aurae and Hachyderm. For visibility, here are all the GitHub sponsor links in one place:
It is also possible to give a custom one-time donation to Nivenly via Stripe:
Right now only donations are open for Nivenly, Aurae, and Hachyderm. After we finalize Nivenly’s launch, Nivenly memberships will also be available for individuals, maintainers, and what we call trade memberships for companies, businesses, and business-like entities.
What do Nivenly Memberships mean for donations?
Right now, donations and memberships are separate. That means that you can donate to Hachyderm and, once available, join Nivenly as two separate steps. As Nivenly’s largest project, providing governance and funding for Hachyderm uses almost all of Nivenly’s donations. As we grow and include more projects this is likely to shift over time. As such, we are spinning up an Open Collective page for Nivenly that will manage the memberships and also provide a way for us to be transparent about our budget as we grow. Our next two big milestones:
- What you’ve all been waiting for: the public release of the governance model (almost complete)
- What we definitely need: the finalization of our 501(c)3 paperwork with the IRS (in progress)
As we grow we’ll continue to post updates. Thank you all so much for your patience and participation 💕
P.S. and update: What’s happening with Ko-fi?
We are currently moving away from Kris Nóva’s Ko-fi as a funding source for Nivenly and Hachyderm et al. We’ve created a new Ko-fi account for the Nivenly Foundation itself:
Kris Nóva’s Ko-fi is still live to give people time to migrate Nivenly-specific donations (including those for Hachyderm and Aurae) from her Ko-fi to either GitHub sponsors, Nivenly’s Ko-fi, Stripe or starting a Nivenly co-op general membership via Nivenly’s Open Collective page as those become ready (which should be soon). We’ll still be using Nivenly-specific funds from her Ko-fi for Nivenly for the next 30-60 days and will follow up with an update as we start to stop that (manual 😅) process.
Growth and Sustainability
Thank you to everyone who has been patient with Hachyderm as we have had to make some adjustments to how we do things. Finding ourselves launched into scale has impacted our people more than it has impacted our systems.
I wanted to provide some visibility into our intentions with Hachyderm, our priorities, and immediate initiatives.
Transparency Reports
We intend on offering transparency reports similar to the November Transparency Report from SFBA Social. It will take us several weeks before we will be able to publish our first one.
The immediate numbers from the administration dashboard are below.
Donations
On January 1st, 2023 we will be changing our financial model.
Hachyderm has been operating successfully since April of 2022 by funding our infrastructure from the proceeds of Kris Nóva’s Twitch presence.
In January 2023 we will be rolling out a new financial model intended to be sustainable and transparent for our users. We will be looking into donation and subscription models such as Patreon at that time.
From now until the end of the year, Hachyderm will continue to operate using the proceeds of Kris Nóva’s Twitch streams, and our donations through the ko-fi donation page.
Governing Body
We are considering forming a legal entity to control Hachyderm in January 2023.
At this time we are not considering a for-profit corporation for Hachyderm.
The exact details of what our decision is, will be announced as we come to conviction and seek legal advice.
User Registration
At this time we do not have any plans to “cap” or limit user registration for Hachyderm.
There is a small chance we might temporarily close registration for small limited periods of time during events such as the DDoS Security Threat.
To be clear, we do not plan on rolling out a formal registration closure for any substantial or planned period of time. Any closure will be as short as possible, and will be opened up as soon as it is safe to do so.
We will be reevaluating this decision continuously. If at any point Hachyderm becomes bloated or unreasonably large we will likely change our decision.
User Registration and Performance
At this time we do not believe that user registration will have an immediate or noticeable impact on the performance of our systems. We do not believe that closing registration will somehow “make Hachyderm faster” or “make the service more reliable”.
We will reevaluating this decision continuously. If at any point the growth patterns of Hachyderm changes we will likely change our decision.
Call for Volunteers
We will be onboarding new moderators and operators in January to help with our service. To help with that, we have created a short Typeform to consolidate all the volunteer offers so it is easier for us to reach back out to you when we’re ready:
The existing teams will be spending the rest of December cleaning up documentation, and building out this community resource in a way that is easy for newcomers to be self sufficent with our services.
As moderators and infrastructure teams reach a point of sustainability, each will announce the path forward for volunteers when they feel the time is right.
The announcements page on this website, will be the source of truth.
Our Promise to Our users
Hachyderm has signed The Mastodon Server Covenant which means we have given our commitment to give users at least 3 months of advance warning in case of shutting down.
My personal promise is that I will do everything in my power to support our users any way I can that does not jeopardize the safety of other users or myself.
We will be forming a broader set of governance and expectation setting for our users as we mature our services and documentation.
Sustainability
I wanted to share a few thoughts on sustainability with Hachyderm.
Part of creating a sustainable service for our users will involve participation from everyone. We are asking that all Hachydermians remind themselves that time, patience, and empathy are some of the most effective ways in creating sustainable services.
There will be some situations where we will have to make difficult decisions with regard to priority. Often times the reason we aren’t immediately responding to an issue isn’t because we are ignoring the issue or oblivious to it. It is because we have to spend our time and effort wisely in order to keep a sustainable posture for the service. We ask for patience as it will sometimes take days or weeks to respond to issues, especially during production infrastructure issues.
We ask that everyone reminds themselves that pressuring our teams is likely counter productive to creating a sustainable environment.
Leaving the Basement
This post has taken several weeks in the making to compile. My hope is that this captures the vast majority of questions people have been asking recently with regard to Hachyderm.
To begin, I would like to start by introducing the state of Hachyderm before the migration, as well as introduce the problems we were experiencing. Next, I will cover the root causes of the problems, and how we found them. Finally, I will discuss the migration strategy, the problems we experienced, and what we got right, and what can be better. I will end with an accurate depiction of how hachyderm exists today.

Alice, our main on-premise server with her 8 SSDs. A 48 port Unifi Gigabit switch.
Photo: Kris Nóva
State of Hachyderm: Before
Hachyderm obtained roughly 30,000 users in 30 days; or roughly 1 new user every 1.5 minutes for the duration of the month of November.
I documented 3 medium articles during the month, each with the assumption that it would be my last for the month.
- November 3rd, 720 users Operating Mastodon, Privacy, and Content
- November 13th, 6,000 users Hachyderm Infrastructure
- November 25th, 25,000 users Experimenting with Federation and Migrating Accounts
Here are the servers that were hosting Hachyderm in the rack in my basement, which later became known as “The Watertower”.
| Alice | Yakko | Wakko | Dot | |
|---|---|---|---|---|
| Hardware | DELL PowerEdge R630 2x Intel Xeon E5-2680 v3 | DELL PowerEdge R620 2x Intel Xeon E5-2670 | DELL PowerEdge R620 2x Intel Xeon E5-2670 | DELL PowerEdge R620 2x Intel Xeon E5-2670 |
| Compute | 48 Cores (each 12 cores, 24 threads) | 32 Cores (each 8 cores, 16 threads) | 32 Cores (each 8 cores, 16 threads) | 32 Cores (each 8 cores, 16 threads) |
| Memory | 128 GB RAM | 64 GB RAM | 64 GB RAM | 64 GB RAM |
| Network | 4x 10Gbps Base-T 2x | 4x 1Gbps Base-T (intel I350) | 4x 1Gbps Base-T (intel I350) | 4x 1Gbps Base-T (intel I350) |
| SSDs | 238 GiB (sda/sdb) 4x 931 GiB (sdc/sdd/sde/sdf) 2x 1.86 TiB (sdg/sdh) | 558 GiB Harddrive (sda/sdb) | 558 GiB Harddrive (sda/sdb) | 558 GiB Harddrive (sda/sdb) |
It is important to note that all of the servers are used hardware, and all of the drives are SSDs.
“The Watertower” sat behind a few pieces of network hardware, including large business fiber connection in Seattle, WA. Here are the traffic patterns we measured during November, and the advertised limitations from our ISP.
| Egress Advertised | Egress in Practice | Ingress Advertised | Ingress in Practice | |
|---|---|---|---|---|
| 200 Mbps | 217 Mbps | 1 Gbps | 112 Mbps |
Our busiest traffic day was 11/21/22 where we processed 999.80 GiB in RX/TX traffic in a single day. During the month of November we averaged 36.86 Mbps in traffic with samples taken every hour.
The server service layout is detailed below.
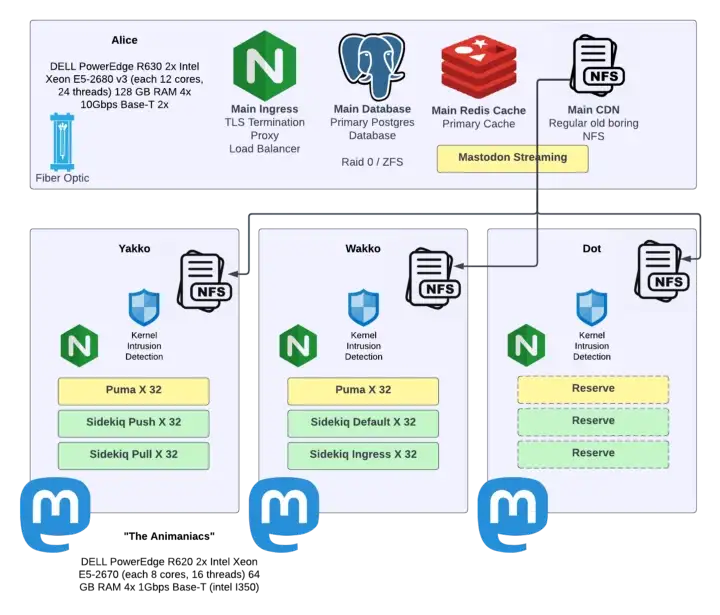
Problems in Production
For the vast majority of November, Hachyderm had been stable. Most users reported excellent experience, and our systems remained relatively healthy.
On November 27th, I filed the 1st of what would become 21 changelogs for our production infrastructure.
The initial report was failing images in production. The initial investigation lead our team to discover that our NFS clients were behaving unreasonably slow.
We were able to prove that NFS was “slow” by trying to navigate to a mounted directory and list files. In the best cases results would come back in less than a second. In the worst cases results would take 10-20 seconds. In some cases the server would lock up and a new shell would need to be established; NFS would never return.
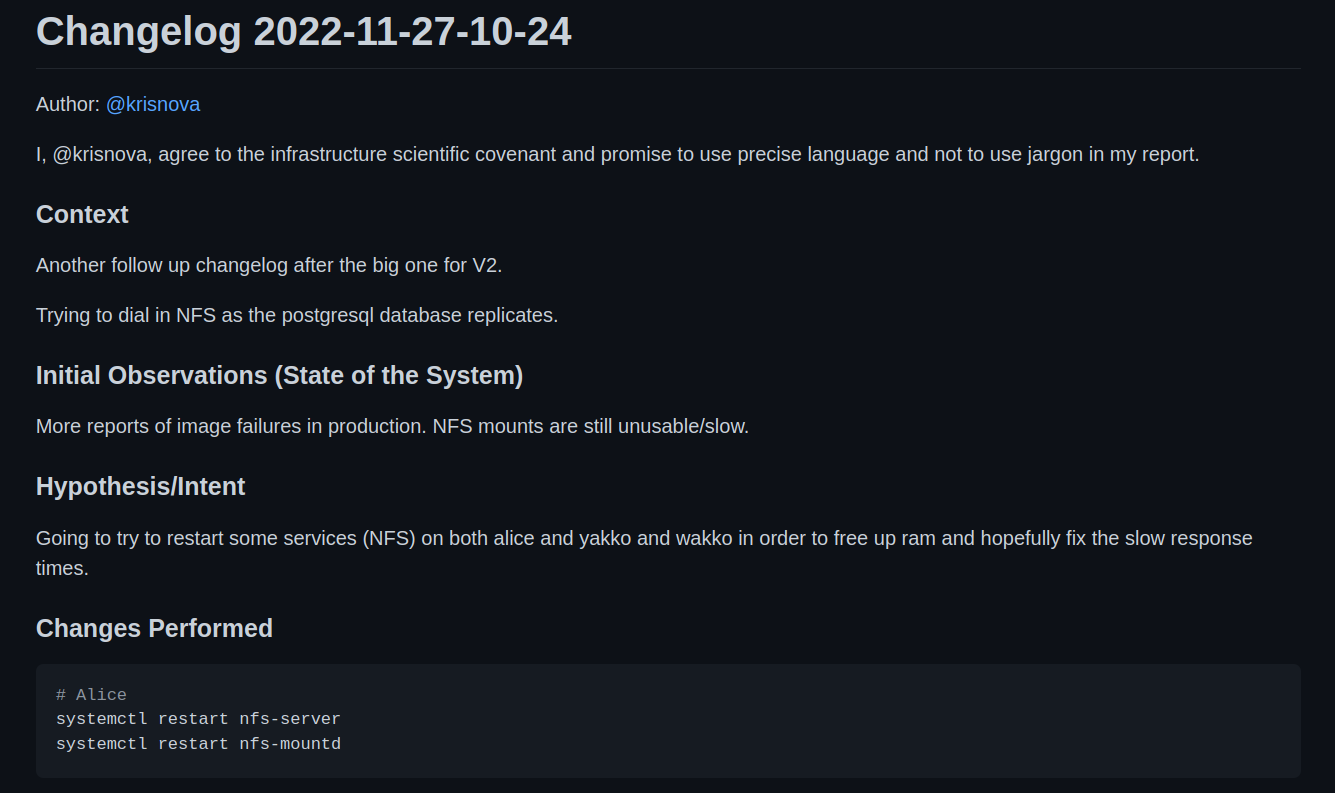
I filed a changelog, and mutated production. This is what became the first minor change in a week long crisis to evacuate the basement.
We were unable to fix the perceived slowness with NFS with my first change.
However we did determine that we had scaled our compute nodes very high in the process of investigating NFS. Load averages on Yakko, Wakko, and Dot were well above 1,000 at this time.
Each Yakko, Wakko, and Dot were housing multiple systemd units for our ingress, default, push, pull, and mailing queues – as well as the puma web server hosting Mastodon itself.
At this point Alice was serving our media over NFS, postgres, redis, and a lightweight Nginx proxy to load balance across the animaniacs (Yakko, Wakko, and Dot).
The problems began to cascade the night of the 27th, and continued to grow worse by the hour into the night.
- HTTP(s) response times began to degrade.
- Postgres response times began to degrade.
- NFS was still measurably slow on the client side.
The main observation was that the service would “flap”, almost as if it was deliberately toying with our psychology and our hope.
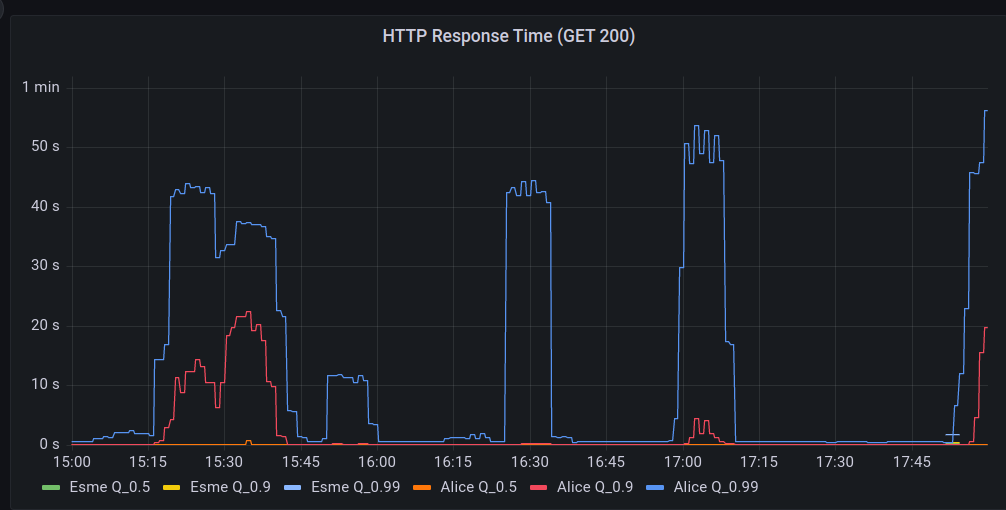
We would see long periods of “acceptable” performance when the site would “settle down”. Then, without warning, our alerts would begin to go off.
Hachyderm hosts a network of edge or point of presence (PoP) nodes that serve as a frontend caching mechanism in front of core.
During the “spikes” of failure, the edge Nginx logs began to record “Connection refused” messages.
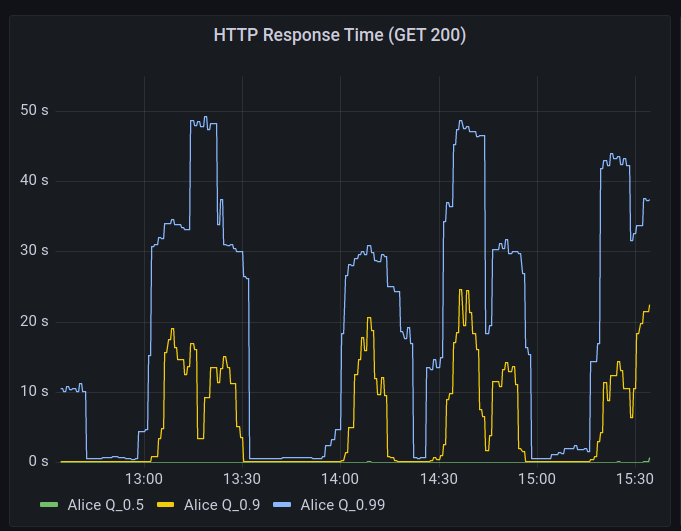
The trend of “flapping” availability continued into the night. The service would recover and level out, then a spike in 5XX level responses, and then ultimately a complete outage on the edge.
This continued for several days.
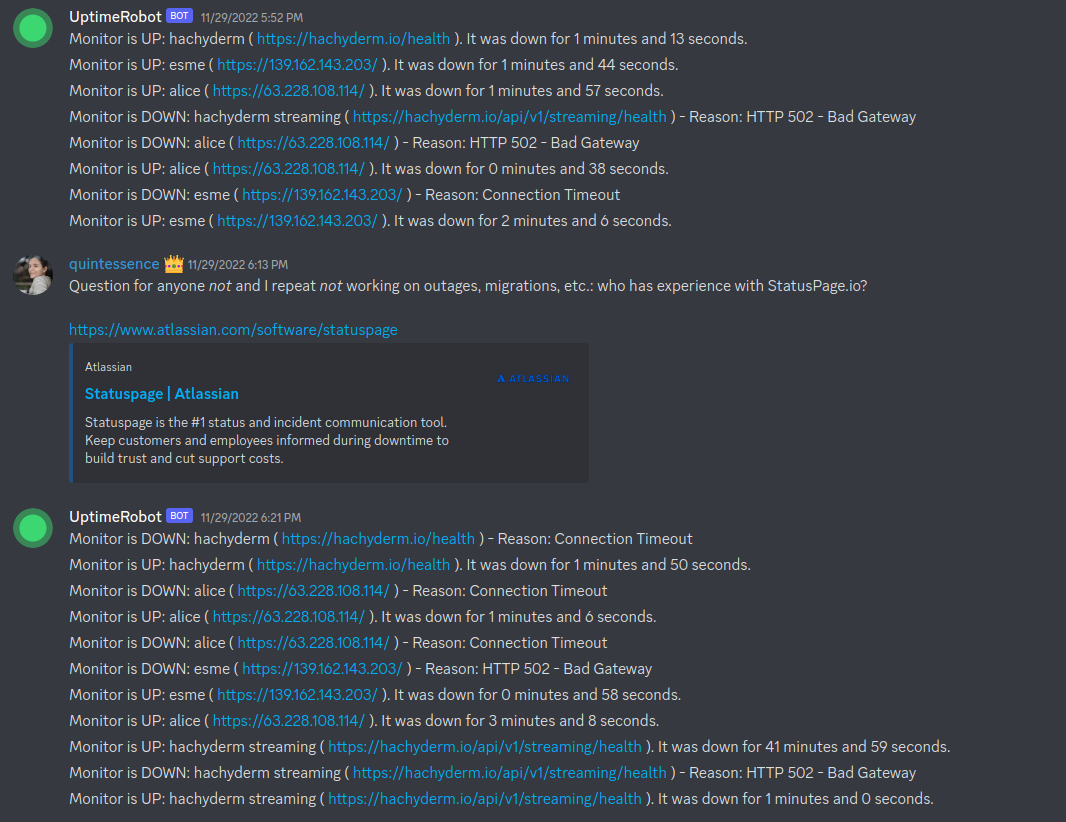
A Note on Empathy
It is important to note that Hachyderm had grown organically over the month of November. Every log that was being captured, every graph that was consuming data, every secret, every config file, every bash script – all – were a consequence of reacting to the “problem” of growth and adoption.
I call this out, because this is very akin to most of the production systems I deal with in my career. It is important to have empathy for the systems and the people who work on them. Every large production is a consequence of luck. This means that something happened that caused human beings to flock to your service.
I am a firm believer that no system is ever “designed” for the consequences of high adoption. This is especially true with regard to Mastodon, as most of our team has never operated a production Mastodon instance before. To be candid, it would appear that most of the internet is in a similar situation.
We are all experimenting here. Hachyderm was just “lucky” to see adoption.
There is no such thing as both a mechanistic and highly adopted system. All systems that are a consequence of growth, will be organic, and prone to the symptoms of reactive operations.
In other words, every ugly system is also a successful system. Every beautiful system, has never seen spontaneous adoption.
Finding Root Causes
By the 3rd day we had roughly 20 changelogs filed.
Each changelog capturing the story of a highly motivated and extremely hopeful member of the team believing they had once and for all identified the bottleneck. Each, ultimately failing to stop the flapping of Hachyderm.
I cannot say enough good things about the team who worked around the clock on Hachyderm. In many cases we were sleeping for 4 hours a night, and bringing our laptops to bed with us.
- @Quintessence wins the “Universe’s best incident commander” award.
- @Taniwha wins the “Best late night hacker and cyber detective” award.
- @hazelweakly wins the “Extreme research and googling cyberhacker” award.
- @malte wins the “Best architect and most likely to remain calm in a crisis” award.
- @dma wins the “Best scientist and graph enthusiast” award.
After all of our research, science, and detection work we had narrowed down our problem two 2 disks on Alice.
/dev/sdg # 2Tb "new" drive
/dev/sdh # 2Tb "new" drive
The IOPS on these two particular drives would max out to 100% a few moments before the cascading failure in the rack would begin. We had successfully identified the “root cause” of our production problems.
Here is a graphic that captures the moment well. Screenshot taken from 2am Pacific on November 30th, roughly 3 days after production began to intermittently fail.
It is important to note that our entire production system, was dependent on these 2 disks, as well as our ZFS pool which was managing the data on the disks,
[novix@alice]: ~>$ df -h
Filesystem Size Used Avail Use% Mounted on
dev 63G 0 63G 0% /dev
run 63G 1.7G 62G 3% /run
/dev/sda3 228G 149G 68G 69% /
tmpfs 63G 808K 63G 1% /dev/shm
tmpfs 63G 11G 53G 16% /tmp
/dev/sdb1 234G 4.6G 218G 3% /home
/dev/sda1 1022M 288K 1022M 1% /boot/EFI
data/novix 482G 6.5G 475G 2% /home/novix
data 477G 1.5G 475G 1% /data
data/mastodon-home 643G 168G 475G 27% /var/lib/mastodon
data/mastodon-postgresql 568G 93G 475G 17% /var/lib/postgres/data
data/mastodon-storage 1.4T 929G 475G 67% /var/lib/mastodon/public/system
tmpfs 10G 7.5G 2.6G 75% /var/log
Both our main media block storage, and our main postgres database was currently housed on ZFS. The more we began to correlate the theory, the more we could correlate slow disks to slow databases responses, and slow media storage. Eventually our compute servers and web servers would max out our connection pool against the database and timeout. Eventually our web servers would overload the media server and timeout.
The timeouts would cascade out to the edge nodes and eventually cause:
- 5XX responses in production.
- Users hitting the “submit” button as our HTTP(s) servers would hang “incomplete” resulting in duplicate posts.
- Connection refused errors for every hop in our systems.
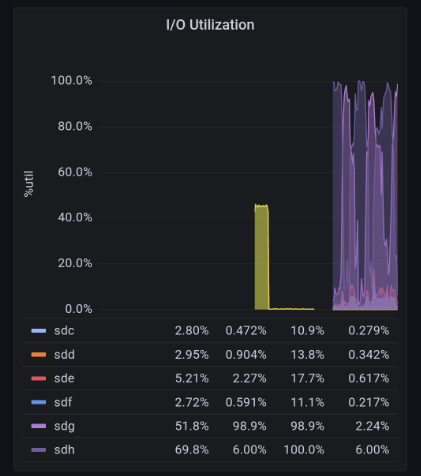
We had found the root cause. Our disks on Alice were failing.
Migration 1: Digital Ocean
We had made the decision to evacuate The Watertower and migrate to Hetzner weeks prior to the incident. However it was becoming obvious that our “slow and steady” approach to setting up picture-perfect infrastructure in Hetzner wasn’t going to happen.
We needed off Alice, and we needed off now.
A few notable caveats about leaving The Watertower.
- Transferring data off The Watertower was going to take several days with the current available speed of the disks.
- We were fairly confident that shutting down production for several days wasn’t an option.
- Our main problem was getting data off the disks.
Unexpectedly I received a phone call from an old colleague of mine @Gabe Monroy at Digital Ocean. Gabe offered to support Hachyderm altruistically and was able to offer the solution of moving our block storage to Digital Ocean Spaces for object storage.
Thank you to Gabe Monroy, Ado Kukic, and Daniel Hix for helping us with this path forward! Hachyderm will forever be grateful for your support!
There was one concern, how were we going to transfer over 1Tb of data to Digital Ocean on already failing disks?
One of our infrastructure volunteers @malte had helped us come up with an extremely clever solution to the problem.
We could leverage Hachyderm’s users to help us perform the most meaningful work first.
Solution: NGINX try_files
Malte’s model was simple:
- We begin writing data that is cached in our edge nodes directly to the object store instead of back to Alice.
- As users access data, we can ensure that it will be be taken of Alice and delivered to the user.
- We can then leverage Mastodon’s S3 feature to write the “hot” data directly back to Digital Ocean using a reverse Nginx proxy.
We can point the try_files directive back to Alice, and only serve the files from Alice once as they would be written back to S3 by the edge node accessing the files. Read try_files documentation.
In other words, the more that our users accessed Hachyderm, the faster our data would replicate to Digital Ocean. Conveniently this also meant that we would copy the data that was being immediately used first.
We could additionally run a slow rclone for the remaining data that is still running 2+ days later as I write this blog post.
This was the most impressive solution I have seen to a crisis problem in my history of operating distributed systems. Our users, were able to help us transfer our data to Digital Ocean, just by leveraging the service. The more they used Hachyderm, the more we migrated off Alice’s bad disks.
Migration 2: Hetzner
By the time the change had been in production for a few hours, we all had noticed a substantial increase in our performance. We were able to remove NFS from the system, and shuffle around our Puma servers, and sidekiq queues to reduce load on Postgres.
Alice was serving files from the bad disks, however all of our writes were now going to Digital Ocean.
While our systems performance did “improve” it was still far from perfect. HTTP(s) requests were still very slowly, and in cases would timeout and flap.
At this point it was easy to determine that Postgres (and it’s relationship to the bad disks) was the next bottleneck in the system.
Note: We still have an outstanding theory that ZFS, specifically the unbalanced mirrors, is also a contributing factor. We will not be able to validate this theory until the service is completely off Alice.
It would be slightly more challenging coming up with a clever solution to get Postgres off Alice.
On the morning of December 1st we finished replicating our postgres data across the atlantic onto our new fleet of servers in Hetzner.
- Nixie (Alice replacement)
- Freud (Yakko)
- Fritz (Wakko)
- Franz (Dot)
We will be publishing a detailed architecture on the current system in Hetzner as we have time to finalize it.
Our team made an announcement that we were shutting production down, and scheduled a live stream to perform the work.
The video of the cutover is available to watch directly on Twitch.

NodeJS and Mastodon
The migration would not be complete without calling out that I was unable to build the Mastodon code base on our new primary Puma HTTP server.
After what felt like an eternity we discovered that we needed to recompile the NodeJS assets.
cd /var/lib/mastodon
NODE_OPTIONS=--openssl-legacy-provider
RAILS_ENV=production bundle exec rails assets:precompile
Eventually we were able to build and bring up the Puma server which was connected to the new postgres server.
We moved our worker queues over to the new servers in Hetzner.
The migration was complete.
State of Hachyderm: After
To be candid, Hachyderm “just works” now and we are serving our core content within the EU in Germany.
There is an ever-growing smaller and smaller amount of traffic that is still routing through Alice as our users begin to access more and more obscure files.
Today we have roughly 700Gb of out 1.2Tb of data transferred to Digital Ocean.
We will be destroying the ZFS server in Alice, and replacing the disks as soon as we can completely take The Watertower offline.
On our list of items to cover moving forward:
- Offer a detailed public resource of our architecture in Hetzner complete with Mastodon specific service breakdowns.
- Build a blog and community resource such that we can begin documenting our community and bringing new volunteers on board.
- Take a break, and install better monitoring on our systems.
- Migrate to NixOS or Kubernetes depending on the needs of the system.
- Get back to working on Aurae, now with a lot more product requirements than we had before.
Conclusion
We suffered from pretty common pitfalls in our system. Our main operational problems stemmed from scaling humans, and not our knowledge of how to build effective distributed systems. We have observability, security, and infrastructure experts from across Silicon Valley working on Hachyderm and we were still SSHing into production and sharing passwords.
In other words, our main limitations to scale were managing people, processes, and organizational challenges. Even determining who was responsible for what, was a problem within itself.
We had a team of experts without any formal precedent working together, and no legal structure or corporate organization to glue us together. We defaulted back to some bad habits in a pinch, and also uncovered some exciting new patterns that were only made possible because of the constraints of the fediverse.
Ultimately I believe that myself, and the entire team is convinced that the future of the internet and social is going to be in large collaborative operational systems that operate in a decentralized network.
We made some decisions during the process, such as keeping registrations open during the process that I agree with. I think I would make the same decisions again. Our limiting factor in Hachyderm had almost nothing to do with the amount of users accessing the system as much as it did the amount of data we were federating. Our system would have flapped if we had 100 users, or if we had 1,000,000 users. We were nowhere close to hitting limits of DB size, storage size, or network capacity. We just had bad disks.
I think the biggest risk we took was onboarding new people to a slow/unresponsive service for a few days. I am willing to accept that as a good decision as we are openly experimenting with this entire process.
I have said it before, and I will say it again. I believe in Hachyderm. I believe we can build a beautiful and effective social media service for the tech industry.
The key to success will be how well we experiment. This is the time for good old fashioned computer science, complete with thoughtful hypothesis and detailed observability to validate them.
Incidents
Security incident: Redis cache exposed to public internet
Background
Between July 9 and July 16, 2023, one of Hachyderm’s Redis cache servers was exposed to the public internet. On July 16, 2023, the Hachyderm Infrastructure team identified a misconfiguration of our firewall on the cache server which allowed access to the redis interface from the public Internet. After a routine system update, the nftables firewall service was not brought up automatically after a restart, which exposed the Redis cache to the internet for a period of seven days.
During the exposure, an unknown third party attempted to reconfigure our Redis server to act as a replica for a Redis server they controlled. Due to this change, a read-only mode was enabled on Hachyderm Redis and no further data was written.
Normally, Hachyderm servers run nftables to block all except necessary traffic from the Internet. We leverage Tailscale for server-to-server communication and only expose ports to the Internet as needed to run Mastodon and administer the systems.
As of July 16, 2023 11:17 UTC, the Hachyderm team has corrected the configuration on our systems and blocked external actors from accessing this Redis instance. While we do not have any direct evidence the information in the cache was deliberately exfiltrated, because this was exposed to the public internet, we assume the data was compromised.
Impact
Highly sensitive information like passwords, private keys, and private posts were NOT exposed as part of this incident. No action is required from the user.
The affected Redis cache stored the following types of information with a 10 minute time-to-live before getting deleted:
- Logins using
/auth/sign_inwill cache inputted email addresses and used IP addresses for login throttling. Note that if you had a cached session during this period, no IPs or email-addresses would have been included. - Rails-generated HTML content.
- Some UI-related settings for individual users (examples being toggles for reducing motion, auto play gifs, and the selected UI font).
- Public posts rendered by Mastodon in the affected period.
- Other non-critical information like emojis, blocked IPs, status counts, and other normally public information of the instance.
We do not have sufficient monitoring to confirm precisely when the compromise occurred. We also have no confirmation if any of the above data was actually sent to a third party, but since the information was available to them, we assume the data was compromised. But since the adversary turned on read-replica mode disabling writes, and Mastodon’s cache having a time to live of 10 minutes, it would have severely limited the amount of information leaked in this period.
Timeline
| Date/Time (UTC) | Event | Phase |
|---|---|---|
| 2023-07-09 19:16 | Fritz was updated, and part of the upgrade process required a restart of the system. Nftables, our system firewall, was not reenabled across reboots on this server. Fritz acted normally throughout our monitoring period. | Before |
| Between 2023-07-10 to 2023-07-16 | The adversary adds a non-Hachyderm host as the fritz Redis write primary, causing Fritz to go into read-only mode. Sometime thereafter, Fritz’s Redis encounters a synchronization error, causing it to not synchronize further with the non-Hachyderm host. | Before |
| 2023-07-16 10:45 | Hachyderm Infra Engineer (HIE1) identifies that, when attempting to run a standard administrative task sees Mastodon logs are alerting that RedisCacheStore: write_entry failed, returned false: Redis::CommandError: READONLY You can’t write against a read only replica. | Identify |
| 2023-07-16 10:56 | After reviewing the system configuration further, HIE1 identifies that the Redis cache on fritz is targeting an unknown host IP as a write primary; overall Redis is in a degraded state. | Identify |
| 2023-07-16 11:10 | HIE1 confirms the unknown host IP is not a Hachyderm host and that nftables on fritz is not enabled as expected. | Identify |
| 2023-07-16 11:17 | HIE1 stops Redis and re-enables nftables on fritz, closing unbounded communication from the Internet. | Remediate |
| 2023-07-16 13:02 | HIE1 confirms the type of information stored in the cache, including e-mail + IP address for logins. | Investigate |
Analysis
What went well & where did we get lucky
- We got lucky that it was the caching redis server, which primarily holds Rails generated HTML content, UI related settings per user, and rack based login throttling.
- No user data outside of a subset of IP addresses and Emails from people using the login form in the compromised period were possibly shared.
- Redis had a TTL of ten (10) minutes on any data in this cache.
- Redis was put into a READONLY mode when the compromise occurred, so it is likely no data was pushed to the adversary after the timestamp of the compromise. This, coupled with the ten minute cache, caused the cache itself to empty fairly quickly.
What didn’t go well
- Process: While we have a standard process for updating Mastodon, and while our servers are version-controlled into git, they are individually unique creations, which makes it challenging to understand if a server is configured correctly because each server can be just a little different.
- System: We don’t leverage authentication or restrictive IP block binds on our Redis server, so once the firewall was down, Redis would become available on the Internet and trivial to connect to and see what data it contained.
- It took us a long time to identify the issue:
- Observability: We don’t currently have detective control to alert us if a critical configuration on a server is set correctly or not.
- Observability: Furthermore, we didn’t have any outlier detection or redis alerts set up to notify us that Redis had gone into read only mode.
- Observability: Due to how journalctl had been set up to rotate logs by size, and the explosive amount of RedisCacheStore: write_entry failed entries generated per successful page load, we quickly lost the ability to look back on our log history to see the exact date the access happened.
Corrective Actions
The Hachyderm infrastructure team is taking/will take the following actions to mitigate the impact of this incident:
| Action | Expected Date | Status |
|---|---|---|
| Enable nftables on fritz and ensure it will re-enable upon system or service restart on all systems | Jul 16, 2023 | Done |
| Perform system audit to identify potential additional compromise beyond Redis | Jul 16, 2023 | Done |
| Update system update runbooks to include validating that nftables is running as expected after restarts | Jul 17, 2023 | To Do |
| Bind Redis only to expected IP blocks for Hachyderm’s servers | Jul 17, 2023 | To Do |
| Publish full causal analysis graph and update corrective actions based on findings | Jul 21, 2023 | To Do |
| Identify tooling to keep logs for a defined time period that would not be affected by large log files. | Jul 28, 2023 | To Do |
| Identify plan to require authentication on Redis instances | Jul 28, 2023 | To Do |
| Identity mechanism for detective controls to alert if critical services are not running on servers & create plan to implement | Jul 28, 2023 | To Do |
| Explore possibility of using cloud-based firewall rules as an extra layer of protection & plan to implement | Jul 28, 2023 | To Do |
Moderation Postmortem
Hello Hachydermians! There has been a lot of confusion this week, so we’re writing up this blog post to be both a postmortem of sorts and a single source of truth. This is partly to combat some of the problems generated by hearsay: hearsay generates more Things To Respond To than Things That Actually Happened. As a result, this post is a little longer than our norm.
Moderation Incident
(A note to the broader, non-tech industry, members of our community: “Incident” here carries similar context and meaning to an “IT Incident” as we are a tech-oriented instance. Postmortems for traditional IT incidents are also in this section.)
A Short, Confusing Timeline
On 24 April 2023 the Hachyderm Moderation team received a request to review our Fundraising Policy via a GitHub Issue. The reason for the request was to ensure there was a well understood distinction between Mutual Aid and Fundraising. Although our Head Moderator responded to the thread with the constraints we use when developing new rules, some of the hearsay we started to see in the thread the user linked raised some flags that something else was happening.
In order to determine what happened, we needed to dive into various commentary before arriving at a potential root cause (and we eventually determined this was indeed the correct root cause). While a few of our moderators working on this, our founder and now-former admin Kris Nóva was requested, either directly or indirectly, to make statements on transgender genocide (she is herself openly transgender) and classism.
These issues are important, we want to be unequivocally clear. Kris Nóva is transgender and has been open about her experiences with homelessness and receiving mutual aid. The Hachyderm teams are also populated, intentionally, with a variety of marginalized individuals that bring their own lived experiences to our ability to manage Hachyderm’s moderation and infrastructure teams. That said: it was not immediately apparent that these requests were initially connected to the originating problem. In fact, it caused additional resources to be used trying to determine if there was a secondary problem to address. This resulted in a delay in actual remediation.
The Error Itself
On 27 Mar 2023 the Hachyderm Moderation Team received a report that indicated that an account may have been spamming the platform. When the posts were reviewed at the time of the report, it did trigger our spam policy. When we receive reports of accounts seeking funds, we try to validate the posts to check for common issues like phishing and so forth, as well as checking post volume and pattern to determine if the account is posting in a bot-like way, and so forth. At the time the report was moderated, the result was that the posting type and/or pattern was incorrectly flagged as spam and we requested the account stop posting that type of post. Once we became aware of the situation, the Hachyderm Moderation team followed up with our Hachydermian to ensure that they knew that they could post their requests for Mutual Aid, apologized for the error, and did our best to let them know we were here if there was anything else we could do to help them feel warm and welcome on our instance.
Lack of public statement
There have been some questions around the lack of public statement regarding the above. There are two reasons for this. First and foremost, this is because situations involving moderation are between the moderation team and the impacted person. Secondly, we must always take active steps to protect against negative consequences that can come with all the benefits of being a larger instance.
How Errors in Moderation are Handled at Hachyderm
Depending on the error, one or both of the following occurs:
- Follow up with the user to rectify the situation
- Review policy to ensure it doesn’t happen again
This is because of two enforced opinions of the Hachyderm Moderation team:
- Moderation reports filed by users are reports of harm done.
- To put it another way: if a user needs to file a report of hateful content, then they have already seen that content to report it.
- All moderation mistakes are also harm done.
For the latter, we only follow up with the user if 1) they request and/or 2) we have reason to believe it would not increase the harm done. All Hachyderm Moderator and Hachydermian interactions are centered on harm mitigation. Rectifying mistakes in moderation are about the impacted person and not ego on the part of the specific moderator who made the mistake.
To put it another way, the Hachyderm Moderation team exists to serve the Hachyderm Community. This means that we will apologize to the user as part of harm mitigation. We will not as part of “needing to have our apology accepted” or to “be seen as apologizing”. These latter two go against the ethos of Hachyderm Moderation Strategy.
Inter-instance Communication and Hachyderm
Back when we took on the Twitter Migration in Nov 2022, we started to overcommunciate with Hachydermians that we were going to start using email and GitHub Issues (in addition to moderation reports) to accommodate our team scaling. As part of the changes we made, we also started making changes to reflect this in the documentation, as well as including how other instances can reach out to us if needed. It was our own pattern that if we needed to reach out to another instance, we used the email address they listed on their instance page. This is because we didn’t want to assume “the name on the instance” was “the” person to talk to. There are likely other instances like ours that have multiple people involved. This is reinforced by the fact that the “name” is actually populated by default by the person who originally installed the software on the server(s).
That said, we recently made a connection with someone who has grown their instance in the Fediverse for quite some time and has been helping to make us aware of the pre-existing cultural and communication norms in this space. In the same way it was natural for us to check for the existence of instance documentation to find their preferred way to communicate, it was unnatural for some of the existing instances to do so. Instead, it seems there are pre-existing cultural norms in the space we weren’t aware of, the impact of this is that some instances knew how to reach us and others did not.
We have been taking feedback from the person we connected with so that we can balance the needs of the existing communication patterns and norms of the Fediverse, while not accidentally creating a situation where a communication method ends up either too silo’ed or not appropriately visible due to our team structures.
TLS Expires: media.hachyderm.io
On February 28th, 2023 at approximately 01:55 UTC Hachyderm experienced a service degradation in which images failed to load in production.
We were able to quickly identify the root cause as expired TLS certificates in production for media.hachyderm.io
Context
Hachyderm TLS certificates are still managed manually, and are very clearly out of sprawling out of control due to our rapid growth. There are many certificates on various servers that have had config copied from one server to another as we grew into our current architecture.
The alert notification was missed, and the media.hachyderm.io TLS privkey.pem and fullchain.pem material expired causing the service degradation.
Timeline
- Feb 28th 01:52
@quintessenceFirst report of media outages - Feb 28th 01:54
@novaConfirms media is broken from remote proxy in EU - Feb 28th 01:56
@novaAppoints@quintessenceas incident commander - Feb 28th 01:57
@novaConfirms TLS expired onmedia.hachyderm.io - Feb 28th 02:30
@novaLive streaming fixing TLS
Shortly after starting the stream we discovered that the Acme challenge was not working because the media.hachyderm.io DNS record was pointed to CNAME hachyderm.io and the proxy was not configured to manage the request. In the past we have worked around this by editing the CDN on the East coast which is where the Acme challenge will resolve.
In this case we changed the media.hachyderm.io DNS record to point to A <ip-of-fritz> which is where the core web server was running.
We re-ran the renew process and it worked!
sudo -E certbot renew
We then re-pointed media.hachyderm.io back to CNAME hachyderm.io.
Next came the scp command to move the new cert material out to the various CDN nodes and restart nginx.
# Copy TLS from fritz -> CDN host
scp /etc/letsencrypt/archive/media.hachyderm.io/* root@<host>:/etc/letsencrypt/archive/media.hachyderm.io/
# Access root on the CDN host
ssh root@<host>
# Private key (on CDN host)
rm -f /etc/letsencrypt/live/media.hachyderm.io/privkey.pem
ln -s /etc/letsencrypt/archive/media.hachyderm.io/privkey3.pem /etc/letsencrypt/live/media.hachyderm.io/privkey.pem
# Fullchain (on CDN host)
rm -f /etc/letsencrypt/live/media.hachyderm.io/fullchain.pem
ln -s /etc/letsencrypt/archive/media.hachyderm.io/fullchain3.pem /etc/letsencrypt/live/media.hachyderm.io/fullchain.pem
The full list of CDN hosts:
- cdn-frankfurt-1
- cdn-fremont-1
- sally
- esme
Restarting nginx on each of the CDN hosts was able to fix the problem.
# On a CDN host
nginx -t # Test the config
systemctl reload nginx # Reload the service
# On your local machine
emacs /etc/hosts # Point "hachyderm.io" and "media.hachyderm.io" to IP of CDN host
# Check your browser for working images
Impact
- Full image outage across the site in all regions.
- A stressful situation interrupting dinner and impacting the family.
- Even more chaos and confusion with certificate material.
Lessons Learned
- We still have outstanding legacy certificate management problems.
Things that went well
- We had a quick report, and the mean time to resolution was <60 mins.
Things that went poorly
- The certs are in an even more chaotic state.
- There was no alerting that the images broke.
- There was a high stress situation that impacting our personal lives.
Where we got lucky
- I still had access to the servers, and was able to remedy the situation from existing knowledge.
Action items
- We need to destroy the vast majority of nginx configurations and domains in production
- We need to destroy all TLS certs and re-create them with a cohesive strategy
- We need a better way to perform the Acme challenge that doesn’t involve changing DNS around the globe
- Nóva to send list of domains to discord to destroy
Fritz Timeouts
On January 7th, 2023 at approximately 22:26 UTC Hachyderm experienced a spike in HTTP response times as well as a spike in 504 Timeouts across the CDN.
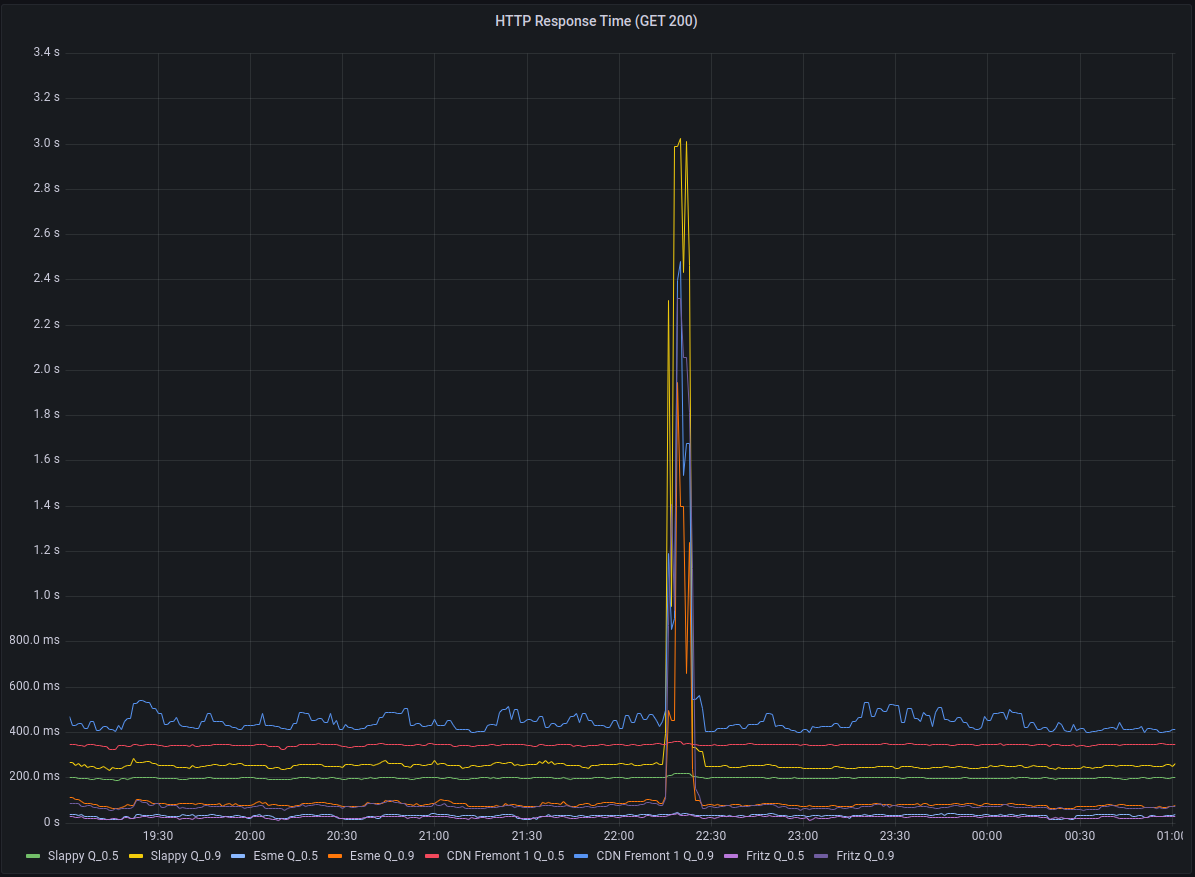
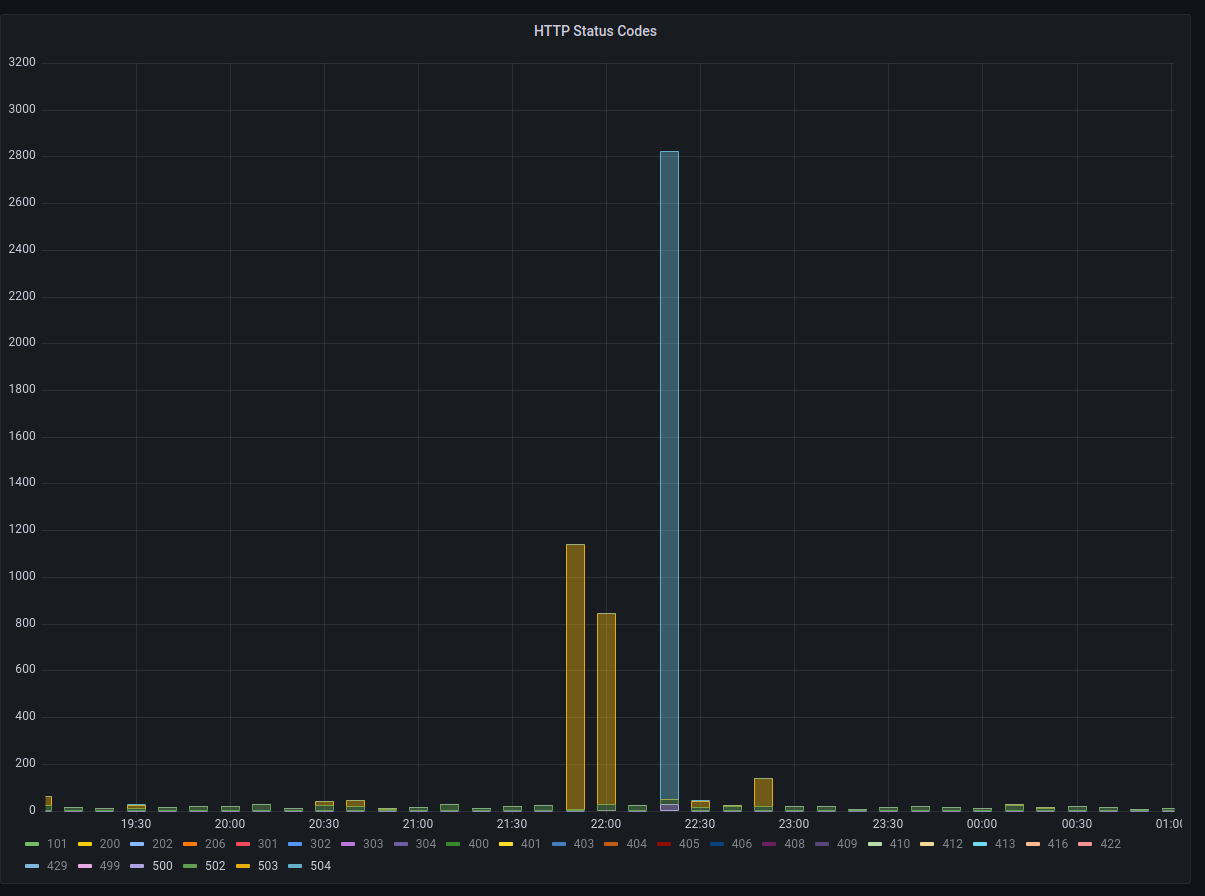
Working backwards from the CDN to fritz we discovered another cascading failure.
Context
There is a fleet of CDN nodes around the world, commonly referred to as “POP” servers (Point of Presence) or even just “The CDN”. These servers reverse proxy over dedicated connections back to our core infrastructure.
These CDN servers served content timeouts at roughly 22:20:00 UTC.
These CDN servers depend on the mastodon-streaming service to offer websocket connections.
Impact
- Total streaming server outage reported in Discord (Uptime Robot)
- Slow/Timeouts reported by users in Twitch chat
- Nóva noticed slow/timeouts on her phone
HTTP Response Times measured > 3s
Background
We received some valuable insight from @ThisIsMissEm who has experience with both node.js websocket servers and the mastodon codebase, which can be read here in HackMD.
An important takeaway from this knowledge is that the mastodon-streaming service and the mastodon-web service will not rate limit if they are communicating over localhost.
In other words, you should be scheduling mastodon-streaming on the same node you are running mastodon-web.
We believe that the way the streaming API works, that if there is a “large event” such as having a post go out by a largely followed account it can cause a cascading effect on everyone connected via the streaming API.
A good metric to track would actually be the percentage of connections that a single write is going to. If the mastodon server has one highly followed user, a post by them, especially in a “busy” timezone for the instance, will result in unbalanced write behaviours, where one message posted will result in iterating over a heap more connections than others (one per follower who’s connected to streaming), so you can end up doing 40,000 network writes very easily, locking up node.js temporarily from processing disconnections correctly.
We believe that the streaming API began to drop connections which cascaded out to the CDN nodes via the mastodon-web service.
We can correlate this theory by connecting observe logged lines to the Mastodon code bash.
Logs from mastodon-streaming on Fritz
06-4afe-a449-a42f861855b2 Tried writing to closed socket
33-414d-9143-6a5080bd6254 Tried writing to closed socket
33-414d-9143-6a5080bd6254 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
41-4385-9762-c5c1d829ba27 Tried writing to closed socket
0f-4eb4-9751-b5ac7e21c648 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
60-40d1-99b4-349f03610b36 Tried writing to closed socket
60-40d1-99b4-349f03610b36 Tried writing to closed socket
33-414d-9143-6a5080bd6254 Tried writing to closed socket
06-4afe-a449-a42f861855b2 Tried writing to closed socket
Code from Mastodon main
const streamToWs = (req, ws, streamName) => (event, payload) => {
if (ws.readyState !== ws.OPEN) {
log.error(req.requestId, 'Tried writing to closed socket');
return;
}
Found in mastodon/streaming/index.js
Logs (correlation) from mastodon-web on Fritz
This is where we are suspecting that we are hitting the “Rack Attack” rate limit in the streaming service.
-4589-97ed-b67c66eb8c38] Rate limit hit (throttle): 98.114.90.221 GET /api/v1/timelines/home?since_id=109>
Working Theory (root cause)
We are maxing out the streaming service on Fritz, and it is rate limiting the mastodon web (puma) service. The “maxing out” can be described in the write-up by @ThisIsMissEm where NodeJS struggles to process/drop the connections that are potentially a result of a “Large Event”.
As the websocket count increases there is a cascading failure that starts on Fritz and works it way out to the nodes.
Eventually the code that is executing (looping) over the large amounts of websockets will “break” and there is a large release where a spike in network traffic can be observed.
We see an enormous (relatively) amount of events occur during the second of 22:17:30 on Fritz which we suspect is the “release” of the execution path.
As the streaming service recovers, the rest of Hachyderm slowly stabilizes.
Lessons Learned
Websockets are a big deal, and will likely be the next area of our service we need to start observing.
We will need to start monitoring the relationship between the streaming service and the main mastodon web service pretty closely.
Things that went well
We found some great help on Twitch, and we ended up discovering an unrelated (but potentially disastrous) problem with Nietzsche (the main database server).
We have a path forward for debugging the streaming issues.
Things that went poorly
Nóva was short on Twitch again and struggles to deal with a lot of “noise/distractions” while she is debugging production.
In general there isn’t much more we can do operationally other than keep a closer eye on things. The code base is gonna’ do what the code base is gonna’ do until we decide to fork it or wait for improvements from the community.
Where we got lucky
Seriously the Nietzsche discovery was huge, and had nothing to do with the streaming “hiccups”. We got extremely lucky here.
Consequently, Nóva fixed the problem on Nietzsche which was that our main database NVMe disk was at 98% capacity.
- We did NOT receive storage alerts in Discord (I believe we should have?)
- Nóva could NOT find an existing cron job on the server to clean the archive.
- Nóva scheduled the cron job (Using
sudo crontab -e)
The directory (archive) that was full:
/var/lib/postgres/data/archive
Nietzsche is now back down to ~30%
Action items
1) Set up websocket observability on CDN nodes (clients) and Fritz (server)
We want to see how many “writes” we have on the client side and how many socket connections they are mapped to if possible. We might need to PR a log entry for this to the Mastodon code base.
2) Verify cron is running on Nietzsche
We need to make sure the cron is running and the archive is emptying
3) Debug why we didn’t receive Nietzsche alerts
I think we should have seen these, but I am not sure?
4) We likely need a bigger “Fritz”
Sounds like we need donations and a bigger server (it will be hard to move streaming off of the same machine as web).
Fritz on the fritz
On January 3th, 2023 at approximately 12:30 UTC Hachyderm experienced a spike in
response times. This appeared to be due to a certificate that had not been
renewed on fritz, which runs the Mastodon Puma and Streaming services. The
service appeared to recover until approximately 15:00 UTC when another spike in
response times was observed.
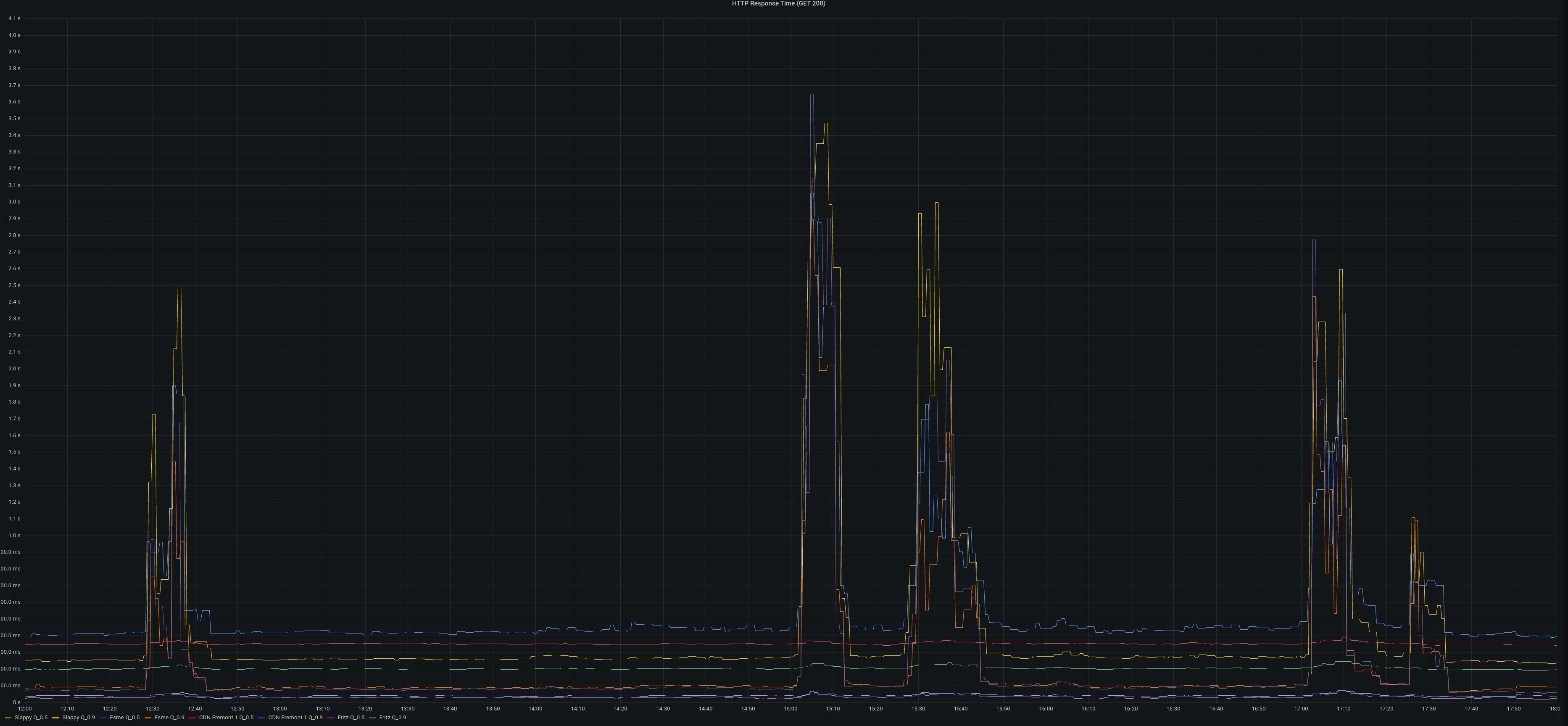
Alerts were firing in discord alerting us to the issue.
Background
fritz runs mastodon-web and mastodon-streaming and all other web nodes proxy
to fritz.
mastodon-web was configured with 16 processes each having 20 threads.
mastodon-streaming was configured with 16 processes
Impact
p90 response times grew from ~400ms to >2s. increase of 502 responses to >1000 per minute.
Root causes and trigger
organic growth in users and traffic coupled with the return from vacation of
the US caused the streaming and puma processes on fritz to use more CPU. CPU
load hit >90% consistently on fritz. this in turn caused responses to fail to
be returned to the upstream web frontends.
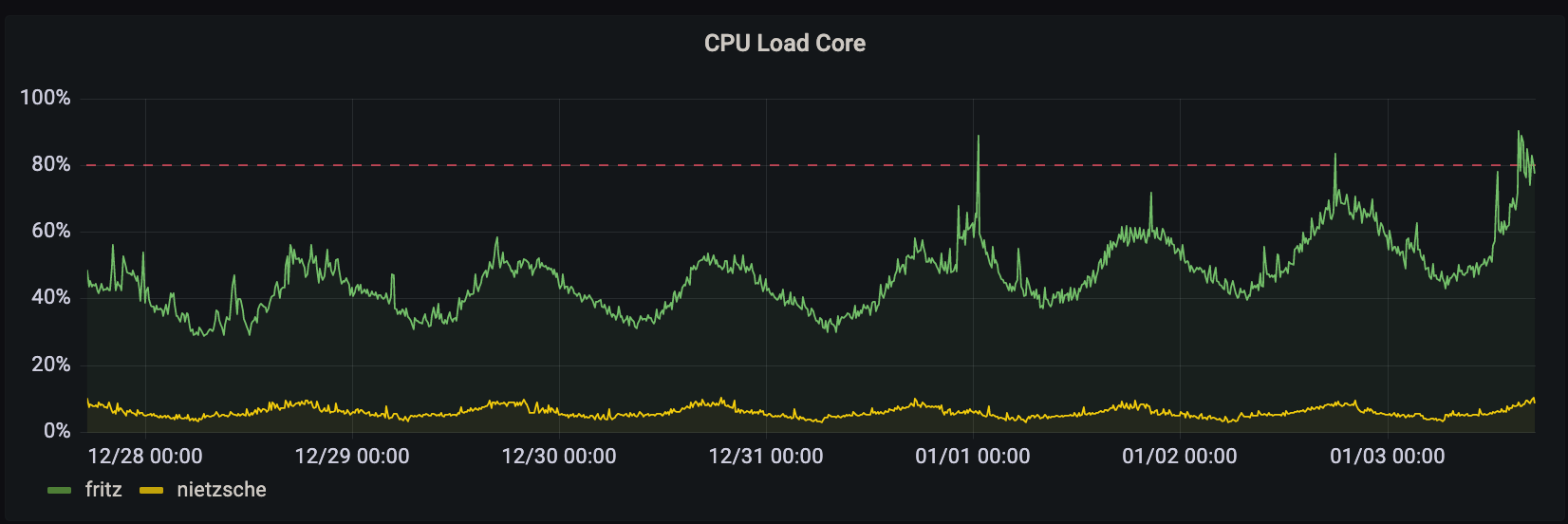
Lessons Learned
response times are very sensitive to puma threads (reducing from 20 to 16 threads per process doubled GET response times).
the site functions well with fewer streaming processes.
Things that went well
we had the core CPU load on the public dashboard.
Things that went poorly
in an attempt to get things under control both mastodon-streaming and mastodon-web were changed. puma was then reverted as we had over-corrected and response times were getting quite bad.
no CPU load alerts were configured for fritz specifically.
Where we got lucky
@dma was already keyed in to fritz thanks to an earlier issue where
certs hadn’t been renewed.
Action items
1) Streaming processes reduces @dma [repair]
Reduced the number of streaming processes on fritz from 16 to 12.
2) Better alerting on CPU load @dma [detect]
We should implement better CPU load alerting on every host to detect these issues and be able to respond even more quickly.
3) Postmortem documented @dma
This blog post and a hackmd postmortem doc.
The Queues ☃️ down in Queueville
Every Queue down in Queueville liked ActivityPub a lot. But John Mastodon who lived just north of Queuville, did not! John Mastodon hated ActivityPub, the whole Activity season! Now please don’t ask why. No one quite knows the reason.
It could be, perhaps, that his WEB_CONCURRENCY was too tight.
It could be his MAX_THREADS wasn’t screwed on just right.
But I think that the most likely reason of all
May have been that his CPU was two sizes too small.
But, whatever the reason, his WEB_CONCURRENCY or CPUs,
He stood there on Activity Eve hating the Queues…
Staring down from his cave with systemd hacks
At the warm buzzing servers below in their racks
For he knew every Queue down in Queueville beneath Was busy now hanging an Activity-Wreath. “And they’re posting their statuses,” he snarled with a sneer. “Tomorrow is Activity-Mas! It’s practically here!”
Then he growled, with John Mastodon fingers nervously drumming, “I must find some way to keep the statuses from coming”!
For, tomorrow, I know all the Queues and the “they"s and the “them"s Will wake bright and early for ActivitySeason to begin!
And then! Oh, the noise! Oh, the noise! Noise! Noise! Noise! There’s one thing John Mastodon hates: All the NOISE! NOISE! NOISE! NOISE!
And they’ll shriek squeaks and squeals, racing ‘round on their hosts. They’ll update with jingtinglers tied onto their posts! They’ll toot their floofloovers. They’ll tag their tartookas. They’ll share their whohoopers. They’ll follow their #caturday-ookas. They’ll spin their #hashtags. They’ll boost their slooslunkas. They’ll defederate their blumbloopas. But complain about their whowonkas.
And they’ll play noisy games like post a cat on #caturday, An ActivityPub type of all the queers and the gays! And then they’ll make ear-splitting noises galooks On their great big postgres whocarnio ruby monolith flooks!
Then the Queues, young and old, will sit down to a feast. And they’ll feast! And they’ll feast! And they’ll FEAST! FEAST! FEAST! FEAST!

They’ll feast on Queue-pudding, and rare Queue-roast-beast, Ingress Queue roast beast is a feast I can’t stand in the least!
And then they’ll do something I hate most of all! Every Queue down in Queueville, the tall and the small,
They’ll stand close together, with UptimeRobot bells ringing. They’ll stand hand-in-hand, and those Queues will start singing!
And they’ll sing! And they’ll sing! And they’d SING! SING! SING! SING! And the more John Mastodon thought of this Queue Activity Sing, The more John Mastodon thought, “I must stop this whole thing!”
Why for fifty-three days I’ve put up with it now! I must stop ActivityPub from coming! But how?
Timeline
All events are documented in UTC time.
- 13:00
@dmaNoticed the ingress queue was backing up - 16:45
@quintessenceNoticed the ingress queue was still lagging - 17:00
@novaDeclared an incident - 17:30
@hazelweaklyNoticed CPU at 100% on Freud and Franz - 17:34
@hazelweaklyWorked with@dmato rebalance queues across Freud, Franz, and Nietzsche - 17:37
@dmaNotices CPU on Nietzsche is not changing - 17:45
@hazelweaklyChanges 5MAX_THREADSto 20MAX_THREADSon Nietzsche
ActivityEve
“I know just what to do!” John Mastodon laughed in his throat. “I’ll max out the CPU, and cause the network to bloat.”
And he chuckled, and clucked, “What a great John Mastodon trick! With this CPU and network lag, I’ll cause the latency to stick!”
“All I need is a denial of service.” John Mastodon looked around. But since denial of services are scarce, there was none to be found.
Did that stop John Mastodon? Hah! John Mastodon simply said, “If I can’t find a denial of service, I’ll make one instead!”
So he took his dog MAX, and he took some more EMPTY_THREADS.
And he tied big WEB_CONCURRENCY on top of his head.
Then he loaded some cores and some old empty racks.
On a ramshackle sleigh and he whistled for MAX.
Then John Mastodon said “Giddyap!” and the sleigh started down Toward the homes where the Queues lay a-snooze in their town.
All their graphs were dark. No one knew he was there. All the Queues were all dreaming sweet dreams without care. When he came to the first little house of the square.
“This is stop number one,” John Mastodon hissed, As he climbed up load average, empty cores in his fist.
Then he slid down the ingress, a rather tight bond. But if a denial of service could do it, then so could John Mastodon.
The queues drained only once, for a minute or two. Then he stuck his posts out in front of the ingress queue!
Where the little Queue messages hung all in a row. “These messages,” he grinched, “are the first things to go!”
Then he slithered and slunk, with a smile most unpleasant, Around the whole server, and he took every message!
Cat pics, and updates, artwork, and birdsite plea’s! Holiday cheer, Hanukkah, Kwanza and holiday trees!
And he stuffed them in memory. John Mastodon very nimbly, Stuffed all the posts, one by one, up the chimney.
Then he slunk to the default queues. He took the queues’ feast! He took the queue pudding! He took the roast beast!
He cleaned out that /inbox as quick as a flash.
Why, John Mastodon even took the last can of queue hash!
Then he stuffed all the queues up the chimney with glee. “Now,” grinned John Mastodon, “I will stuff up the whole process tree!”
As John Mastodon took the process tree, as he started to shove, He heard a small sound like the coo of a dove…
He turned around fast, and he saw a small Queue! Little Cindy-Lou Queue, who was no more than two.
She stared at John Mastodon and said, “our statuses, why? Why are you filling our queues? Why?”
But, you know, John Mastodon was so smart and so slick, He thought up a lie, and he thought it up quick!
“Why, my sweet little tot,” John Mastodon lied,
“There’s a status on this /inbox that won’t light on one side.
So I’m taking it home to my workshop, my dear. I’ll fix it up there, then I’ll bring it back here.”
And his fib fooled the child. Then he patted her head, And he got her a drink, and he sent her to bed.
And when Cindy-Lou Queue was in bed with her cup, He crupt to the chimney and stuffed the ingress queues up!
Then he went up the chimney himself, the old liar.
And the last thing he took was /var/log for their fire.
On their .bash_history he left nothing but hooks and some wire.
And the one speck of content that he left in the house Was a crumb that was even too small for a mouse.
Then he did the same thing to the other Queues’ houses, Leaving crumbs much too small for the other Queues’ mouses!
Timeline
All events are documented in UTC time.
- 17:58
@dmaNotices we are no longer bottlenecked on Ingress after@hazelweaklymakes changes - 18:03
@dmaProvides update on priority of systemd flags - 18:10
@dmaProvides spreadsheet for us to calculate connections to database
ActivityMorn
It was quarter of dawn. All the Queues still a-bed, All the Queues still a-snooze, when he packed up his sled,
Packed it up with their statuses, their posts, their wrappings, Their posts and their hashtags, their trendings and trappings!
Ten thousand feet up, up the side of Mount Crumpet, He rode with his load average to the tiptop to dump it!
“Pooh-pooh to the Queues!” he was John Msatodon humming. “They’re finding out now that no ActivityPub messages are coming!
They’re just waking up! I know just what they’ll do! Their mouths will hang open a minute or two Then the Queues down in Queueville will all cry boo-hoo!
That’s a noise,” grinned John Mastodon, “that I simply must hear!” He paused, and John Mastodon put a hand to his ear.
And he did hear a sound rising over the snow. It started in low, then it started to grow.
But this sound wasn’t sad! Why, this sound sounded glad!
Every Queue down in Queueville, the tall and the small, Was singing without any ActivityPub messages at all!
He hadn’t stopped ActivityPub messages from coming! They came! Somehow or other, they came just the same!
And John Mastodon, with his feet ice-cold in the snow, Stood puzzling and puzzling. “How could it be so?”
Posts came without #hashtags! It came without tags! It came without content warnings or bags!
He puzzled and puzzled till his puzzler was sore. Then John Mastodon thought of something he hadn’t before.
Maybe ActivityPub, he thought, doesn’t come from a database store. Maybe ActivityPub, perhaps, means a little bit more!
And what happened then? Well, in Queueville they say That John Mastodon’s small heart grew three sizes that day!
And then the true meaning of ActivityPub came through, And John Mastodon found the strength of ten John Mastodon’s, plus two!
And now that his heart didn’t feel quite so tight, He whizzed with his load average through the bright morning light!
With a smile to his soul, he descended Mount Crumpet Cheerily blowing “Queue! Queue!” aloud on his trumpet.
He road into Queuville. He brought back their joys. He brought back their #caturday images to the Queue girls and boys!
He brought back their status and their pictures and tags, Brought back their posts, their content and #hashtags.
He brought everything back, all the CPU for the feast! And he, he himself, John Mastodon carved the roast beast!
Welcome ActivityPub. Bring your cheer, Cheer to all Queues, far and near.
ActivityDay is in our grasp So long as we have friends’ statuses to grasp.
ActivityDay will always be Just as long as we have we.
Welcome ActivityPub while we stand Heart to heart and hand in hand.
Timeline
All events are documented in UTC time.
- 18:10
@hazelweaklyProvides update that queues are now balancing and load is coming down - 18:18
@novaConfirms queues are draining and systems are stabilizing
Root Cause
John Mastodon took the queue hash, and up the chimney he stuck it. The Hachyderm crew was too tired to fill out the report and said “fuck it”.
Nietzsche:
- 4 default queues (unchanged)
- 32 default ingress (changed)
Franz:
- 6 default queues (unchanged)
- 1 ingress queue (changed)
- 5 pull queues (unchanged)
- 5 push queues (unchanged)
Freud:
- 3 default queues (unchanged)
- 2 ingress queues (changed)
- 2 pull queue (changed)
- 2 push queue (changed)
Changes:
Because the database connection count per ingress queue process changed, when necessary, I will clarify queue amounts in terms of database connections.
- Moved 2 ingress queues (40 DB connections) from franz to nietzsche
- Moved 2 ingress queues (40 DB connections) from freud to nietzsche
- Changed DB_POOL on ingress queues from 20 to 5 as they're heavily CPU bound.
- Changed -c 20 on ingress queues from 20 to 5 as they're heavily CPU bound.
- Scaled Nietzsche up from 8 ingress queues to 32 to keep the amount of total database connections the same.
- Restarted the one ingress queue remaining on franz (this lowered ingress DB connections from 20 to 5).
- Restarted the two ingress queues remaining on freud (this lowered ingress DB connections from 40 to 10).
- Removed a "pushpull" systemd service on Freud and replaced it with independent push and pull sidekiq processes (neutral db connection change).
Degraded Service: Media Caching and Queue Latency
On Saturday, December 17th, 2022 at roughly 12:43 UTC Hachyderm received our first report of media failures which started a 2-day-long investigation of our systems by @hazelweakly, @quintessence, @dma, and @nova. The investigation coincidentally overlapped with a well-anticipated spike in growth which also unexpectedly degraded our systems simultaneously.
The first degradation was unplanned media failures, typically in the form of avatar and profile icons intermittently on the service. We had an increase in 4XX level responses due to misconfigured cache settings in our CDN. We believe the Western US to be the only region impacted by this degradation.
The second degradation was unplanned queue latency increasing presumably from the increase in usage due to the fallout of Twitter mass exodus. We experienced an increase in our push and pull queues, as well as a short period of default latency.
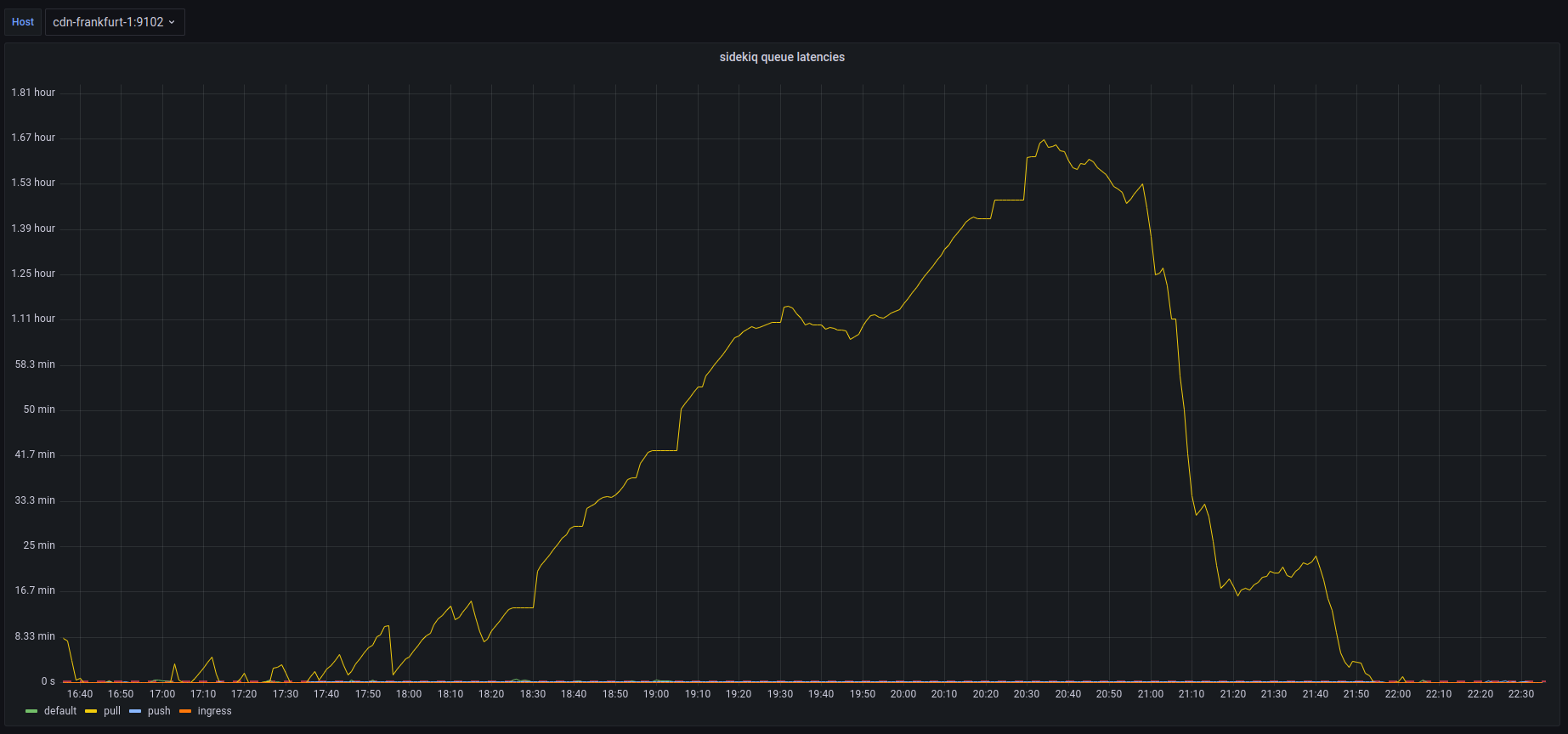
Timeline
All events are documented in UTC time.
- Dec 16th 12:43
@arjenpdevriesFirst report of media cache misses #217 - Dec 17th 08:21
@blueturtleai2nd Report, and first confirmation of media cache misses #218 - Dec 17th 21:43
@quintessence3rd Report of media cache misses - Dec 17th 21:44
@novaFalse mediation ofcmd+shift+rcache refresh - Dec 17th 22:XX More reports of cache failures, multiple Discord channels, and posts
- Dec 17th 23:XX More reports of cache failures, multiple Discord channels, and posts
- Dec 17th 24:XX Still assuming “cache problems” will just fix themselves
- Dec 18th 14:45
@dmaNginx audit andlocation{}rewrite onfritz; no results - Dec 18th 14:45
@dmaNo success debugging various CDN nodes and cache strategies - Dec 18th 15:16
@dmaCheck mastodon-web logs on CDNs; /system GETs with 404s - Dec 18th 20:32
@hazelweaklyDiscovered.env.productionmisconfiguration cdn-frankfurt-1, franz - Dec 18th 20:41
@quintessenceConfirms queues are backing up
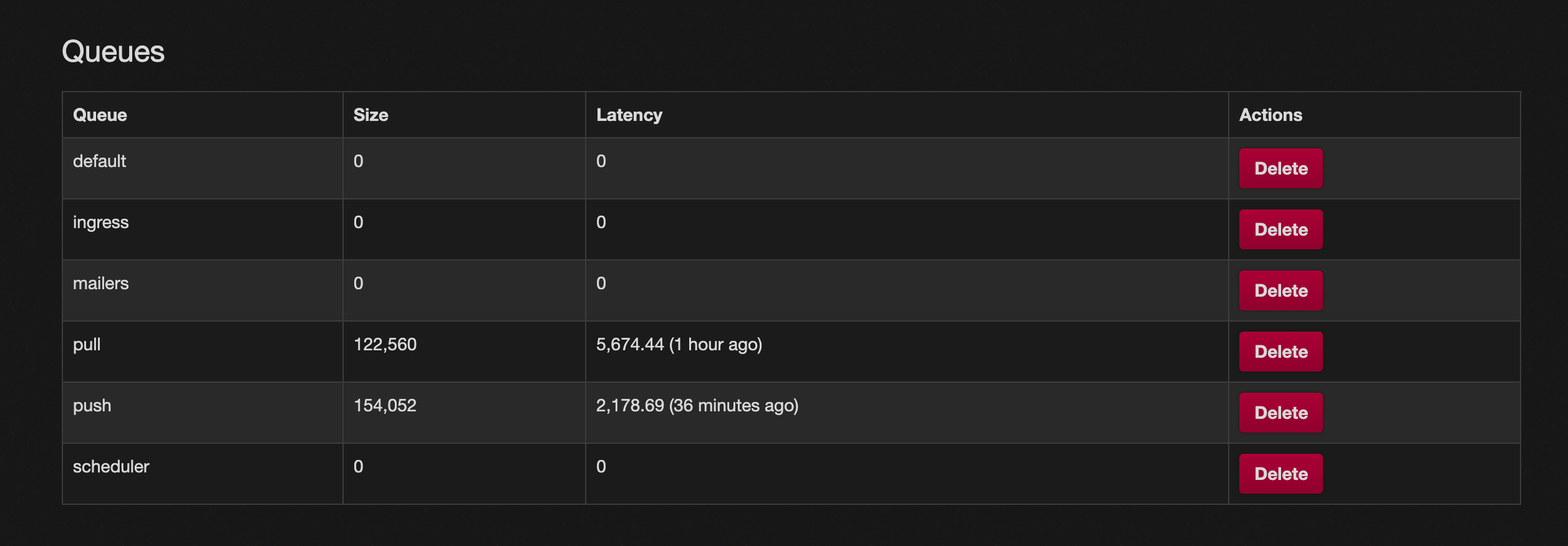

- Dec 18th 20:45
@hazelweaklyConfirms actively reloading services to drain queues - Dec 18th 21:17
@malte_jAppears from vacation, and is told to go back to relaxing - Dec 18th 21:23
@hazelweaklyContinues to “tweak and tune” the queues - Dec 18th 21:32
@hazelweaklyClaims we are growing at <1 user per minute - Dec 18th 21:45
@dmaReminder to only focus oningressanddefaultqueues - Dec 18th 21:47
@hazelweaklyIdentifies queue priority fix using systemd units - Dec 18th 21:47
@hazelweaklySuggests moving queues to CDN nodes - Dec 18th 21:59
@dmaSuggests migrating DB fromfreud->nietzsche - Dec 18th 22:15
@hazelweaklySummary confirms sidekiq running on CDNs - Dec 18th 22:18
@novaIdentifies conversation in Discord, and begins report
Root Cause
The cause of the caching 4XX responses and broken avatars was a misconfigured .env.production file on cdn-fremont-1 and franz.
S3_ENABLED=FALSE # Should be true
3_BUCKET=".." # Should be S3_BUCKET
The cause of the queue latency is suspected to be the increase in usage from Twitter, as well as the queue priority documented here in the official Mastodon scaling up documentation.
ExecStart=/usr/bin/bundle exec sidekiq -c 10 -q default
Things that went well
We have the cache media fixed, and we have been alerted to a high-risk concern early giving the team enough time to respond.
Things that went poorly
An outage was never declared for this incident, and therefore it was not handled as well as it could have been. Various members of the team were mutating production with reckless working habits
- Documenting informally in private infrastructure GitHub repository
- Discord used as documentation
- No documenting just “tinkering” alone
- Documenting after the fact
- Not using descriptive language, EG: “Tweaked the CDNs” instead of changed
on from to .
Unknown state of production after the incident. Unsure which services are running where, and who has what expectations for which services.
The configuration roll-out obviously had failed at some point, indicating a stronger need for config management on our servers.
We seemed to lose track of where the incident started and stopped and where improvements and action items began. For some reason we decided to make suggestions about next steps before we were entirely sure on the state of the systems today, and having a plan in place.
Opportunities
Config management should be a top priority.
Auditing and migrating sidekiq services off of CDN nodes should be a top priority.
Migrating the database from freud -> nietzsche should be a priority.
We shouldn’t be planning or discussing future improvements until the systems are restored to stability. Incidents are not also a venue for decision-making.
Resulting Action
1) Plan for Postgres migration
@nova and @hazelweakly planning live stream to migrate production database and clear up more compute power for sidekiq queues
2) TODO Configuration Management
We need to identify a configuration management pattern for our systems sooner than later. Perhaps an opportunity for a new volunteer.
3) TODO Discord Bot Incident Command
We need to identify ways of managing and starting and stopping incidents using Discord. Maybe in the future we can have “live operating room” incidents where folks can watch read-only during the action.
Global Outage: 504 Timeouts
On Tuesday, December 13th, 2022 at roughly 18:52 UTC Hachyderm experienced a 7 minute cascading failure that has impacted our users around the globe resulting in unresponsive HTTP(s) requests and 5XX level requests. The service has not experienced any data loss. We believe this was a total service outage.
Impacted users experienced 504 timeout responses from https://hachyderm.io in all regions of the world.
Timeline
All events are documented in UTC time.
- 18:53
@novaFirst report of slow response times in Discord - 18:55
@dmaFirst confirmation, and first report of 5XX responses globally - 18:56
@dmaCheck of Mastodon web services, no immediate concerns - 18:56
@novaCheck of CDN proxy services, no immediate concerns - 18:57
@novaFirst observed 504 timeout - 18:58
@dmastatus.hachyderm.io updated acknowledging the outage - 18:59
@novaFirst observed redis error, unable to persist to disk
Dec 13 18:59:01 fritz bundle[588687]: [2eae54f0-292d-488e-8fdd-5c35873676c0] Redis::CommandError (MISCONF Redis is configured to save RDB snapshots, but it's currently unable to persist to disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error.):
- 19:01
@UptimeRobotFirst alert received
Monitor is DOWN: hachyderm streaming
( https://hachyderm.io/api/v1/streaming/health ) - Reason: HTTP 502 - Bad Gateway
- 19:02
@novaRoot cause detected. The root filesystem is full on our primary database server.
- 19:04
@novaIdentified postgres archive/var/lib/postgres/archivedata exceeds 400Gb of history - 19:05
@malte_jRequest to destroy archive - 19:06
@malte_jConfirmed archive has been destroyed - 19:06
@malte_jConfirmed 187Gb of space has been recovered - 19:06
@dmastatus.hachyderm.io updated acknowledging the root cause - 19:07
@novaBegin drafting postmortem notes - 19:16
@novaOfficial announcement posted to Hachyderm
Root Cause
Full root filesystem on primary database server resulted in a cascading failure that first impacted Redis’s ability to persist to disk which later resulted in 5XX responses on the edge.
Things that went well
We had a place to organize, and folks on standby to respond to the incident.
We were able to respond and recover in less than 10 minutes.
We were able to document and move forward in less than 60 minutes.
Things that went poorly
There was confusion about who had access to update status.hachyderm.io and this is still unclear.
There was confusion about where redis lived, and which systems where interdependent upon redis in the stack.
The Novix installer is still our largest problem and is responsible for a lot of confusion. We do not have a better way forward to manage packages and configs in production. We need to decide on Nix and our path forward as soon as possible.
Opportunities
We need to harden our credential management process, and account management. We need to have access to our systems.
We need global architecture, ideally observed from the systems themselves and not in a diagram.
When an announcement is resolved, it removes the status entirely from UptimeRobot. We can likely improve this.
Resulting Action
1) Cron cleanup scheduled @malte_j
Cron scheduled to remove postgres archive greater than 5 days.
#!/bin/bash
set -e
cd /var/lib/postgres/data/archive
find * -type f -mtime 5 -print0 | sort -z | tail -z -n 1 | xargs -r0 pg_archivecleanup /var/lib/postgres/data/archive
2) Alerts configured @dma
Alerts scheduled for >90% filesystem storage on database nodes.
Postmortem template created for future incidents.
3) Postmortem documented @nova
This blog post as well as a small discussion in Discord.